
pgvector란 무엇이며 어떻게 도움이 될 수 있을까요?
EDB 팀
9월 03, 2024
Postgres 데이터베이스에서 pgvector와 그 애플리케이션을 살펴보세요. 벡터 유사도 검색과 벡터 데이터를 생성하고 저장하는 방법에 대해 자세히 알아보세요.
Postgres 워크로드를 가속화하는 방법은 무수히 많습니다. 데이터를 저장하고 쿼리하는 방법, 데이터의 크기, 쿼리를 실행하는 빈도에 따라 달라집니다.
이 블로그 게시물에서는 데이터베이스 벡터 작업을 더 빠르고 효율적으로 수행하여 Postgres의 AI 기반 워크로드에 pgvector가 어떻게 도움이 될 수 있는지 살펴봅니다.
pgvector: Postgres에서 벡터 데이터 저장 및 쿼리하기
pgvector는 벡터를 저장, 쿼리 및 인덱싱할 수 있는 PostgreSQL 확장입니다.
Postgres 16에는 기본 벡터 기능이 없으며, pgvector는 이 공백을 메우기 위해 설계되었습니다. 벡터 데이터를 나머지 데이터와 함께 Postgres에 저장하고, 벡터 유사도 검색을 수행하면서 Postgres의 모든 훌륭한 기능을 활용할 수 있습니다.
벡터 유사도 검색은 누가 필요할까요?
고차원 데이터로 작업할 때, 특히 추천 엔진, 이미지 검색, 자연어 처리와 같은 애플리케이션에서 벡터 유사도 검색은 매우 중요합니다. 많은 AI 애플리케이션은 사용자 행동이나 콘텐츠 유사성을 기반으로 유사한 항목이나 추천을 찾는 작업을 포함합니다. pgvector는 벡터 유사성 검색을 효율적으로 수행할 수 있어 추천 시스템, 콘텐츠 기반 필터링, 유사성 기반 AI 작업에 적합합니다.
pgvector 확장 프로그램은 Postgres와 원활하게 통합되므로 사용자는 기존 데이터베이스 인프라 내에서 이 기능을 활용할 수 있습니다. 따라서 별도의 데이터 저장소나 복잡한 데이터 전송 프로세스가 필요 없기 때문에 AI 애플리케이션의 배포와 관리가 간소화됩니다.
벡터란 정확히 무엇인가요?
벡터는 숫자의 목록입니다. 선형 대수 과정을 수강했다면, 유사도 검색이 많은 벡터 연산을 수행하므로 지금이 바로 그 혜택을 누릴 수 있는 시기입니다!
기하학에서 벡터는 n차원 공간에서의 좌표를 나타내며, 여기서 n은 차원의 수입니다. 아래 이미지에는 2차원 벡터(n=2)가 있습니다. 머신 러닝에서는 아래 그림의 단순한 벡터처럼 상상하기 쉽지 않은 고차원 벡터를 사용합니다.
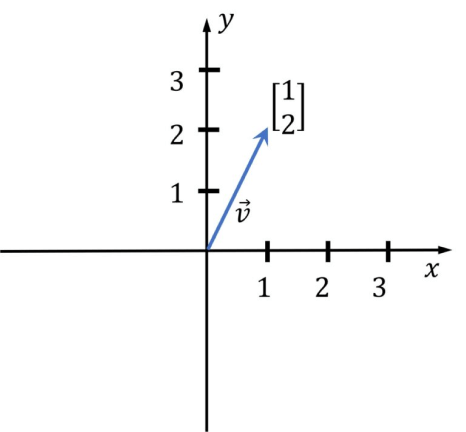
이미지 출처: https://media5.datahacker.rs/2020/03/Picture36-1-768×712.jpg
이제 예제를 살펴보겠습니다.
이 예제에서는 몇 개의 문서를 저장하고 벡터 임베딩을 생성한 다음 이러한 임베딩을 Postgres에 저장하겠습니다. 임베딩 데이터를 색인하고 유사성 쿼리를 실행하겠습니다.
여기서 설명하는 예제의 코드는 다음과 같습니다: https://github.com/gulcin/pgvector_blog
전제 조건:
- PostgreSQL 설치(pgvector는 PostgreSQL 11+ 지원)
- pgvector 확장 설치(설치 노트 참조)
- OpenAPI 계정과 약간의 신용 잔액이 있어야 합니다(1달러 미만 사용).
pgvector가 설치되면 확장을 생성하여 Postgres 데이터베이스에서 활성화할 수 있습니다:
postgres=# Create extension vector;
CREATE EXTENSION1단계: 문서용 테이블 만들기
문서를 저장할 간단한 테이블을 만들어 보겠습니다. 이 테이블의 각 행은 문서를 나타내며, 문서의 제목과 내용을 저장합니다.
문서 테이블을 만듭니다:
CREATE TABLE documents (
id int PRIMARY KEY,
title text NOT NULL,
content TEXT NOT NULL
);저장하는 각 문서에 대해 임베딩을 생성하고 이를 저장하기 위해 document_embedings 테이블을 생성합니다.
임베딩 벡터의 크기가 1536인 것을 볼 수 있는데, 이는 우리가 사용하는 OpenAI 모델의 차원이 1,536개이기 때문입니다.
-- Create document_embeddings table
CREATE TABLE document_embeddings (
id int PRIMARY KEY,
embedding vector(1536) NOT NULL
);HNSW 인덱스를 사용하여 데이터를 인덱싱해 보겠습니다.
