
PostgreSQL 고가용성(HA): 아키텍처와 3가지 실전 패턴 비교
닉 이바노프
2025년 1월 28일
데이터베이스 솔루션 아키텍처를 설계할 때, 불필요한 복잡성과 비용을 방지하면서도 모든 비즈니스 요구 사항을 충족할 수 있도록 향후 기능과 비즈니스 요구 사항을 신중하게 고려하는 것이 매우 중요합니다. 특히 고가용성을 갖춘 데이터베이스 시스템을 설계할 때는 더욱 그렇습니다.
IT에서 고가용성(HA)은 일반적으로 핵심 구성 요소의 중복성을 제공함으로써 달성되며, 가급적이면 이러한 구성 요소가 드물게 사용되더라도 시스템이 필요한 수준의 복원력을 제공할 수 있도록 아키텍처를 설계하는 것이 중요합니다.
고가용성이란?
고가용성(HA)은 시스템이 구성 요소 장애 발생 시에도 운영을 유지하고 접근이 가능하도록 하는 능력을 의미합니다. 데이터베이스의 경우, 계획된 유지보수 및 예상치 못한 장애 발생 시에도 데이터 접근성을 유지할 수 있도록 전략을 수립하는 것을 의미합니다.
데이터베이스 솔루션의 가용성을 정의하는 두 가지 주요 지표가 있습니다.
- 복구 시간 목표(RTO, Recovery Time Objective)
- 데이터베이스 시스템이 얼마나 오랫동안 오프라인 상태를 유지할 수 있는지를 결정하는 지표입니다. 이는 데이터베이스를 운영 상태로 복구하는 데 필요한 시간을 의미합니다.
- 복구 시점 목표(RPO, Recovery Point Objective)
- 장애 발생 시 복구된 데이터베이스 스냅샷이 얼마나 과거 시점으로 돌아갈 수 있는지를 결정하는 지표입니다. 즉, 장애가 발생하기 전에 허용 가능한 데이터 손실량을 의미합니다.
- RPO가 ‘0’이면, 애플리케이션이 커밋한 트랜잭션이 절대로 손실되지 않음을 의미합니다.
이 두 지표를 ‘0’에 가깝게 조정할수록 솔루션 아키텍처의 비용과 복잡성이 증가하므로, 비즈니스 목표와의 균형을 신중하게 고려해야 합니다.
PostgreSQL은 고가용성을 지원하는 기본적인 메커니즘을 제공하며, 아래에서 설명할 다양한 고가용성 아키텍처의 기반이 됩니다.
용어 정리
클러스터 (Cluster)
전통적으로 PostgreSQL에서 클러스터라는 용어는 하나의 PostgreSQL 프로세스가 관리하는 하나 이상의 데이터베이스 모음을 의미합니다. 이는 **PostgreSQL 인스턴스(Instance)**라고도 합니다.
그러나 고가용성(HA) 환경에서는 클러스터가 여러 개의 중복된 PostgreSQL 인스턴스와 장애 조치(failover) 관리 프로세스 등 관련 구성 요소가 포함된 고가용성 데이터베이스 솔루션을 의미합니다.
이 문서에서는 혼란을 방지하기 위해 **후자의 의미로 “클러스터”**라는 용어를 사용하며, 전자의 개념은 **”인스턴스”**라고 지칭하겠습니다.
노드 (Node)
클러스터의 노드는 고가용성 솔루션의 하나 이상의 소프트웨어 구성 요소가 실행되는 **단일 서버(물리 또는 가상 서버)**를 의미합니다.
일반적으로 노드는 PostgreSQL 인스턴스를 호스팅하지만, 항상 그런 것은 아닙니다. 예를 들어, 일부 솔루션에서는 Barman 백업 소프트웨어와 같은 특정 역할을 수행하는 전용 노드를 포함할 수도 있습니다.
