
RAG(검색 증강 생성)앱과 PostgreSQL: pgvector로 성능 향상하기
EDB 팀
2024년 10월 08일
RAG(검색 증강 생성) 앱은 현재 매우 인기가 있으며, 저희는 Postgres와 pgvector를 사용하여 독점적으로 앱을 개발하기로 결정했습니다. 이 블로그 게시물에서는 RAG가 무엇인지에 대해 조금 이야기하고, RAG 앱을 처음부터 구축하는 방법을 세분화하고, RAG 앱 구축의 기본 요소를 공유하고, 그 과정에서 유용한 몇 가지 팁을 제공하겠습니다.
모든 코드는 GitHub에서 사용할 수 있으며, 앱이 어떻게 작동하는지 보여드리기 위해 앱을 실행하는 화면도 녹화해 두었습니다.
검색 증강 생성, 즉 RAG란 무엇인가요?
검색 증강 생성(RAG)은 언어 모델(LLM) 애플리케이션을 더 스마트하게 만드는 데 선호되는 방법이 되었습니다. 이는 LLM이 일반적으로 알지 못하는 자체 데이터를 추가함으로써 달성할 수 있습니다.
RAG는 기존의 언어 생성 모델과 Postgres와 같은 데이터베이스에서 자체 데이터를 사용하는 등의 검색 기반 방법을 결합하여 생성된 텍스트의 품질과 관련성을 향상시킵니다. 질문이나 작업에 대한 관련 데이터를 수집하여 LLM의 컨텍스트로 포함합니다. 검색 단계와 추가 컨텍스트를 통합함으로써 RAG는 생성된 텍스트의 일관성, 정확성 및 구체성을 개선하여 질문 답변, 요약 및 대화 작성과 같은 작업에 특히 유용합니다.
이러한 모든 단계를 통해 LLM이 주제를 더 깊이 이해하게 되므로 더 스마트하게 만들 수 있습니다. RAG는 또한 생성된 답변에서 ‘환각’으로 알려진 부정확성을 방지하는 것으로 알려져 있습니다.
RAG 파인튜닝
RAG는 일반적인 데이터셋에서 훈련되지만, 특정 도메인이나 애플리케이션에 맞게 성능을 향상시키기 위해 파인튜닝이 필요합니다. 이를 통해 RAG 모델이 특정 요구사항에 더 잘 맞춰질 수 있으며, 사용자에게 더 정확하고 유용한 결과를 제공할 수 있습니다. RAG의 오픈소스는 비용 효율적이며, 커스터마이징이 가능하고, 커뮤니티의 지원을 받을 수 있어 지속적으로 발전할 수 있습니다.
파인튜닝 방법:
- 1. 데이터 준비: 특정 도메인에 맞는 데이터셋을 수집하고 전처리합니다.
- 2. 모델 훈련: 기존 RAG 앱을 가져와서 새로운 데이터셋으로 추가 훈련을 진행합니다. 이 과정에서 하이퍼파라미터 조정이 필요할 수 있습니다.
- 3. 검증 및 평가: 파인튜닝 후 모델의 성능을 검증하고, 필요에 따라 추가적인 조정을 합니다.
파인튜닝 장점:
- 1. 성능 향상: 특정 도메인이나 애플리케이션에 맞게 모델의 성능을 향상시킬 수 있습니다.
- 2. 맞춤형 결과 제공: RAG가 특정 요구사항에 더 잘 맞춰져 사용자에게 정확하고 유용한 결과를 제공합니다.
- 3. 유연성 증가: 다양한 산업에서 활용 가능성을 높여 RAG의 유연성을 보여줍니다.
파인튜닝은 RAG 앱의 기본 성능을 개선하는 방법으로, RAG는 검색과 생성의 결합을 통해 더 나은 결과를 도출할 수 있습니다.
앱 개발 동기
지난 몇 달 동안 저는 다양한 컨퍼런스와 밋업에서 pgvector에 대해 발표하고 Postgres와 pgvector의 잠재력을 탐구하고자 하는 고객들과 소통해 왔습니다. 이들 중 다수는 도메인별 지식을 활용하는 챗봇 스타일의 애플리케이션을 개발하기 위해 자신의 데이터를 LLM에 통합하는 데 관심이 있습니다.
