
데이터 분석에서 AI의 역할: 과대광고를 넘어 ‘고옥탄’ 실용성으로
Dunith Danushka · 2026년 6월 25일
“AI 거품” 피로감을 넘어서
솔직해집시다. **”AI 기반 분석(AI-powered analytics)”**이라는 말은 너무 남발된 나머지 의미를 잃어가고 있습니다. 마케팅 브로슈어 속 AI는 프롬프트 한 줄로 모든 데이터 사일로와 예측 난제를 풀어내는 마법봉처럼 보입니다. 반면 데이터 엔지니어나 분석가의 하루하루를 들여다보면, AI는 종종 “환각(hallucination)”으로 만들어진 코드나 손이 많이 가는 모델의 또 다른 출처일 뿐입니다.
우리는 지금 거대한 실용성 간극(utility gap)을 건너고 있습니다. 한쪽에는 전통적인 데이터 분석의 검증된 신뢰성이 있습니다. SQL 쿼리, ETL 파이프라인, 그리고 우리 비즈니스를 돌리는 BI 대시보드 말이죠. 다른 한쪽에는 생성형 AI와 에이전틱 시스템의 전례 없는 잠재력이 있고요.
진짜 마법은 전자를 후자로 갈아치우는 데 있지 않습니다. 둘을 통합하는 데 있습니다. 거품을 넘어서려면, AI를 데이터 실무자의 대체재로 여기는 걸 멈추고, 데이터 라이프사이클 전체를 위한 **역량 증폭기(force multiplier)**로 바라보기 시작해야 합니다.
이제 “AI가 무엇을 할 수 있는가?”에서 “AI가 내 데이터 스택 안에서 실제로 어떻게 작동하는가?”로 질문을 옮길 때입니다.
데이터 분석: 운영 데이터에서 인사이트를 끌어내다
데이터 분석은 원시 데이터를 가공해, 더 나은 의사결정을 이끄는 값진 인사이트를 찾아내는 일입니다. 대량의 데이터에 통계 알고리즘과 시각화 기법을 적용함으로써, 분석은 조직이 다음을 할 수 있게 해줍니다.
- 과거의 추세와 패턴 이해
- 실시간 성과 모니터링
- 미래 결과 예측
- 프로세스와 전략 최적화
분석에는 여러 갈래가 있으며, 각각 서로 다른 유스케이스와 데이터 특성에 맞습니다. 다음과 같습니다.
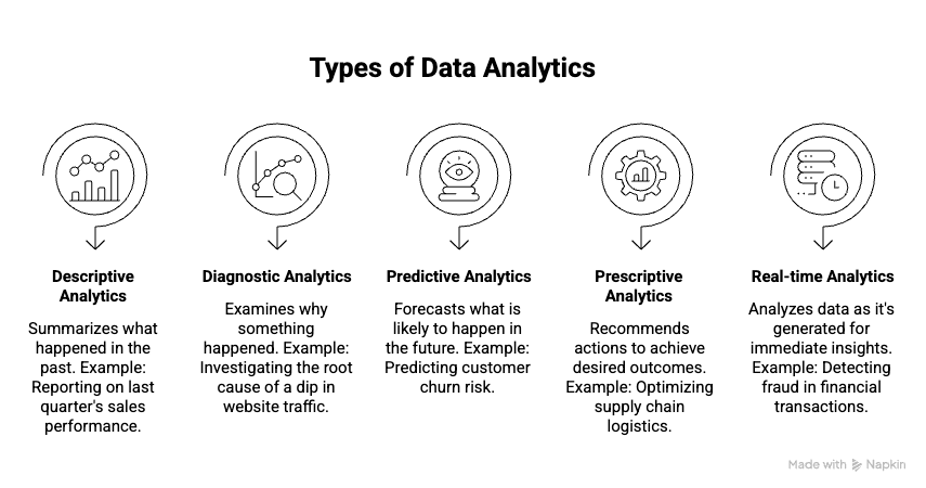
그림 01 – 다양한 분석의 종류
AI+분석 프레임워크: 두뇌, 목소리, 그리고 손
AI가 데이터 분석에 어떻게 들어맞는지 이해하려면, 기술을 조직 안에서의 기능적 역할로 나눠볼 필요가 있습니다. 이것을 현대 분석의 해부학이라고 생각해 보세요.