위치 (Location)
클러스터의 노드는 하나 이상의 지리적 위치에 배포될 수 있습니다. 예를 들어:
- 클라우드 제공업체의 가용 영역(AZ, Availability Zone) 또는 리전(Region)
- 실제 데이터센터(DC, Data Center)
지리적으로 분산된 데이터베이스 클러스터는 지역 기반 인프라 장애 및 재해에 대한 복원력을 제공하지만, 설정 및 유지 관리가 더 복잡할 수 있습니다. 재해 복구 전략에 맞는 적절한 설계를 선택하는 것이 중요합니다.
위트니스 (Witness)
위트니스(또는 타이브레이커, Tiebreaker)는 짝수 개의 데이터베이스 노드를 가진 클러스터에서 복제본을 승격(promote)하는 결정을 내릴 때 정족수를 확보하기 위해 필요한 노드입니다.
대부분의 장애 조치 클러스터링 솔루션에서는 노드 과반수의 동의가 필요합니다.
만약 클러스터가 짝수 개의 노드로 구성되어 있고, 그중 절반이 장애를 일으키면 과반수를 달성할 수 없기 때문에 승격 결정이 불가능해집니다. 이를 방지하기 위해 추가적인 위트니스 노드가 필요합니다.
PostgreSQL에서 고가용성 달성하기
1. 시점 복구(Point in Time Recovery, PITR)
백업을 이용한 **시점 복구(PITR)**는 요구되는 RTO(복구 시간 목표) 및 **RPO(복구 시점 목표)**를 충족할 경우 고가용성 전략의 일부로 활용될 수 있습니다.
이 방법은 장애 발생 시 백업본을 복원하고, 보관된 WAL(Write-Ahead Logging) 파일을 재적용하여 원하는 시점까지 복구하는 방식입니다. 따라서 복구 시간은 데이터베이스 크기 및 처리해야 할 WAL 파일 개수에 따라 결정됩니다.
복구 가능한 시점은 WAL 파일이 보관되는 빈도에 따라 달라집니다. 변경이 적은 데이터베이스나 일정 시간의 다운타임을 허용할 수 있는 애플리케이션에서는 PITR이 적절한 고가용성 옵션이 될 수 있습니다.
2. 복제(Replication)
PostgreSQL은 물리적 복제(Physical Replication)와 논리적 복제(Logical Replication)라는 두 가지 기본적인 복제 방식을 제공합니다.
**EDB Postgres Distributed(PGD)**는 기본적인 PostgreSQL 논리적 복제를 확장하여 다중 방향(active-active) 복제를 지원하고, 엔터프라이즈급 기능을 추가하여 고가용성(HA) 애플리케이션에 적합하도록 설계되었습니다.
PostgreSQL의 기본 복제 방식은 비동기(asynchronous) 복제입니다. 즉, 기본(primary) 노드가 장애를 일으키기 전에 모든 트랜잭션이 복제본(replica)에 반영되었는지 보장되지 않습니다. 하지만, 동기(synchronous) 복제를 설정하면 트랜잭션이 복제본에 확실히 적용될 때까지 완료되지 않도록 설정할 수 있습니다.
동기 복제(Synchronous Replication) 사용 시:
- **RPO(복구 시점 목표)**를 거의 0에 가깝게 설정 가능
- 하지만 데이터베이스 트랜잭션 처리 속도 감소라는 비용이 발생
각 복제 방식은 장단점이 있으며, 특정한 사용 사례에 따라 적절한 방식을 선택해야 합니다.
