
에이전트의 혼란: 내가 Postgres 컨트롤 플레인을 결정론적으로 유지하는 이유
작성자: Chris Chiappone 작성일: 2026년 3월 31일
우리는 ‘에이전트 시대’에 살고 있습니다. 매주 새로운 프레임워크가 등장합니다. 이들은 인프라를 자율적인 지능 계층으로 감싸주겠다고 약속합니다. 그 제안은 꽤 매력적입니다. 스크립트 작성은 멈추고 목표만 설정하라는 것입니다. ‘어떻게’ 할지는 AI가 알아서 하도록 놔두라고 말합니다.
하지만 최근 저는 장벽에 부딪혔습니다. Hybrid Manager로 관리되는 EDB Postgres AI 환경의 자동화를 설계하던 중이었습니다. 부하에 따라 클러스터를 자율적으로 확장하는 ‘에이전틱 DB(Agentic DB)’ 아키텍처를 구상하고 있었습니다. 그때 무언가 잘못되었다는 것을 깨달았습니다.
실제 요구사항을 들여다볼수록 ‘에이전트’ 패턴은 문제에 대한 억지 해결책처럼 느껴졌습니다. 핵심 데이터베이스 운영에 있어서는 오히려 퇴보하는 것 같았습니다.
이 글은 제가 왜 그 방향을 철회했는지에 대한 이야기입니다. 또한 Postgres를 위한 가장 강력한 아키텍처가 “모든 것을 에이전트에게 맡기는 것”이 아니라, 정책 우선(Policy-first), 에이전트 보조(Agent-assisted)인 이유를 설명합니다.
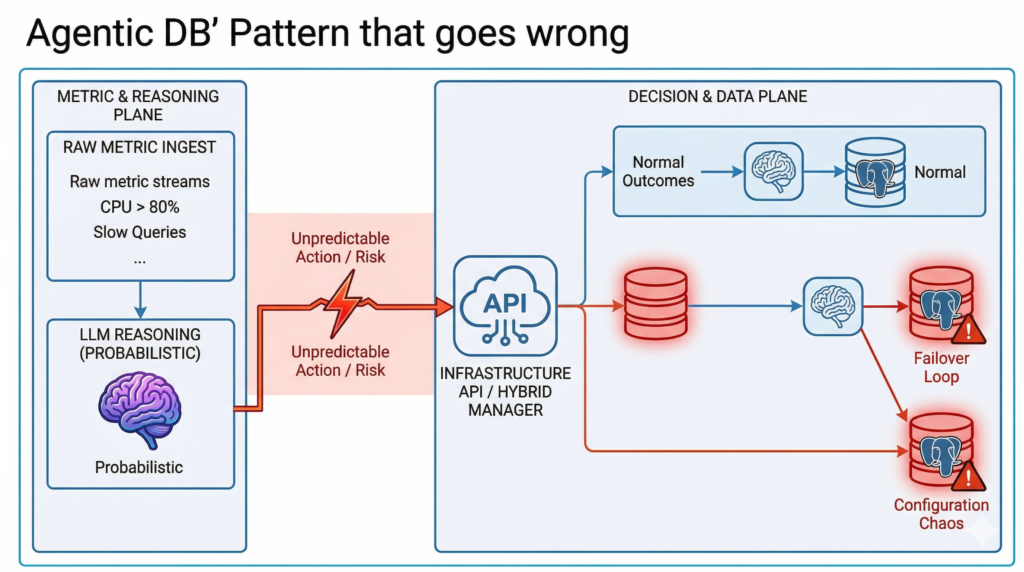
이미지 1: ‘에이전트의 망상(Agentic Delusion)’. 확률론적인 LLM 에이전트가 인프라 API를 직접 구동하는 순진한 아키텍처입니다. 이는 Postgres 환경에서 예측할 수 없는 확장 이벤트와 구성의 혼란을 초래합니다.
에이전트의 유혹
제가 처음에 구상했던 아키텍처는 꽤 최첨단으로 보였습니다. 저는 다음과 같은 시스템을 원했습니다.