저는 이들의 요청에서 몇 가지 일관된 경향을 관찰했으며, 이는 앱 개발의 동기가 되었습니다:
- 사용자들은 Jira 및 Github 이슈부터 Confluence 문서, 블로그 게시물, 내부 교육 자료 및 PDF 문서에 이르기까지 다양한 유형의 데이터 소스를 RAG 앱에 삽입할 수 있는 기능을 원합니다.
- 데이터 개인 정보 보호 문제로 인해 OpenAI API와 같은 외부 API로 데이터를 전송하지 않기 위해 로컬 LLM 배포를 선호합니다.
- 이들은 데이터 관리 프로세스를 간소화하기 위해 pgvector를 사용하여 Postgres에 직접 벡터 데이터를 저장하고 쿼리하기를 원합니다. 이들은 이미 Postgres에 익숙하고 프로덕션 환경에서 이를 사용하고 있기 때문에 이는 특히 이해하기 쉽습니다.
- 그들은 질문을 하는 사용자의 역할이나 권한에 따라 벡터 검색을 제어하고 규제하기를 원합니다. 프로젝트, 이해관계자 및 부서마다 자신의 정보에 대한 액세스는 허용하면서 다른 사람의 액세스는 제한해야 합니다.
RAG 앱의 제한 사항
RAG(검색 증강 생성) 아키텍처는 많은 이점을 제공하지만, 특히 대규모 언어 모델(LLM)을 로컬에서 실행할 때 몇 가지 문제도 수반합니다:
- 대부분의 모델이 GPU(예: 라마 모델)에 최적화되어 있기 때문에 CPU에서 LLM을 실행하는 것은 어렵습니다. LLM을 로컬에서 실행하는 것이 RAG 아키텍처의 필수 사항은 아니며, 고객 요구 사항에서 관찰한 트렌드에 맞춰 앱에서 이 접근 방식을 선택했다는 점에 유의하세요.
- 로컬에서 개발 및 테스트하는 것은 일반적인 노트북의 메모리, 캐시 및 CPU 제약으로 인해 시간이 많이 소요될 수 있습니다.
- RAG의 명령은 모델의 컨텍스트 창에 의해 제한되는데, 이는 응답을 생성할 때 LLM이 입력으로 처리할 수 있는 토큰의 수를 나타냅니다. 이 고정된 토큰 제한으로 인해 모델이 길거나 복잡한 입력을 기반으로 응답을 이해하고 생성하는 능력이 제한될 수 있습니다.
- 증가된 부하 또는 더 큰 모델을 처리하기 위해 시스템을 확장하는 것은 어려울 수 있으므로 신중한 계획과 리소스 관리가 필요합니다.
- AWS 인스턴스, 특히 g5.2xlarge와 같은 GPU 최적화 인스턴스의 환경 비용은 상당히 높을 수 있습니다.
RAG 애플리케이션의 프로세스 흐름
RAG 애플리케이션을 설계할 때 다음과 같은 워크플로우를 구상했습니다:
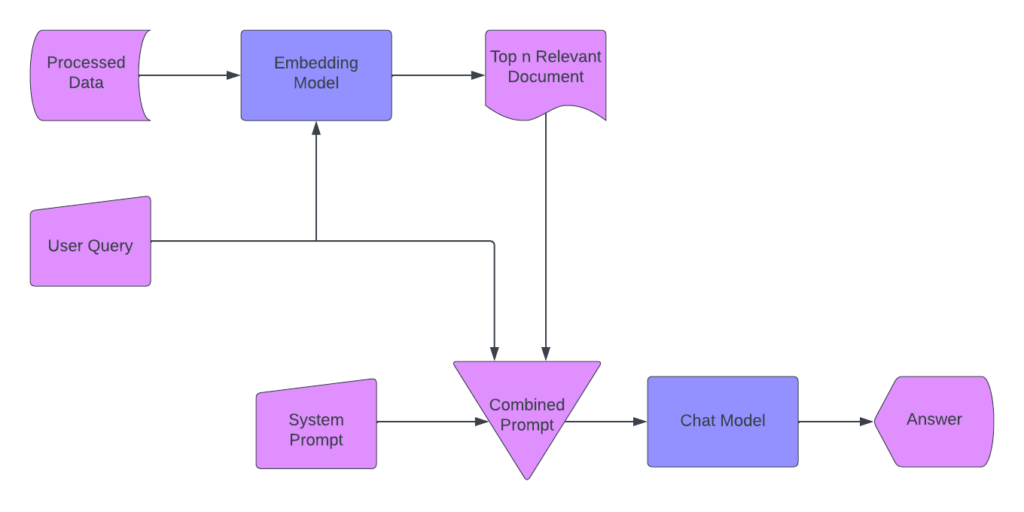
1단계: 데이터 처리
- PDF와 문서를 수집합니다.