1. 두뇌: ML 모델 추론(Inferencing)
지난 10년간 우리가 알아온 고전적인 AI입니다. 결정론적(deterministic)이고 예측적입니다.
- 하는 일: 패턴을 식별하고, 이미지를 분류하고, 이탈(churn)을 예측하거나 수요를 전망합니다.
- 분석에서의 역할: 확실한 사실을 제공합니다. LLM이 확률적인(다음 단어를 추측하는) 반면, ML 모델은 통계적 정밀성을 위해 만들어졌습니다. 현대적인 파이프라인에서 이 모델들은 원시 예측값을 데이터 웨어하우스로 공급하는 추론 엔진(inference engine) 역할을 합니다.
2. 목소리: 생성형 AI(LLM)
생성형 AI는 인터페이스 계층 역할을 합니다. 데이터의 복잡함을 언어의 단순함으로 번역하죠.
- 하는 일: 자연어로 SQL을 작성하고, 50페이지짜리 PDF 보고서를 요약하거나, 특정 지표가 왜 떨어졌는지 설명합니다.
- 분석에서의 역할: 접근을 민주화합니다. 분석가에게는 코딩 파트너이고, CXO에게는 복잡한 대시보드를 세 줄짜리 경영진 요약으로 바꿔주는 번역가입니다.
3. 손: 에이전틱 AI
개발자에게 에이전틱 AI는 선형 스크립팅에서 동적 추론으로의 전환입니다. 전통적인 스크립트가 if-then-else 경로를 따른다면, 에이전트는 ReAct(Reasoning and Acting) 루프를 사용합니다. 도구 호출(tool-calling) 능력을 활용해 당신의 데이터 스택과 실시간으로 상호작용하죠.
에이전트는 LLM 기반 오케스트레이션 프레임워크(LangGraph, CrewAI, Semantic Kernel 등)를 활용합니다. 그리고 도구 상자, 즉 Python 함수나 API 커넥터 묶음(예: Snowflake 커넥터, Slack API, Jupyter 샌드박스)을 제공받습니다.
**로직 루프(Logic Loop)**는 에이전트에게 목표가 주어졌을 때 일어납니다.
- 계획(Plans): 목표를 하위 작업으로 쪼갭니다.
- 선택(Selects): 알맞은 도구를 고릅니다(예: execute_sql 또는 plot_seaborn).
- 성찰(Reflects): 출력을 관찰하고(예: “테이블을 찾을 수 없음” 오류), 사람의 개입 없이 쿼리를 스스로 고칩니다.
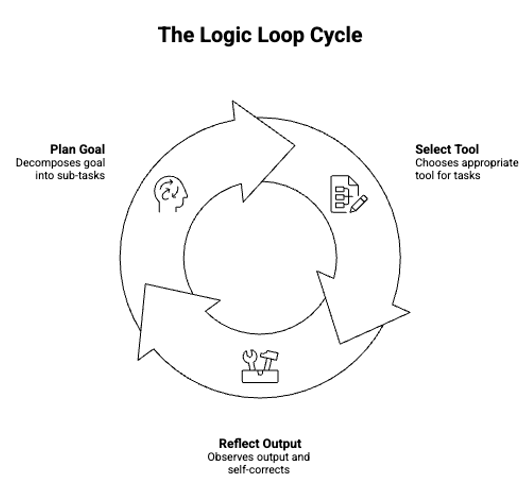
그림 02 – 에이전트의 추론(로직) 루프
에이전트의 목표와 도구 묶음을 실제 유스케이스에 연결해 보면 이렇습니다. 데이터 드리프트를 모니터링하는 고정된 파이프라인을 짜는 대신, 개발자는 **드리프트 에이전트(Drift Agent)**를 만듭니다. 임계치에 도달하면, 이 에이전트는 자율적으로 편향 탐지 스위트를 실행하고, 영향받은 피처를 요약하고, 권장 조치를 담은 Jira 티켓을 엽니다.