- CPU 및 메모리 지표(Metrics) 수집
- 사용률 ‘평가’
- Hybrid Manager API 호출
- 클러스터 확장
이론적으로 이는 LLM의 완벽한 사용 사례입니다. 에이전트에게 지표와 API 접근 권한을 줍니다. “클러스터 성능을 유지하라”는 프롬프트를 작성합니다. 그리고 에이전트가 스스로 추론하여 해결책을 찾도록 놔둡니다.
하지만 에이전트가 ‘추론’해야 할 실제 로직을 살펴봤습니다.
Plaintext
IF cpu_avg > 80% for 10 minutes AND cooldown_expired AND not currently scaling THEN increase instance tier by 1
이것은 모호한 추론이 아닙니다. 명확한 결정론적 정책(Deterministic policy)입니다.
여기에는 어떤 미묘한 뉘앙스도 없습니다. 도구 선택이나 다단계 계획이 필요하지 않습니다. 확률론적 해석도 불필요합니다. 이 작업을 에이전트에게 위임한다고 해서 시스템이 더 똑똑해지는 것이 아니었습니다. 단지 확률론적(Probabilistic)으로 변할 뿐이었습니다. 저는 단순한 ‘if/then’ 문이라는 닫힌 형태(Closed-form)의 제어 문제에 LLM의 혼돈을 주입하고 있었던 것입니다.
프로덕션 환경에서 비결정성이 초래하는 비용
확장 로직의 본질을 깨닫고 나니, ‘에이전틱’ 접근 방식의 위험성을 더 이상 무시할 수 없었습니다.
프로덕션 Postgres 환경에서는 결정성(Determinism)이 절대적으로 필요합니다. 클러스터를 확장한다면 정확한 이유와 시간을 알아야 합니다. 어떤 전제 조건이 있었는지도 명확해야 합니다.
에이전트는 변동성을 유발합니다. 프롬프트 문구에 따라 다른 모델 버전이 “80%” 임계값을 다르게 해석할 수 있습니다. 시스템 프롬프트를 약간만 업데이트해도 에이전트의 위험 허용 범위가 바뀔 수 있습니다. 에이전트가 확장을 결정했는데 문제가 발생하면, 사후 분석(Post-mortem)은 악몽이 됩니다. 코드를 디버깅하는 대신 AI의 ‘사고 과정’을 디버깅해야 하기 때문입니다.
인프라 제어 경로(확장, 페일오버, 구성 변경 등)에서는 제어 루프의 ‘지능(Intelligence)’ 부분이 불필요할 뿐만 아니라 오히려 위험 요소(Liability)라는 사실을 깨달았습니다.
영향 반경(Blast Radius)과 감사 추적(Audit Trail)
권한의 문제도 짚고 넘어가야 합니다.
에이전트에게 patch_cluster, 페일오버 엔드포인트 또는 직접적인 SQL 실행 권한을 부여한다고 가정해 봅시다. 이는 ‘영향 반경’의 개념을 제대로 이해하지 못하는 시스템에게 프로덕션 환경의 마스터키를 넘겨주는 것과 같습니다.
물론 제한을 둘 수는 있습니다. “한 번에 한 계층만 확장하라” 또는 “실패한 도구 호출을 재시도하지 마라”와 같은 프롬프트를 작성할 수 있습니다. 하지만 이는 제안일 뿐, 강력한 보장(Guarantees)이 아닙니다.
이를 결정론적 컨트롤러 루프와 비교해 보십시오. 코드에서는 다음과 같은 엄격한 경계를 강제할 수 있습니다.
- 명시적인 클러스터 범위 지정
- 엄격한 계층 제한
- 강제적인 쿨다운(Cooldown) 시간 적용
- 주기당 단일 작업 실행 보장
이러한 보장은 프롬프트가 아닌 컴파일러에 의해 강제됩니다.
컴플라이언스를 위한 필수 조건: 구조화된 로그
컴플라이언스(Compliance)는 어떨까요? 엔터프라이즈 Postgres 환경은 감사 가능성(Auditability)을 요구합니다. 결정론적 스케일러는 깔끔하고 구조화된 로그를 생성합니다.