- 데이터 청크를 생성합니다.
- 청크를 벡터로 인코딩하고 pgvector를 사용하여 PostgreSQL에 저장합니다.
2단계: 임베딩 모델
- 텍스트 청크를 임베딩 벡터로 변환합니다.
- 채팅 모델에 사용할 데이터를 준비합니다.
3단계: 사용자 쿼리
- 사용자가 질문을 입력할 수 있도록 허용합니다.
- 쿼리를 사용하여 시스템에 메시지를 표시합니다.
4단계: 관련 섹션 검색
- 벡터를 사용하여 상위 N개의 관련 문서 섹션을 식별합니다.
- 모델의 토큰 사용량을 최적화합니다.
5단계: 복합 프롬프트 만들기
- 관련 벡터, 시스템 프롬프트, 사용자의 질문으로 프롬프트를 생성합니다.
- 컨텍스트를 위해 최근 대화 기록을 포함하세요.
6단계: 채팅 모델에 프롬프트 보내기
- 복합 프롬프트를 채팅 모델에 전달합니다.
7단계: 답변 제공
- 채팅 모델에서 응답을 검색합니다.
- 사용자에게 응답을 다시 보냅니다.
그런 다음 이 모든 빌딩 블록을 개발하여 조합하기 시작했습니다.
RAG 애플리케이션 아키텍처
애플리케이션은 앞서 설명한 대로 표준 RAG(검색 증강 생성) 워크플로우를 따릅니다. 여기서 핵심 요소는 벡터를 저장하고 챗봇을 구축하기 위한 Postgres와 pgvector, 그리고 로컬에서 LLM을 실행하는 측면입니다. 이러한 구성 요소는 앱 디자인의 근간을 형성합니다.
요구 사항
- PostgreSQL(버전 12 이상, pgvector는 12 이상 필요)
- pgvector
- Python 3
애플리케이션에는 데이터베이스 생성, 데이터 가져오기, 채팅 기능 시작의 세 가지 주요 단계가 포함됩니다. 이러한 단계는 app.py에 캡슐화되어 있으며, 다음 명령을 사용하여 애플리케이션을 실행할 수 있습니다:
python app.py --help
usage: app.py [-h] {create-db,import-data,chat} ...
Application Description
options:
-h, --help show this help message and exit
Subcommands:
{create-db,import-data,chat}
Display available subcommands
create-db Create a database
import-data Import data
chat Use chat feature
이제 코드를 살펴보고 구현 세부 사항을 살펴보겠습니다.
create_db.py
환경 매개변수(DB_USER, DB_PASSWORD, DB_HOST, DB_PORT)를 사용하여 데이터베이스를 생성합니다. 그런 다음 요구 사항의 일부로 설치한 pgvector 확장을 활성화합니다. 마지막으로 임베딩 테이블을 설정합니다.
전체 코드(create_db.py)를 보려면 아래를 참조하세요:
import os
import psycopg2
def create_db(args, model, device, tokenizer):
db_config = {
"user": os.getenv("DB_USER"),
"password": os.getenv("DB_PASSWORD"),
"host": os.getenv("DB_HOST"),
"port": os.getenv("DB_PORT"),
}
conn = psycopg2.connect(**db_config)
conn.autocommit = True # Enable autocommit for creating the database
cursor = conn.cursor()
cursor.execute(
f"SELECT 1 FROM pg_database WHERE datname = '{os.getenv('DB_NAME')}';"
)
database_exists = cursor.fetchone()
cursor.close()
if not database_exists:
cursor = conn.cursor()
cursor.execute(f"CREATE DATABASE {os.getenv('DB_NAME')};")
cursor.close()
print("Database created.")