물리적 복제(Physical Replication)
작동 방식
- 기본(primary) 서버의 WAL(Write-Ahead Log) 기록을 복제본(replica) 서버로 전달
- PostgreSQL 인스턴스의 모든 데이터베이스가 동일한 WAL 파일을 공유하므로, 전체 데이터베이스가 복제됨
- 물리적 복제는 두 가지 방법으로 구현 가능하며, 지원하는 RPO가 다름
- 로그 배송(Log Shipping)
- 기본 서버가 주기적으로 WAL 파일을 공유된 위치(shared location)에 저장
- 복제본이 해당 WAL 파일을 가져와 트랜잭션을 재생(replay)
- RPO는 WAL 파일 보관 빈도에 따라 달라짐
- 스트리밍 복제(Streaming Replication)
- 복제본이 기본 서버와 지속적인 연결을 유지
- 트랜잭션이 커밋되면 WAL 로그가 실시간으로 전달됨
- 보다 낮은 RPO를 제공
- 로그 배송(Log Shipping)
장점
✅ 설정이 간단함 – 최소한의 설정 단계로 복제 가능
✅ 데이터뿐만 아니라 테이블 구조(스키마)도 복제 가능
✅ 고성능 – 논리적 복제보다 더 빠르고 효율적일 수 있음
✅ 기본 서버의 부담이 적음 – 낮은 오버헤드
단점
❌ 유연성이 낮음 – 데이터 필터링/변환이 불가능
❌ 버전 호환성 문제 – 기본 및 복제본 서버에서 동일한 PostgreSQL 주요 버전이 필요
❌ 읽기 전용 복제본 – 주로 고가용성 및 재해 복구(Disaster Recovery) 용도로 사용됨
논리적 복제(Logical Replication)
작동 방식
- 특정 테이블 또는 데이터베이스의 논리적 변경 사항(INSERT, UPDATE, DELETE)을 캡처
- 변경 사항을 데이터 변경 명령(DML) 시퀀스로 전송
장점
✅ 유연성 – 특정 테이블만 복제 가능하며, 데이터 필터링 및 변환 가능
✅ 버전 호환성 – 서로 다른 PostgreSQL 주요 버전 간에도 복제 가능
✅ 읽기-쓰기 복제본 지원 – 복제본에서 데이터 변경(쓰기) 가능
단점
❌ 기본 서버의 CPU/메모리 사용량 증가
❌ 복제본에서 데이터 충돌 발생 가능성
❌ 테이블 스키마 변경(DDL)은 자동 복제되지 않음
❌ PostgreSQL 기본 논리 복제만으로는 강력한 고가용성 구현이 어려움
EDB Postgres Distributed (PGD)
작동 방식
- PostgreSQL 논리적 복제를 확장하여 다중 방향(active-active) 복제 지원
- DDL(스키마 변경) 복제, 데이터 충돌 해결 기능, 데이터 일관성 강화 등 추가 기능 제공
기본 논리 복제 대비 장점
✅ 스키마 변경(DDL) 복제 지원
✅ 데이터 충돌 방지 및 해결 기능 제공
✅ 데이터 일관성 향상
언제 어떤 방식을 사용해야 할까?
| 사용 사례 | 권장 복제 방식 |
|---|---|
| 고가용성(HA) 및 장애 복구 | 물리적 복제 |
| 읽기 전용(replica) 부하 분산 | 물리적 복제 |
| 데이터 분석 및 데이터 웨어하우징 | 논리적 복제 |
| 다중 지역 데이터 분산 | 논리적 복제 |
| 테스트 및 개발 환경 | 논리적 복제 |
| 데이터 통합 | 논리적 복제 |
| 고급 기능이 필요한 HA 환경 | EDB Postgres Distributed |
각 옵션은 특정한 **RTO(복구 시간 목표) 및 RPO(복구 시점 목표)**를 달성하는 데 도움을 줄 수 있습니다.
아래 다이어그램은 각 방법이 이러한 목표를 달성하는 데 있어서의 상대적인 성능을 보여줍니다.
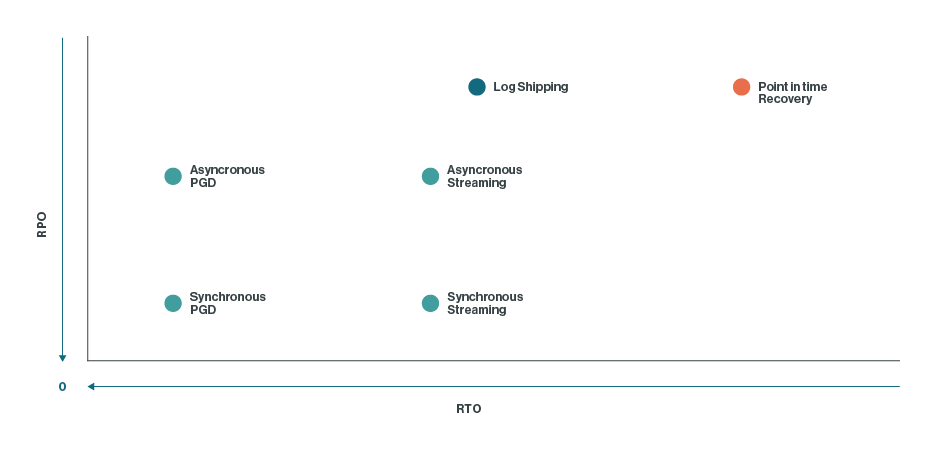
3. 장애 조치 클러스터(Failover Clustering)
중요한 애플리케이션에서는 **장애 조치 클러스터(Failover Cluster)**를 구축하여 **고가용성(HA)**을 보장할 수 있습니다.