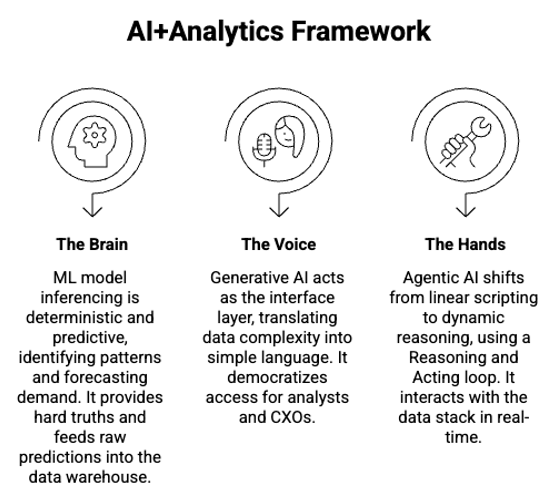
그림 03 – 두뇌, 목소리, 손은 AI가 분석에 어떻게 녹아드는지를 이해하기 위한 시각적 비유입니다.
실무자의 하루: 데이터 전문가의 진화
이 프레임워크의 진짜 가치를 보려면, 그것이 데이터 전문가의 실제 업무를 어떻게 바꾸는지 들여다봐야 합니다. 핵심은 단순한 속도가 아닙니다. 수작업 실행에서 전략적 감독으로의 이동이죠.
데이터 엔지니어: 파이프라인 배관공에서 아키텍트로
- AI 이전: 하루의 60%를, 업스트림 스키마 변경으로 깨진 ETL 작업을 디버깅하는 데 썼습니다. 새 데이터 소스마다 보일러플레이트 Spark 코드를 손으로 짰고요.
- AI 이후(진화):
- 생성형 AI가 원시 스키마 메타데이터를 바탕으로 초기 dbt 모델과 문서를 생성합니다.
- 에이전틱 AI가 파이프라인을 모니터링하다가, 스키마 변경이 생기면 업데이트된 매핑을 담은 풀 리퀘스트를 만들어 엔지니어가 검토하게 합니다.
- 결과: 엔지니어는 “터진 배관”을 고치는 대신 데이터 거버넌스와 인프라 비용 최적화에 집중합니다.
데이터 사이언티스트: 데이터 청소부에서 실험가로
- AI 이전: 탐색적 데이터 분석(EDA)에 며칠을 쏟고, 이상치를 일일이 처리하고, 시행착오로 피처 엔지니어링을 했습니다.
- AI 이후(진화):
- ML 추론으로 정리되지 않은 데이터셋에 자동으로 라벨을 답니다.
- 에이전틱 AI가 샌드박스에서 피처 엔지니어링 50가지 변형을 돌려, 모델 정확도 기준 상위 세 가지 세트를 제시합니다.
- 생성형 AI가 최종 모델의 블랙박스를 설명하며, 이해관계자를 위해 피처 중요도에 대한 자연어 보고서를 만들어냅니다.
- 결과: 사이언티스트는 데이터 가공보다 가설 수립과 비즈니스 로직에 더 많은 시간을 씁니다.
데이터 분석가: 보고서 작성자에서 전략 자문가로
- AI 이전: “이 수치 좀 뽑아줄래요?”라는 요청의 무한 반복 속에 살았습니다. SQL을 손보고 Excel·Tableau 차트를 다듬느라 몇 시간을 썼고요.
- AI 이후(진화):
- 생성형 AI(자연어→SQL) 덕분에 현업 사용자가 채팅 인터페이스로 “몇 개인가요…” 같은 질문에 스스로 답합니다.
- 에이전틱 AI가 능동적으로 인사이트를 드러냅니다. 분석가가 매출 하락을 찾아 헤매는 대신, 에이전트가 이런 메시지를 보냅니다. “X 지역 매출이 12% 떨어졌습니다. 재고 데이터를 분석해 보니 Y 항만의 지연과 상관관계가 있네요. 완화 대책 보고서를 작성할까요?”
- 결과: 분석가는 사람 쿼리 엔진에서 의사결정 지원 파트너로 올라섭니다.
비즈니스 가치: 비용 센터에서 가치 창출자로
CXO에게 2026년 AI를 둘러싼 대화는 달라졌습니다. 더 이상 “기술이 작동하느냐”가 아니라, **”에이전틱 알파(Agentic Alpha)”**를 가져다주느냐가 관건입니다. 자율 지능으로 경쟁자를 앞질러 얻는 측정 가능한 우위 말이죠.