conn.close()
db_config["dbname"] = os.getenv("DB_NAME")
conn = psycopg2.connect(**db_config)
conn.autocommit = True
cursor = conn.cursor()
cursor.execute("CREATE EXTENSION IF NOT EXISTS vector;")
cursor.close()
cursor = conn.cursor()
cursor.execute(
"CREATE TABLE IF NOT EXISTS embeddings (id serial PRIMARY KEY, doc_fragment text, embeddings vector(4096));"
)
cursor.close()
print("Database setup completed.")
create-db 명령을 실행한 다음에는 문서를 가져오기 위해 import-data 명령을 실행해야 합니다. import_data.py가 실행되면 db.py와 embedding.py가 호출됩니다. 이것이 데이터 가져오기 프로세스 중에 일어나는 일입니다:
- DB에 연결
- PDF 파일 읽기
- PDF 파일 경로를 입력으로 받아 PDF 파일에서 각 페이지의 텍스트 콘텐츠를 읽고 줄로 분할한 후 줄을 목록으로 반환합니다.
- 임베딩 생성
- 입력 텍스트를 받아 토큰화하여 LLM에 전달하고, 모델의 출력에서 숨겨진 상태를 검색하고, 평균 임베딩을 계산하고, 원본 텍스트와 해당 임베딩 벡터를 모두 반환합니다.
- 데이터베이스에 임베딩 저장
- 문서 조각과 해당 임베딩을 데이터베이스에 저장합니다.
아래 import_data.py를 참조하세요:
import numpy as np
from db import get_connection
from embedding import generate_embeddings, read_pdf_file
def import_data(args, model, device, tokenizer):
data = read_pdf_file(args.data_source)
embeddings = [
generate_embeddings(tokenizer=tokenizer, model=model, device=device, text=line)
for line in data
]
conn = get_connection()
cursor = conn.cursor()
# Store each embedding in the database
for i, (doc_fragment, embedding) in enumerate(embeddings):
cursor.execute(
"INSERT INTO embeddings (id, doc_fragment, embeddings) VALUES (%s, %s, %s)",
(i, doc_fragment, embedding[0]),
)
conn.commit()
print(
"import-data command executed. Data source: {}".format(
args.data_source
)
)
아래에서 db.py를 확인할 수 있습니다:
import os
import psycopg2
def get_connection():
conn = psycopg2.connect(
dbname=os.getenv("DB_NAME"),
user=os.getenv("DB_USER"),
password=os.getenv("DB_PASSWORD"),
host=os.getenv("DB_HOST"),
port=os.getenv("DB_PORT"),
)
return conn
아래 embedding.py를 참조하세요:
# importing all the required modules
import PyPDF2
import torch
from transformers import pipeline
def generate_embeddings(tokenizer, model, device, text):
inputs = tokenizer(
text, return_tensors="pt", truncation=True, max_length=512
).to(device)
with torch.no_grad():
outputs = model(**inputs, output_hidden_states=True)
return text, outputs.hidden_states[-1].mean(dim=1).tolist()
def read_pdf_file(pdf_path):
pdf_document = PyPDF2.PdfReader(pdf_path)
lines = []
for page_number in range(len(pdf_document.pages)):
page = pdf_document.pages[page_number]
text = page.extract_text()
lines.extend(text.splitlines())
return lineschat.py
create-db 및 import-data 명령을 실행한 후에는 chat 명령을 실행해야 합니다. chat.py가 실행되면 rag.py를 호출합니다. 다음 섹션에서 rag.py에 대해 자세히 설명하겠습니다.
채팅 프로세스는 사용자와의 대화형 채팅을 용이하게 하는 채팅 함수를 정의합니다. 이 함수는 사용자에게 질문을 계속 묻고, 지정된 모델을 사용하여 응답을 생성하며, 사용자가 채팅을 종료할 때까지 사용자에게 응답을 표시합니다.
def chat(args, model, device, tokenizer):위 줄은 네 개의 인수를 받는 chat이라는 함수를 정의합니다:
- args: 함수에 전달할 수 있는 추가 인자(있는 경우)
- 모델: 질문에 대한 응답을 생성하는 데 사용되는 파이토치 모델입니다.