- EDB Failover Manager, Patroni, repmgr 등의 도구를 활용하면 기본(primary) 서버 장애 발생 시 자동으로 복제본(standby)을 승격(promote)하여 운영을 지속할 수 있습니다.
- 이러한 도구를 사용하면 클러스터 관리가 간소화되며, 장애 조치 과정의 복잡성을 줄일 수 있습니다.
**EDB Postgres Distributed(PGD)**는 장애 조치 기능을 기본적으로 포함하고 있으며, 추가적인 장애 조치 도구를 설정할 필요 없이 자동으로 장애 조치를 수행할 수 있습니다.
4. 로드 밸런싱(Load Balancing)
로드 밸런싱은 데이터베이스 요청을 여러 서버에 분산하여 성능을 향상시키고 가용성을 유지하는 중요한 기술입니다.
- 한 서버가 다운되더라도 다른 서버가 트래픽을 처리할 수 있도록 보장합니다.
- HAProxy와 같은 도구를 활용하여 연결을 효과적으로 관리할 수 있으며, 특히 장애 조치(Failover) 관리 솔루션과 함께 사용하면 더욱 효과적입니다.
5. 백업 및 복구(Backup and Recovery)
정기적인 백업은 고가용성 전략의 핵심 요소입니다. PostgreSQL은 다음과 같은 다양한 백업 방법을 지원합니다.
- 물리적(Physical) 및 논리적(Logical) 백업
- 파일 시스템 또는 스토리지 장치 레벨에서의 스냅샷(Snapshots)
특히 시점 복구(PITR, Point-in-Time Recovery) 기능과 결합하면 장애나 사용자 실수로 인해 데이터가 손실되었을 경우 특정 시점으로 복구할 수 있습니다.
- Barman 및 pgBackRest와 같은 도구를 활용하면 WAL(Write-Ahead Logging) 파일 및 데이터베이스 백업을 효율적으로 관리할 수 있으며, 백업 및 복구 작업을 자동화할 수 있습니다.
6. 연결 풀링(Connection Pooling)
연결 풀링(Connection Pooling) 도구를 사용하면 데이터베이스 성능을 최적화하고, 장애 발생 시 빠르게 대응할 수 있습니다.
- PgBouncer 및 Pgpool-II 같은 도구는 데이터베이스 연결을 재사용하여 성능을 최적화하며,
- 장애 조치 발생 후 애플리케이션 연결을 새로운 기본(primary) 서버로 자동으로 전환할 수 있습니다.
- 이를 통해 새로운 연결 요청으로 인해 데이터베이스가 과부하 상태에 빠지는 것을 방지하고, 시스템의 복원력을 향상시킬 수 있습니다.
고가용성(HA) 구현을 위한 모범 사례
모니터링 및 알림(Monitoring and Alerts)
데이터베이스 성능을 정기적으로 모니터링하고, 장애 발생 시 즉시 대응할 수 있도록 알림 시스템을 설정하세요.
Postgres Enterprise Manager, Prometheus, Grafana 등의 도구를 활용하면 중요한 지표를 추적하고, 데이터베이스 상태를 분석하며, 이상 상황 발생 시 신속하게 알림을 받을 수 있습니다.
장애 조치(Failover) 절차 테스트
장애 조치 절차를 정기적으로 테스트하여, 예상대로 동작하는지 확인하세요.