이런 환경에서 분석 속 AI의 가치는 세 가지 핵심 기둥으로 정의됩니다.
1. 지능 효율 비율(Intelligence Efficiency Ratio)
전통적 ROI인 (매출 − 비용) / 비용은 AI에는 너무 무딘 잣대가 되어가고 있습니다. 앞서가는 조직들은 이제 **지능 효율 비율(IER, Intelligence Efficiency Ratio)**을 측정합니다. 이는 ‘AI 세금'(컴퓨팅 비용, 토큰 소비, 모델 라이선스) 대비 생산된 고의도(high-intent) 인사이트의 양을 추적합니다.
IER의 제안 공식은 다음과 같습니다.
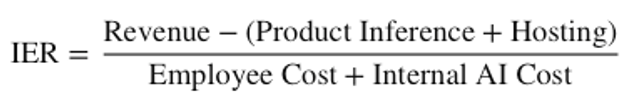
- 분자(매출총이익): 총매출에서 제품 제공의 직접 비용(AI 모델 추론 및 호스팅 비용)을 뺀 값.
- 분모(총 지능 투입): 완전 부담 인건비에 사내 AI 도구 사용 비용(예: Copilot, 내부 LLM 호출, 자동화 에이전트)을 더한 값.
효과: 에이전틱 AI로 데이터 탐색의 1차 작업을 자동화함으로써, 기업들은 인사이트당 비용을 15~45% 절감하고 있습니다. 비용만 아끼는 게 아닙니다. 고차원 전략에 재배치할 수 있는 수천 시간의 인적 자원을 되찾아 줍니다.
2. 의사결정 속도(인사이트까지의 시간)
변동성 큰 시장에서는 시간의 가치가 전부입니다. 경쟁자가 공급망 차질을 알아채는 데 사흘이 걸리는데, 당신의 에이전틱 AI가 그것을 3분 만에 식별하고 완화 계획까지 제안한다면, 이미 이긴 셈입니다.
이점: AI가 통합된 분석은 데이터 이벤트와 비즈니스 행동 사이의 거리를 무너뜨립니다. 조직을 사후 보고에서 선제적 대응으로 옮겨놓죠.
3. 리스크 완화와 ‘진실의 계보’
CXO는 흔히 블랙박스 AI를 경계합니다.
블랙박스 AI란, 정확한 결과를 내더라도 내부 추론을 해석하기 어려운 모델(주로 딥러닝 시스템)을 말합니다. 왜 특정 예측이 나왔는지 추적하기 어렵기 때문에, 이런 시스템은 신뢰·컴플라이언스·리스크 관리 측면에서 문제를 일으킬 수 있습니다. 블랙박스를 연다는 건 보통, 의사결정을 설명하고 검증할 수 있도록 해석 가능성, 감사 추적, 사람의 검토를 더한다는 뜻입니다.
현대적 프레임워크는 생성형 AI를 결정론적 ML과 짝지어 이 블랙박스 문제를 해결합니다.
가드레일: AI 에이전트가 재무 전망을 제안할 수는 있지만, 그 밑바탕의 계산은 투명한 감사 추적을 갖춘 엄격한 ML 모델이 수행합니다. 이것이 바로 **설명 가능한 AI(explainable AI)**이며, 자동화의 속도를 누리면서도 규제 준수를 충족할 수 있게 해줍니다.
현실 점검: 마지막 솔직한 한마디
잠재력은 거대하지만, 발은 땅에 붙이고 있어야 합니다. AI는 나쁜 데이터를 고쳐주는 해결책이 아닙니다. AI ROI의 가장 큰 병목은 모델 자체가 아니라 **데이터 부채(data debt)**입니다. 밑바탕 데이터 기반이 파편화돼 있거나 노이즈투성이라면, AI 에이전트는 인사이트만 찾는 게 아닙니다. 당신이 손으로는 도저히 바로잡을 수 없는 규모로 환각을 찾아내고, 또 그 위에서 행동하게 됩니다.
가장 성공한 조직은 AI 예산이 가장 큰 곳이 아닙니다. 데이터 품질을 일급 시민으로 대하는 곳입니다. AI가 엔진이라면, 당신의 데이터는 연료입니다. 가속 페달을 밟기 전에, 그 연료가 고옥탄인지부터 확인하세요.