Plaintext
cpu_avg=84.3; threshold=80; action=patch_cluster; target=large
반면 에이전트 기반 시스템은 복잡한 계층을 추가합니다. 프롬프트 버전, 모델 버전, 컨텍스트 메모리 상태, 도구 추론 추적이 모두 포함됩니다. 감사자가 “왜 이 변경이 발생했습니까?”라고 물을 때, LLM의 500줄짜리 사고 과정을 건네주는 것은 결코 그들을 만족시킬 수 없습니다.
방향 전환: 에이전트의 진짜 자리
그렇다면 Postgres에서 에이전트는 무용지물일까요? 절대 그렇지 않습니다. 문제는 에이전트의 사용 자체가 아니었습니다. 에이전트를 실행(Execution) 계층에 적용한 것이 문제였습니다.
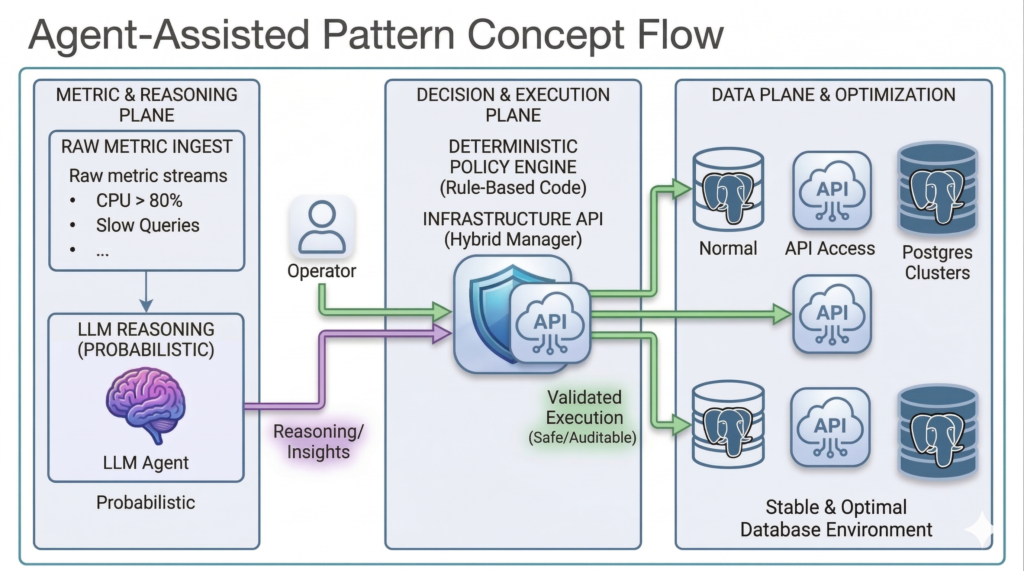
이미지 2: 제어보다 추론(Reasoning Over Control). 확률론적 LLM 에이전트(보라색)를 분석 및 인사이트 도출에만 활용하는 올바른 아키텍처입니다. 여기서 도출된 정보는 강력한 결정론적 정책 엔진(파란색 방패)으로 전달되어, 안정적인 Hybrid Manager API를 통해 실행되기 전에 엄격한 규칙에 따라 모든 작업을 검증합니다.
저는 아키텍처를 뒤집어야 함을 깨달았습니다. 에이전트는 제어에는 형편없지만, **추론(Reasoning)**에는 탁월합니다. 에이전트가 데이터베이스를 직접 통제하게 두는 대신, 데이터베이스를 **관찰(Watch)**하도록 역할을 변경했습니다.
에이전트가 빛을 발하는 3가지 핵심 영역
1. 장애 대응(Incident Triage) CPU 스파이크가 발생하면 정적 스크립트는 단순한 알림을 보냅니다. 하지만 에이전트는 다릅니다. 느린 쿼리 로그를 가져오고, 락(Lock) 테이블을 확인하며, 복제 지연을 분석합니다. 최근 스키마 변경 사항을 교차 참조할 수도 있습니다. 그리고 *”스파이크는 사용자 테이블의 새 인덱스 생성과 관련이 있습니다”*라는 확률 높은 가설 목록을 제시합니다. 이것이 바로 고부가가치 추론입니다.