- 장치: 장치: 모델이 실행 중인 장치(CPU 또는 GPU)
- 토큰화기: 입력 질문을 토큰화하는 데 사용되는 토큰화기의 인스턴스입니다.
answer = rag_query(tokenizer=tokenizer, model=model, device=device, query=question)
위의 줄은 제공된 토큰화 도구, 모델, 디바이스, 사용자 질문으로 rag_query 함수를 호출합니다. 이 함수는 질문에 대한 응답을 생성합니다.
답변은 rag_query 함수를 호출하여 작성되며, rag.py를 검토하면서 자세히 살펴보겠습니다.
아래에서 chat.py를 확인할 수 있습니다:
from rag import rag_query
def chat(args, model, device, tokenizer):
print("Chat started. Type 'exit' to end the chat.")
while True:
question = input("Ask a question: ")
if question.lower() == "exit":
break
answer = rag_query(tokenizer=tokenizer, model=model, device=device, query=question)
print(f"You Asked: {question}")
print(f"Answer: {answer}")
print("Chat ended.")
rag.py
이름에서 알 수 있듯이 이 스크립트에는 이 애플리케이션의 주요 기능에 필요한 필수 RAG 로직이 포함되어 있습니다. 자세히 살펴보겠습니다.
template = """[INST]
You are a friendly documentation search bot.
Use following piece of context to answer the question.
If the context is empty, try your best to answer without it.
Never mention the context.
Try to keep your answers concise unless asked to provide details.
Context: {context}
Question: {question}
[/INST]
Answer:
"""
위의 템플릿은 질문, 컨텍스트(사용 가능한 경우) 및 봇의 답변을 제시하기 위한 구조화된 형식을 제공합니다. 이는 일관성 있는 답변 제시를 보장하고 모델이 각 쿼리를 처리할 수 있도록 명확한 지침(및 해당되는 경우 컨텍스트)을 제공합니다.
get_retrieval_condition 함수
모든 RAG는 RAG 아키텍처의 핵심 구성 요소인 검색 메커니즘에 의존합니다. 자체 데이터베이스에서 데이터를 검색하고 이 데이터를 사용해 LLM에 컨텍스트를 제공합니다. 그래서 저희가 개발한 rag_query를 사용해 관련 정보(임베딩)를 가져오는 검색 조건을 구축했습니다.
데이터베이스에서 관련 임베딩을 검색하기 위한 SQL 조건을 생성하기 위해 get_retrieval_condition 함수를 사용합니다.
def get_retrieval_condition(query_embedding, threshold=0.7):
# Convert query embedding to a string format for SQL query
query_embedding_str = ",".join(map(str, query_embedding))
# SQL condition for cosine similarity
condition = f"(embeddings <=> '{query_embedding_str}') < {threshold} ORDER BY embeddings <=> '{query_embedding_str}'"
return condition
이 함수는 주어진 쿼리 임베딩에 대한 코사인 유사성(<=>)을 기반으로 임베딩을 찾아 순서를 지정하는 SQL 조건을 구성합니다. 쿼리 임베딩과 임계값을 입력으로 받습니다:
- 쿼리 임베딩: 사용자 쿼리의 임베딩 벡터를 나타내는 목록 또는 배열입니다.
- 임계값: 임베딩이 관련성이 있는 것으로 간주될 수 있는 최대 코사인 거리를 지정하는 실수 값(기본값 = 0.7)입니다. 임계값이 낮을수록 일치 항목이 더 가깝게 일치해야 합니다.
query_embedding_str = ",".join(map(str, query_embedding))
위의 이 줄은 쿼리 임베딩 목록을 SQL 쿼리에 적합한 문자열 형식으로 변환합니다.
condition = f"(embeddings <=> '{query_embedding_str}') < {threshold} ORDER BY embeddings <=> '{query_embedding_str}'"
위의 이 줄은 <=> 연산자를 사용하여 저장된 임베딩과 쿼리 임베딩 간의 코사인 유사성을 계산하는 SQL 조건 문자열을 구성합니다. 이는 코사인 유사도가 지정된 임계값보다 작은 임베딩만 고려되도록 합니다. 또한 쿼리_임베딩과의 코사인 유사도에 따라 결과를 정렬하므로 가장 관련성이 높은 결과가 먼저 나열됩니다.