장애 시나리오를 시뮬레이션하면 HA 전략의 취약점을 사전에 파악하고 보완할 수 있습니다.
문서화(Documentation)
고가용성(HA) 설정 및 표준 운영 절차를 명확하게 문서화하세요.
문서화된 자료는 문제 발생 시 신속한 대응을 가능하게 하며, 수동 개입이 필요한 경우에도 복구 시간을 단축하는 데 도움을 줍니다.
샘플 아키텍처 패턴(Sample Architecture Patterns)
PostgreSQL 고가용성(HA) 솔루션을 구현할 때 사용할 수 있는 소프트웨어 구성 요소의 종류가 많고, 비즈니스 요구 사항 및 외부 요인이 아키텍처 설계에 영향을 미치므로, 이 문서에서 모든 가능한 아키텍처 옵션을 상세히 설명하는 것은 현실적으로 어렵습니다.
따라서, 여기에서는 일반적으로 활용할 수 있는 몇 가지 샘플 아키텍처를 제공하여, 여러분이 고가용성 솔루션을 연구하고 설계하는 데 도움이 될 수 있도록 하였습니다.
아키텍처 패턴 선택 기준
아래에서 설명하는 각 아키텍처 패턴은 **PostgreSQL 물리적 복제(Physical Replication) 또는 EDB Postgres Distributed(PGD)**를 사용하여 구현할 수 있습니다.
기술 선택은 각 제품에서 제공하는 기능 차이뿐만 아니라, 비용 고려사항 및 시스템 복잡성에 대한 허용 범위 등 기술 외적인 요소에도 영향을 받습니다.
우리는 각 아키텍처 패턴을 기본적인 배포 방식에 따라 분류하며, 이 분류는 배포 위치의 수와 클러스터 노드 수를 기준으로 합니다.
1. One by Three (1×3) 아키텍처
이 아키텍처는 단일 배포 위치(one location)에 3개의 클러스터 노드를 배포하는 방식입니다.
아래 그림과 같이 구성됩니다.
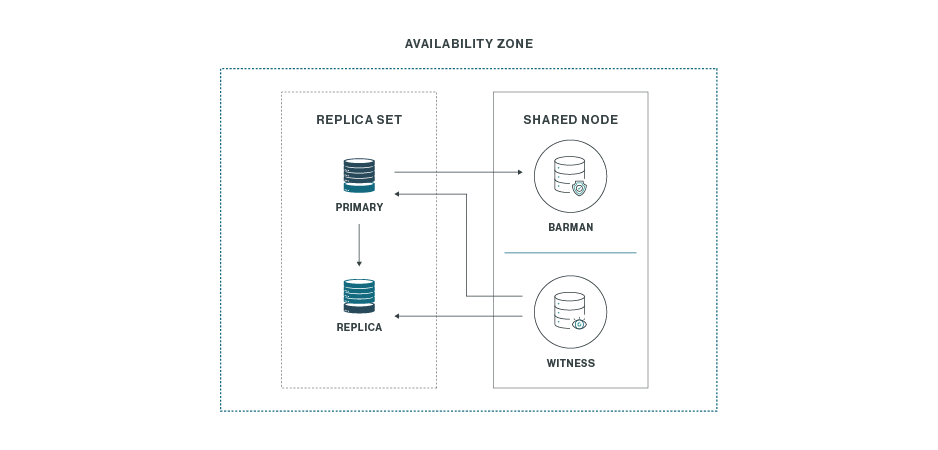
이 특정 예제에서 클러스터는 Primary 노드와 Primary 노드, 단 두 개의 데이터베이스 노드만 포함합니다.
세 번째 노드는 다음 두 가지 구성 요소를 공유합니다.
- 장애 조치(Failover) 관리 소프트웨어
- 증인(Witness) 또는 타이브레이커(Tiebreaker) 역할 수행
- Primary 노드 장애 발생 시, 복제본 자동 승격(Promotion)
- Barman 백업 및 복구 소프트웨어
- 데이터베이스 백업 및 복구 관리
이 아키텍처는 가장 경제적인 고가용성 솔루션입니다.
