
EPAS 17과 PostgreSQL 17, 확장성과 성능이 두 배 향상된 비결
작성자: Alessandro Ferraresi
2024년 12월 2일
극한의 트랜잭션 성능, 오라클 호환성, 또는 향상된 엔터프라이즈 기능이 필요한 워크로드를 가지고 계신가요?
EPAS 17이 바로 해답입니다. 그 이유를 살펴보겠습니다.
PostgreSQL를 유지하는 오픈소스 커뮤니티 덕분에, EDB의 Postgres Advanced Server(EPAS) 17은 확장 효율성에서 혁신적인 발전을 이루며 이전 버전 EPAS 16의 성능을 거의 두 배로 끌어올렸습니다.
이런 성과가 어떻게 가능했을까요? 혹시 ‘작은 요정들을 더 불러온 것 아닐까요?’ 물론 실제로 그런 건 아니죠. 굳이 비유하자면, 저장소에 SHA-256 해시 이름을 가진 코드 요정들이 살고 있고, 이들이 모두 힘을 합쳤다고 할 수 있습니다.
EPAS 17의 주요 성능 개선 및 PostgreSQL 17 연계 기능 예시
- WAL 삽입 잠금 최적화
PostgreSQL 17은 I/O 계층 성능을 계속 개선하고 있습니다. 높은 동시성 워크로드는 쓰기 선행 로그(WAL) 처리 개선 덕분에 최대 2배 높은 쓰기 처리량을 경험할 수 있습니다. 추가적으로, 새로운 스트리밍 I/O 인터페이스는 테이블 전체 데이터를 읽는 순차 스캔 및 ANALYZE의 통계 업데이트 속도를 가속화합니다. - 쿼리 실행 성능 개선
PostgreSQL 17은 IN절을 사용하는 쿼리에서 B-tree 인덱스의 성능이 향상되었습니다. - 파일 시스템 읽기를 그룹화하는 새로운 시스템 변수
io_combine_limit도입
이 모든 결과는 PostgreSQL 커뮤니티가 이루어낸 진보 덕분이며, 이를 통해 EPAS도 큰 향상을 이루었습니다. EPAS 및 EDB Postgres Extended Server(PGE)는 커뮤니티 PostgreSQL을 매우 밀접하게 따르고 있으며, 일부 “PostgreSQL 호환” 제품과는 다릅니다. EDB는 패치, 기능 향상, 코드 리뷰, 신규 커뮤니티 멤버 멘토링 및 기타 활동을 통해 커뮤니티 PostgreSQL에 직접 기여하고 있습니다.
PostgreSQL의 개선 사항 외에도 EPAS 17은 성능을 돕기 위한 몇 가지 추가 기능을 제공합니다. 예를 들어, EPAS 17은 파티셔닝 시 프루닝 후 잠금을 얻도록 수정하여 많은 파티션을 가진 경우 훨씬 더 나은 성능을 제공합니다. 이는 워크로드에 따라 상당한 개선이 될 수 있습니다.
HammerDB 기반 EPAS 16·17 성능 벤치마크 설계
벤치마크의 투명성은 매우 중요합니다. 모든 데이터베이스가 주장하는 성능 결과는 재현 가능해야 합니다. 제가 수행한 테스트를 동일하게 실행할 수 있도록 테스트 방법론, 환경 설정, 구성 등 필요한 모든 정보를 포함했습니다.
이 글에서는 OLTP 워크로드를 실행하는 TPC-C 유사 벤치마크 도구인 HammerDB를 사용해 EPAS 16과 EPAS 17의 성능을 비교했습니다. 다른 도구를 사용할 수도 있지만, HammerDB는 업계 표준이 되었으며, 오라클 데이터베이스, Microsoft SQL Server, IBM Db2, MySQL, MariaDB, PostgreSQL 등 세계에서 가장 인기 있는 데이터베이스를 지원하는 선도적인 벤치마킹 및 부하 테스트 소프트웨어입니다.
HammerDB는 널리 알려진 TPC-C와 TPC-H 벤치마크를 공정하게 구현한 오픈소스 소프트웨어로, 소스 코드는 TPC의 GitHub에 호스팅되며 TPC-OSS 하위 위원회에서 관리합니다.
이번 테스트는 메모리에 맞는 데이터셋에서 HammerDB를 실행해 스토리지 병목 현상의 영향을 받지 않고 EPAS 16과 EPAS 17의 성능 향상을 보여주도록 설계되었습니다.