이 함수는 구성된 SQL 조건 문자열을 반환합니다.
rag_query 함수
rag_query 함수는 쿼리 임베딩 생성, Postgres 데이터베이스에서 문서 검색, 쿼리와 컨텍스트 조합, LLM을 사용한 응답 생성을 통합하여 입력 쿼리에 대한 관련성 있는 답변을 생성합니다. 이는 RAG 시스템에서 가장 중요한 구성 요소입니다.
전체 기능을 살펴본 다음 단계별로 살펴보겠습니다.
def rag_query(tokenizer, model, device, query):
# Generate query embedding
query_embedding = generate_embeddings(
tokenizer=tokenizer, model=model, device=device, text=query
)[1]
# Retrieve relevant embeddings from the database
retrieval_condition = get_retrieval_condition(query_embedding)
conn = get_connection()
register_vector(conn)
cursor = conn.cursor()
cursor.execute(
f"SELECT doc_fragment FROM embeddings WHERE {retrieval_condition} LIMIT 5"
)
retrieved = cursor.fetchall()
rag_query = ' '.join([row[0] for row in retrieved])
query_template = template.format(context=rag_query, question=query)
input_ids = tokenizer.encode(query_template, return_tensors="pt")
# Generate the response
generated_response = model.generate(input_ids.to(device), max_new_tokens=50, pad_token_id=tokenizer.eos_token_id)
return tokenizer.decode(generated_response[0][input_ids.shape[-1]:], skip_special_tokens=True)각 부분이 수행하는 작업을 이해하기 위해 rag_query 함수를 단계별로 세분화해 보겠습니다.
쿼리 임베딩 생성하기
query_embedding = generate_embeddings(
tokenizer=tokenizer, model=model, device=device, text=query
)[1]
여기서는 입력 쿼리에 대한 쿼리 임베딩을 생성합니다. generate_embeddings 함수는 원본 텍스트와 그에 해당하는 임베딩 벡터를 포함하는 튜플을 반환합니다. 반환된 튜플의 두 번째 요소, 즉 쿼리 임베딩을 추출합니다.
데이터베이스에서 관련 임베딩 검색하기
retrieval_condition = get_retrieval_condition(query_embedding)
여기서는 쿼리 임베딩과의 코사인 유사도를 기반으로 데이터베이스에서 관련 문서를 검색하는 조건을 만듭니다.
get_retrieval_condition 함수의 작동 방식은 이전 섹션을 참조하세요.
Explainconn = get_connection()
register_vector(conn)
cursor = conn.cursor()
cursor.execute(
f"SELECT doc_fragment FROM embeddings WHERE {retrieval_condition} LIMIT 5"
)
retrieved = cursor.fetchall()
여기서 데이터베이스에 연결합니다. 그런 다음 SQL 쿼리를 실행하여 검색 조건에 따라 임베딩 테이블에서 문서 조각을 선택하고 가장 관련성이 높은 상위 5개의 임베딩으로 결과를 제한합니다.
쿼리 템플릿 준비
rag_query = ' '.join([row[0] for row in retrieved])
위의 코드는 검색된 문서 조각을 공백으로 구분된 단일 문자열(rag_query)로 연결하고 있습니다. 모든 문서 조각을 가져와서 검색된 각 튜플의 첫 번째 요소를 조인합니다.
여기서는 검색된 문서 조각(컨텍스트)과 원래 쿼리 텍스트(질문)로 템플릿 문자열의 형식을 지정합니다.