EDB Postgres AI의 강점: Postgres를 AI 발전소로
이 프레임워크를 구현하려면, 에이전틱 시대에 맞게 설계된 데이터 기반이 필요합니다. EDB Postgres AI(EDB PG AI)는 데이터베이스 위에 AI 기능을 얹기만 하는 게 아닙니다. 당신의 전체 데이터 자산을, 해부학의 세 계층(두뇌, 목소리, 손)을 모두 위해 만들어진 단일한 지능형 코어로 통합합니다.
- 데이터 부채를 원천에서 제거: Postgres Analytics Accelerator(PGAA) 익스텐션은 살아 있는 Postgres 트랜잭션을 개방형 Iceberg 레이크하우스에 끊임없이 동기화합니다. 전통적인 ETL의 취약함 없이 분석 계층을 운영 데이터와 늘 최신으로 유지하죠. 앞서 다뤘듯 데이터 부채는 AI ROI의 가장 큰 병목이며, PGAA는 그것을 사후가 아니라 구조적으로 해결하는 방법입니다.
- RAG와 시맨틱 검색을 Postgres 안에서 직접: EDB PG AI Vector Engine은 임베딩 벡터를 데이터베이스 안에서 네이티브로 저장·인덱싱·검색하게 해줍니다. 외부 벡터 스토어가 필요 없습니다. 이것이 ‘목소리’를 작동하게 만드는 인프라 계층입니다. 에이전트와 LLM이 동떨어진 사본이 아니라 실제 운영 데이터에서 올바른 맥락을 끌어오게 하니까요.
- 프로덕션 규모로 에이전트 구축·배포: EDB PG AI Factory의 Agent Studio(Langflow 기반)는 에이전틱 워크플로를 설계·테스트·배포하는 시각적 환경을 제공합니다. 이 글에서 설명한 ReAct 루프형 에이전트를, 파이프라인을 일일이 손으로 짜지 않고도 만들 수 있죠.
- 고동시성 분석 워크로드를 위한 확장: WarehousePG는 레이크하우스에서 직접 깊은 분석 쿼리를 구동합니다. 표준 CPU 용량을 넘어서는 워크로드라면, PGAA 익스텐션이 NVIDIA Spark RAPIDS와 연동해 무거운 작업을 GPU로 오프로드합니다. 부하가 걸려도 의사결정 속도를 높게 유지하죠.
- 에이전트에게 데이터 네이티브 접근 제공: PG Airman MCP 서버는 에이전트가 런타임에 데이터베이스 객체와 스키마를 자율적으로 발견하게 해줍니다. 이것이 ‘손’을 프로덕션 규모에서 작동하게 만듭니다. 에이전트가 정적 스냅샷이 아니라 실제 데이터 토폴로지 위에서 추론할 수 있으니까요.
- 속도를 희생하지 않고 주권 강제: EDB PG AI Hybrid Manager는 데이터 자산 전반에 걸쳐 로컬 LLM 서빙과 거버넌스 강제를 가능하게 합니다. 이것이 블랙박스 문제에 대한 현실적인 답입니다. 에이전틱 추론이 당신의 울타리 안에 머물고, 컴플라이언스를 충족하는 투명한 감사 추적까지 갖추니까요.
두 세계의 장점을 모두
데이터의 미래는 Postgres의 안정성과 AI의 첨단 사이에서 양자택일하는 게 아닙니다. 둘의 매끄러운 결합입니다.
EDB PG AI를 활용하면, 단지 더 빠른 데이터베이스를 만드는 게 아닙니다. 지능형 데이터 코어를 만드는 것입니다. 전통적 분석의 정밀함, 생성형 AI의 직관적인 인터페이스, 에이전틱 시스템의 자율적 행동을, 세계에서 가장 신뢰받는 데이터베이스 위에서 모두 얻게 됩니다.
EDB와 함께라면, 과거를 분석하는 데 그치지 않고 미래를 지휘합니다.
EDB Postgres AI와 분석·에이전트, 더 알아보기
도입이나 PoC, 데모가 궁금하시다면 EDB Korea로 문의해 주세요.
- 이메일: salesinquiry@enterprisedb.com
- 전화: 02-501-5113
- 문의하기 →
원문: The Role of AI in Data Analytics: Moving From Hype to High-Octane Utility (EDB Blog)