HammerDB는 사용자 지연 없이 최대 트랜잭션 수를 수행하도록 설계되었습니다. 실제 시나리오에서는 사용자 지연이 존재하지만, 이 접근법은 가장 높은 부하 조건에서 시스템 성능을 관찰할 수 있게 해줍니다. 성능 검증을 위해 **New Orders Per Minute(NOPM)**이라는 메트릭을 벤치마크 테스트 동안 측정했습니다.
이 NOPM 메트릭은 다양한 데이터베이스 엔진을 비교하는 데 사용할 수 있습니다.
테스트에는 최신 하드웨어 리소스를 갖춘 시스템이 필요했으며, EDB의 파트너인 Supermicro가 도움을 주었습니다.
테스트 환경 사양
- 운영 체제(OS):
RHEL 9.5 (5.14.0-503.14.1.el9_5.x86_64) - CPU:
2x Intel® Xeon® Gold 6538N (32코어) - RAM:
1024GB - 스토리지:
- 4x SSD U.2 NVMe 7.68TB PCIe v5 – RAID 10 (Postgres 데이터)
- 2x SSD U.2 NVMe 7.68TB PCIe v5 – RAID 0 (Postgres WAL)
- 1x SSD M.2 NVMe 960GB (운영 체제)
벤치마크 설정
아래는 HammerDB를 사용하여 데이터셋을 생성하고 워크로드를 실행하기 위한 구성 코드입니다.
데이터베이스 스키마 생성
tcl코드 복사#!/bin/tclsh
puts "SETTING CONFIGURATION"
dbset db pg
diset connection pg_host "localhost"
diset connection pg_port "5444"
diset tpcc pg_defaultdbase "postgres"
diset tpcc pg_count_ware 5000
diset tpcc pg_num_vu 128
diset tpcc pg_raiseerror true
diset tpcc pg_superuser "enterprisedb"
diset tpcc pg_superuserpass "123"
diset tpcc pg_user "tpcc"
diset tpcc pg_pass "tpcc"
diset tpcc pg_oracompat false
diset tpcc pg_storedprocs false
diset tpcc pg_partition true
buildschema
puts "BUILD COMPLETE"
벤치마크 실행
tcl코드 복사#!/bin/tclsh
puts "SETTING CONFIGURATION"
dbset db pg
diset connection pg_host "localhost"
diset connection pg_port "5444"
diset tpcc pg_raiseerror true
diset tpcc pg_defaultdbase "postgres"
diset tpcc pg_superuser "enterprisedb"
diset tpcc pg_superuserpass ""
diset tpcc pg_user "tpcc"
diset tpcc pg_pass "tpcc"
diset tpcc pg_driver timed
diset tpcc pg_duration 10
diset tpcc pg_rampup 4
diset tpcc pg_timeprofile false
diset tpcc pg_allwarehouse true
diset tpcc pg_oracompat false
diset tpcc pg_storedprocs false