2. 쿼리 최적화(Query Optimization) EXPLAIN ANALYZE를 해석하는 것은 일종의 예술입니다. 에이전트는 여기서 부조종사(Copilot)로서 탁월한 능력을 발휘합니다. 인덱스 전략을 제안하거나 비효율적인 SQL을 다시 작성합니다. 이는 자문 역할이므로 안전하며, 모델의 의미론적 이해력을 십분 활용합니다.
3. 교차 시스템 오케스트레이션(Cross-System Orchestration) PagerDuty 티켓이 발생하면 에이전트는 Hybrid Manager에서 지표를 가져옵니다. 벡터 저장소에서 관련 런북(Runbook)을 찾고, 조치 계획을 초안하여 Slack에 게시합니다. 서로 다른 시스템 간의 점들을 연결하는 것입니다. 단지 “실행” 버튼을 누르는 주체가 되어서는 안 될 뿐입니다.

이미지 3: 감사 추적 비교. 왼쪽(확률론적)은 감사하기 어려운 혼란스럽고 구조화되지 않은 추론 추적을 생성합니다. 오른쪽(결정론적, 이미지 2에 사용됨)은 컴플라이언스에 적합한 깔끔하고 구조화된 순차적 로그를 생성합니다.
성숙한 아키텍처: 제어보다 추론
이러한 과정을 거쳐 저는 최종 아키텍처를 완성했습니다. 이것은 불안정한 ‘에이전틱 DB’가 아닙니다. 통제력을 엄격하게 유지하는 하이브리드 모델입니다.
Plaintext
[에이전트 계층] → [결정론적 정책 엔진] → [Hybrid Manager API] 분석(Analyze) 결정 및 검증(Decide) 실행(Execute)
에이전트 계층(Agent Layer)은 최상단에 위치합니다. 데이터를 살펴보고 상태를 요약하며 이상 징후를 설명하고 조치를 권장합니다. “CPU가 높으니 확장을 고려해 보세요”라고 제안하는 역할입니다.
결정론적 정책 엔진(Deterministic Policy Engine)은 중간에 위치합니다. 해당 권장 사항(또는 지표 임계값)을 바탕으로 엄격한 로직을 적용합니다. 쿨다운을 확인하고 전제 조건을 검증하며 영향 반경이 제한되어 있는지 확인합니다. 최종 결정을 내리는 것은 바로 이 엔진입니다.
실행 계층(Execution Layer)은 실제 작업을 수행합니다. Hybrid Manager에 제한된 API 호출을 수행하고 그 결과를 로그로 기록합니다.
이 모델은 두 세계의 장점을 모두 제공합니다. 확률론적 시스템에 통제권을 넘기지 않으면서도 LLM의 지능과 통찰력을 완벽하게 활용할 수 있습니다.
실용적인 시사점
업계는 모든 것을 에이전트로 감싸려고 서두르고 있습니다. 하지만 프로덕션 환경에서 Postgres를 운영하는 우리들은 더 안목을 가져야 합니다.
작업이 제어 문제(Control problem)라면, 즉 인프라를 직접 수정하는 일이라면 스크립트와 상태 머신(State machine)을 사용하십시오. 철저히 결정론(Determinism)을 따르십시오.
작업이 추론 문제(Reasoning problem)라면, 즉 분석, 종합, 의사소통이 필요하다면 에이전트(Agent)를 사용하십시오.
우리의 목표는 에이전트를 피하는 것이 아닙니다. 에이전트의 강점이 가장 잘 빛나는 곳에 그들을 배치하는 것입니다. 결정론적 엔진이 차를 도로 위에서 안전하게 주행시키는 동안, 에이전트는 조수석에 앉아 훌륭한 내비게이션 역할을 하도록 만드십시오.
메일: salesinquiry@enterprisedb.com