응답 생성하기
input_ids = tokenizer.encode(query_template, return_tensors="pt")
tokenizer.encode는 텍스트를 입력 ID로 변환하고 return_tensors=“pt”는 출력이 PyTorch 텐서 형식이 되도록 합니다. 이렇게 하면 쿼리 템플릿을 토큰화하여 모델 입력에 적합한 텐서 형식으로 변환할 수 있습니다.
generated_response = model.generate(input_ids.to(device), max_new_tokens=50, pad_token_id=tokenizer.eos_token_id)
이 코드는 제공된 모델을 사용하여 토큰화된 입력을 생성합니다. 이 코드는 새 토큰의 최대 개수를 50개(응답 길이)로 제한하고 패딩을 위한 시퀀스 끝 토큰 ID를 지정합니다.
generated_response에는 생성된 텍스트 ID가 포함됩니다.
return tokenizer.decode(generated_response[0][input_ids.shape[-1]:], skip_special_tokens=True)
여기서 코드는 생성된 응답 토큰을 사람이 읽을 수 있는 문자열로 디코딩합니다. rag_query 함수의 출력은 최종적으로 생성된 응답 텍스트입니다.
아래 rag.py를 참조하세요:
from itertools import chain
import torch
from pgvector.psycopg2 import register_vector
from db import get_connection
from embedding import generate_embeddings
from pgvector.psycopg2 import register_vector
template = """[INST]
You are a friendly documentation search bot.
Use following piece of context to answer the question.
If the context is empty, try your best to answer without it.
Never mention the context.
Try to keep your answers concise unless asked to provide details.
Context: {context}
Question: {question}
[/INST]
Answer:
"""
def get_retrieval_condition(query_embedding, threshold=0.7):
# Convert query embedding to a string format for SQL query
query_embedding_str = ",".join(map(str, query_embedding))
# SQL condition for cosine similarity
condition = f"(embeddings <=> '{query_embedding_str}') < {threshold} ORDER BY embeddings <=> '{query_embedding_str}'"
return condition
def rag_query(tokenizer, model, device, query):
# Generate query embedding
query_embedding = generate_embeddings(
tokenizer=tokenizer, model=model, device=device, text=query
)[1]
# Retrieve relevant embeddings from the database
retrieval_condition = get_retrieval_condition(query_embedding)
conn = get_connection()
register_vector(conn)
cursor = conn.cursor()
cursor.execute(
f"SELECT doc_fragment FROM embeddings WHERE {retrieval_condition} LIMIT 5"
)
retrieved = cursor.fetchall()
rag_query = ' '.join([row[0] for row in retrieved])
query_template = template.format(context=rag_query, question=query)
input_ids = tokenizer.encode(query_template, return_tensors="pt")
# Generate the response
generated_response = model.generate(input_ids.to(device), max_new_tokens=50, pad_token_id=tokenizer.eos_token_id)
return tokenizer.decode(generated_response[0][input_ids.shape[-1]:], skip_special_tokens=True)app.py
앱 파이의 대부분은 글의 시작 부분에서 다루었습니다. create-db, import-data, chat 명령을 참조하세요. if hasattr(args, "func"):
if torch.cuda.is_available():
device = "cuda"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
else:
device = "cpu"
bnb_config = None
tokenizer = AutoTokenizer.from_pretrained(
os.getenv("TOKENIZER_NAME"),
token=os.getenv("HUGGING_FACE_ACCESS_TOKEN"),
)
model = AutoModelForCausalLM.from_pretrained(
os.getenv("MODEL_NAME"),
token=os.getenv("HUGGING_FACE_ACCESS_TOKEN"),
quantization_config=bnb_config,
device_map=device,
torch_dtype=torch.float16,
)
args.func(args, model, device, tokenizer)
else:
print("Invalid command. Use '--help' for assistance.")
위의 코드 블록을 강조할 가치가 있다고 생각합니다. 여기서는 GPU 장치를 사용할 수 있는지 확인합니다. CUDA를 사용할 수 있는 경우 장치 변수를 cuda로 설정하여 GPU 가속이 사용됨을 나타냅니다. 그렇지 않으면 CPU 실행을 위해 장치를 cpu로 설정합니다.
CUDA를 사용할 수 있는 경우, 양자화를 위한 특정 구성으로 BitsAndBytesConfig 객체를 초기화합니다. 그런 다음 HF Transformers 라이브러리를 사용하여 인과 관계 언어 모델링을 위한 토큰화 도구와 모델을 초기화합니다.