유료 라이선스가 필요할 가능성이 있는 구성 요소가 단 2개(두 개의 데이터베이스 서버)만 포함되어 있고 가장 작은 인프라 규모를 유지하면서도 단일 데이터 노드 장애로부터 보호가 가능합니다.
그러나 이 아키텍처는 배포 위치 전체의 장애(Location Failure)로부터 보호하지 않으며, 특히 백업 사본이 다른 위치에 저장되지 않는 경우 복구가 어렵습니다.
2. One by Three Plus One(1×3+1) 아키텍처
이 패턴은 앞서 설명한 1×3 아키텍처를 확장하여, **재해 복구(Disaster Recovery, DR)**를 위한 추가적인 배포 위치를 포함합니다. 아래 그림과 같이 구성됩니다.
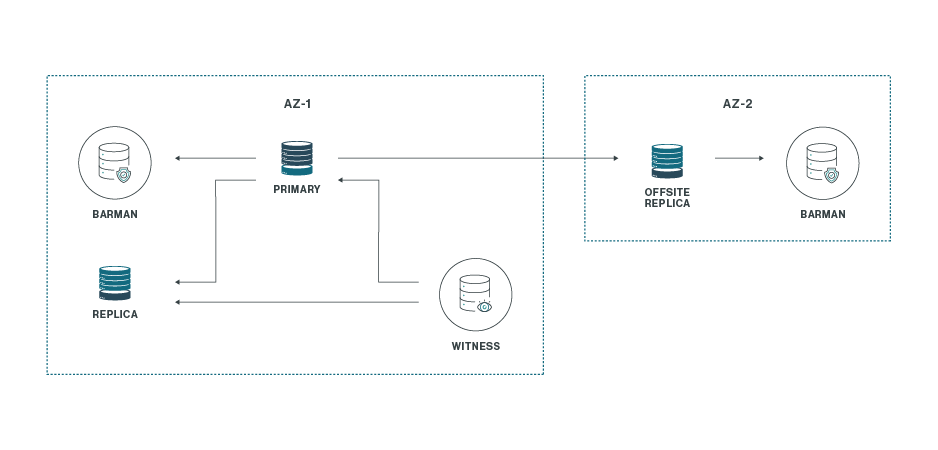
이 구성에서는 기본(primary) 위치가 완전히 손실되더라도 운영을 지속할 수 있습니다.
그러나 생존한 원격 복제본(offsite replica)은 정족수(quorum) 부족으로 인해 자동 승격되지 않습니다.
따라서 수동 개입(Manual Intervention)이 필요하며, 가능하다면 새로운 배포 위치를 확장하여 완전한 1×3 구성으로 복구해야 합니다.
3. Two by Three Plus One(2×3+1) 아키텍처
이 아키텍처는 **EDB Postgres Distributed(PGD)**를 활용하여 최상의 고가용성(HA) 및 재해 복구(DR) 기능을 제공합니다.
- 단일 노드 장애에도 자동 복구 가능
- 기본(primary) 위치가 전체적으로 손실되더라도, 거의 즉각적으로 완전 자동 복구 수행 가능
핵심 기능
이러한 완전 자동 재해 복구(Automatic Disaster Recovery) 기능은
세 번째 배포 위치에 존재하는 “위트니스(Witness)” 노드 덕분에 가능합니다.
- 위트니스 노드는 데이터를 저장하지 않지만, 장애 조치(Failover) 시 결정적인 타이브레이커(Tiebreaker) 역할을 수행합니다.
- 이를 통해 가용 영역(AZ) 간 자동 장애 조치가 투명하게 이루어질 수 있습니다.
비용 및 복잡성 고려 사항
이 아키텍처는 최대 수준의 가용성과 즉각적인 복구 속도를 보장하지만,
이는 여러 개의 중복 데이터베이스 노드를 유지해야 하는 비용과 복잡성 증가를 동반합니다.
본문: PostgreSQL High Availability Basics: Understanding Architecture and 3 Common Patterns
이메일: salesinquiry@enterprisedb.com