diset tpcc pg_vacuum true
puts "SEQUENCE STARTED"
foreach z { 1 4 8 16 32 64 96 128 192 256 320 } {
puts "VU TEST $z "
loadscript
vuset vu $z
vuset logtotemp 0
vucreate
vurun
vudestroy
}
puts "TEST SEQUENCE COMPLETE"
exit
데이터베이스 매개변수(postgresql.conf 변경 사항)
plaintext코드 복사max_connections = 1000
shared_buffers = 256GB
effective_cache_size = 512GB
work_mem = 8MB
maintenance_work_mem = 64GB
effective_io_concurrency = 200
maintenance_io_concurrency = 200
max_worker_processes = 128
max_parallel_maintenance_workers = 64
checkpoint_timeout = 1d
max_wal_size = 2500GB
min_wal_size = 64GB
random_page_cost = 1.0
vacuum_cost_limit = 8000
autovacuum = off
autovacuum_freeze_max_age = 1000000000
autovacuum_multixact_freeze_max_age = 1000000000
max_locks_per_transaction = 512
edb_dynatune = 0
PostgreSQL 17·EPAS 17 성능 벤치마크 결과 분석
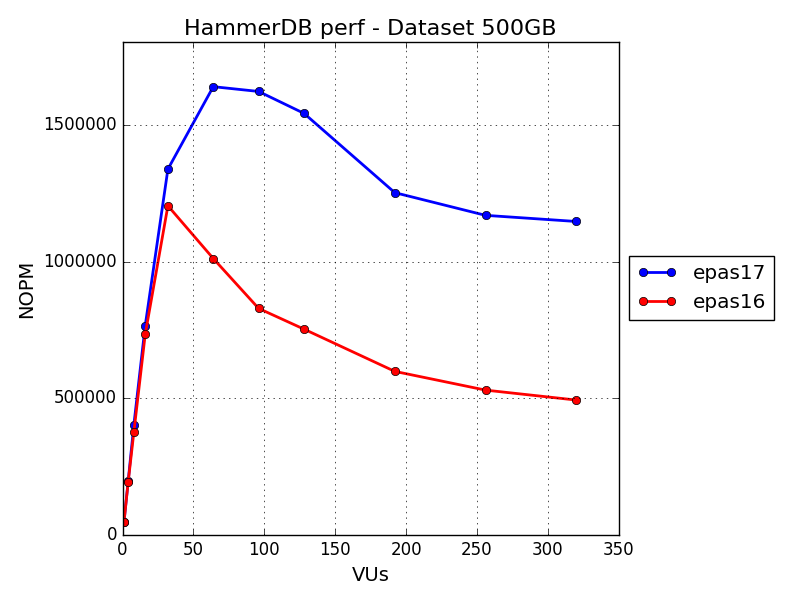
처음에는 초기 가상 사용자(VU) 성능이 EPAS 16과 EPAS 17이 유사해 보입니다. 그러나 32VUs부터 EPAS 17의 성능 개선이 나타나기 시작하며, 11.5% 성능 향상을 달성했습니다. 이 수치는 64VUs에서 62%, 최고점인 320VUs에서는 132%에 이르는 놀라운 성능 향상으로 이어졌습니다.
이번 테스트는 캐싱을 기반으로 설계되었기 때문에, I/O의 영향을 배제하고 EPAS 16과 EPAS 17 간 CPU 활용도 확장성의 차이를 관찰하는 것이 중요합니다.
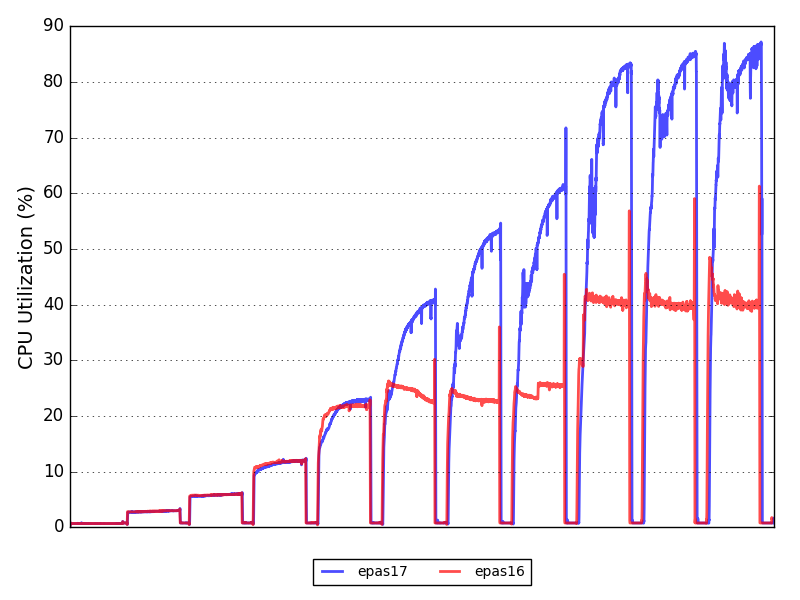
그래프를 보면 EPAS 17이 CPU를 훨씬 더 효율적으로 활용하여 높은 동시성 수준에서 확장성을 크게 향상시키고, 100% 이상의 성능 개선을 이루어냈다는 것을 알 수 있습니다.
데이터베이스 엔진에서 CPU 처리 성능을 효과적으로 활용하는 것은 매우 중요하며, EPAS 17은 이 부분에서 큰 도약을 이루었습니다.
PostgreSQL의 새로운 주요 버전으로 업그레이드하는 일이 늘 흥미로운 건 아니지만, 이번에는 이야기가 다릅니다. 기존 하드웨어만으로도 성능을 크게 향상시킬 수 있다면, 추가 비용 없이 얻을 수 있는 이점을 상상해 보세요. 이 정도면 당장 EDB 패키지 리포지토리를 확인하러 가고 싶지 않으신가요?
결국 데이터베이스에서 트랜잭션 성능을 최대로 끌어올리고 싶다면, 이 요정들(코드)을 잘 활용하세요.😉
본문 Scaling Breakthrough: EPAS 17 Scales Twice as Well, Thanks PostgreSQL!
이메일: salesinquiry@enterprisedb.com