아래 app.py를 볼 수 있습니다:
import argparse
from enum import Enum
from dotenv import load_dotenv
import os
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from commands.chat import chat
from commands.create_db import create_db
from commands.import_data import import_data
load_dotenv()
class Command(Enum):
CREATE_DB = "create-db"
IMPORT_DATA = "import-data"
CHAT = "chat"
def main():
parser = argparse.ArgumentParser(description="Application Description")
subparsers = parser.add_subparsers(
title="Subcommands",
dest="command",
help="Display available subcommands",
)
# create-db command
subparsers.add_parser(
Command.CREATE_DB.value, help="Create a database"
).set_defaults(func=create_db)
# import-data command
import_data_parser = subparsers.add_parser(
Command.IMPORT_DATA.value, help="Import data"
)
import_data_parser.add_argument(
"data_source", type=str, help="Specify the PDF data source"
)
import_data_parser.set_defaults(func=import_data)
# chat command
chat_parser = subparsers.add_parser(
Command.CHAT.value, help="Use chat feature"
)
chat_parser.set_defaults(func=chat)
args = parser.parse_args()
if hasattr(args, "func"):
if torch.cuda.is_available():
device = "cuda"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
else:
device = "cpu"
bnb_config = None
tokenizer = AutoTokenizer.from_pretrained(
os.getenv("TOKENIZER_NAME"),
token=os.getenv("HUGGING_FACE_ACCESS_TOKEN"),
)
model = AutoModelForCausalLM.from_pretrained(
os.getenv("MODEL_NAME"),
token=os.getenv("HUGGING_FACE_ACCESS_TOKEN"),
quantization_config=bnb_config,
device_map=device,
torch_dtype=torch.float16,
)
args.func(args, model, device, tokenizer)
else:
print("Invalid command. Use '--help' for assistance.")
if __name__ == "__main__":
main()향후 개선 사항
앞으로 pgvector-rag-app을 개선하기 위한 몇 가지 아이디어가 있습니다. 첫째, 사용자 인터페이스를 개발하는 것이 도움이 될 것입니다. 저는 빠른 데모 인터페이스를 만드는 데 유망해 보이는 Streamlit으로 실험을 시작했습니다. 이 앱은 주로 데모용이므로 원하는 프론트엔드 스택을 사용하여 유연하게 코딩할 수 있습니다.
데모에서는 AWS 인스턴스를 수동으로 설정했습니다. 하지만 이 앱을 정기적으로 사용할 계획이라면 인프라 자동화 전략의 일환으로 인스턴스 설정 프로세스를 자동화하는 것을 적극 권장합니다.
이 앱은 지금까지 하나의 PDF 문서로만 테스트되었기 때문에 여러 개의 PDF를 처리하려면 더 많은 작업이 필요합니다. 또한 이 작업을 처리하는 더 나은 모델이 있을 수 있으므로 항상 다양한 모델을 사용해보고 평가하는 것이 좋습니다.
현재 앱에는 어떤 사용자가 쿼리를 작성하는지 식별할 수 있는 방법이 없습니다. 사용자의 역할과 권한에 따라 쿼리를 맞춤화하면 사용자 경험을 개인화하고 더 엄격한 보안 요구 사항을 충족할 수 있습니다.
요약
Postgres와 pgvector로만 RAG 애플리케이션을 구축하는 것은 전적으로 가능합니다. 그러나 이는 pgvector만으로는 방정식의 한 부분일 뿐이라는 것을 보여주는 대표적인 예입니다. Postgres와 pgvector의 조합을 통해 Postgres를 벡터 데이터베이스로 활용할 수 있지만, 완전한 AI 애플리케이션에는 더 많은 것이 필요합니다.
최신 분석 및 AI 워크로드를 위해 설계된 통합 플랫폼인 EDB Postgres AI에 대해 알아보세요. 새로운 Postgres AI 확장 기능으로 강화된 이 플랫폼은 AI 애플리케이션의 개발 및 배포 속도를 높여줍니다. 강력한 보안과 포괄적인 지원으로 엔터프라이즈급 AI 앱을 빠르고 효과적으로 구축할 수 있습니다.
본문: RAG app with Postgres and pgvector
EDB 영업 기술 문의: 02-501-5113
이메일: salesinquiry@enterprisedb.com
홈페이지 문의하기