CREATE INDEX document_embeddings_embedding_idx ON document_embeddings USING hnsw (embedding vector_l2_ops);다음 블로그 게시물에서 벡터 데이터베이스의 인덱싱에 대해 설명할 예정이므로 여기서는 자세히 설명하지 않겠지만, HNSW가 IVFFlat보다 쿼리 성능이 더 우수하다는 것은 알고 계실 것입니다.
또한 IVFFlat 인덱스의 경우 테이블에 데이터가 어느 정도 있는 후에 인덱스를 생성하는 것이 가장 좋습니다. HNSW 인덱스의 경우, IVFFlat과 같은 학습 단계가 없으므로 테이블에 데이터가 없어도 인덱스를 만들 수 있습니다. 제안에 따라 테이블에 데이터를 삽입하기 전에 인덱스를 생성한 것을 보셨을 것입니다.
이제 테이블에 몇 가지 샘플 데이터를 삽입할 수 있습니다. 이 예제에서는 Postgres 확장과 그 간단한 설명을 선택했습니다.
-- Insert documents into documents table
INSERT INTO documents VALUES ('1', 'pgvector', 'pgvector is a PostgreSQL extension that provides support for vector similarity search and nearest neighbor search in SQL.');
INSERT INTO documents VALUES ('2', 'pg_similarity', 'pg_similarity is a PostgreSQL extension that provides similarity and distance operators for vector columns.');
INSERT INTO documents VALUES ('3', 'pg_trgm', 'pg_trgm is a PostgreSQL extension that provides functions and operators for determining the similarity of alphanumeric text based on trigram matching.');
INSERT INTO documents VALUES ('4', 'pg_prewarm', 'pg_prewarm is a PostgreSQL extension that provides functions for prewarming relation data into the PostgreSQL buffer cache.');2단계: 임베딩 생성
이제 문서가 저장되었으므로 임베딩 모델을 사용하여 문서를 임베딩으로 변환합니다.
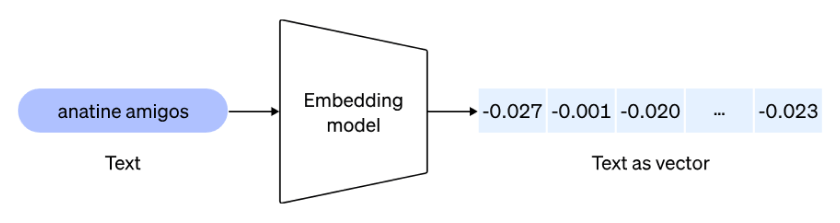
이미지 출처: https://cdn.openai.com/new-and-improved-embedding-model/draft-20221214a/vectors-1.svg
먼저 임베딩에 대해 이야기해 보겠습니다. 저는 OpenAI 문서에 있는 정의가 가장 마음에 드는데, 간단하고 온포인트이기 때문입니다:
임베딩은 부동 소수점 숫자의 벡터(목록)입니다. 두 벡터 사이의 거리는 관련성을 측정합니다. 거리가 작으면 관련성이 높고, 거리가 크면 관련성이 낮음을 나타냅니다.
따라서 두 문서가 의미론적으로 얼마나 연관성이 있는지 비교하려면 해당 문서를 임베딩으로 변환하고 유사도 검색을 실행해야 합니다.
API 제공업체를 선택하고 원하는 언어로 이러한 API를 사용할 수 있습니다. 저는 단순성과 이전 경험을 고려해 Python을 선호하는 언어로 OpenAI API를 선택했습니다. 이 예제에서 사용된 임베딩 모델은 “text-embedding-ada-002”로, 저렴하고 간단하기 때문에 사용 사례에 적합할 것입니다. 실제 애플리케이션의 특정 사용 사례에 따라 다른 모델을 평가해야 할 수도 있습니다.
시작해 보겠습니다. 아래 Python 코드의 경우 OpenAI API 키를 가져와서 연결 문자열을 작성하여 Postgres 데이터베이스에 연결해야 합니다.
# Python code to preprocess and embed documents
import openai
import psycopg2
# Load OpenAI API key
openai.api_key = "sk-..." #YOUR OWN API KEY
# Pick the embedding model
model_id = "text-embedding-ada-002"
# Connect to PostgreSQL database
conn = psycopg2.connect(database="postgres", user="gulcin.jelinek", host="localhost", port="5432")
# Fetch documents from the database
cur = conn.cursor()
cur.execute("SELECT id, content FROM documents")
documents = cur.fetchall()
# Process and store embeddings in the database
for doc_id, doc_content in documents:
embedding = openai.Embedding.create(input=doc_content, model=model_id)['data'][0]['embedding']
cur.execute("INSERT INTO document_embeddings (id, embedding) VALUES (%s, %s);", (doc_id, embedding))
conn.commit()
# Commit and close the database connection
conn.commit()이 코드는 데이터베이스에서 문서 콘텐츠를 가져오고, OpenAI API를 사용해 임베딩을 생성한 다음, 이 임베딩을 다시 데이터베이스에 저장합니다. 이 방법은 소규모 데이터베이스에 적합하지만, 실제 시나리오에서는 기존 데이터와 이벤트 트리거에 일괄 처리를 사용하거나 스트리밍을 변경하여 데이터베이스가 변경될 때마다 벡터를 최신 상태로 유지하는 것이 좋습니다.
3단계: 임베딩 쿼리하기
이제 데이터베이스에 임베딩을 저장했으므로 pgvector를 사용하여 임베딩을 쿼리할 수 있습니다.
아래 코드는 주어진 쿼리 문서와 유사한 문서를 찾기 위해 유사성 검색을 수행하는 방법을 보여줍니다.
# Python code to preprocess and embed documents
import psycopg2
# Connect to PostgreSQL database
conn = psycopg2.connect(database="postgres", user="gulcin.jelinek", host="localhost", port="5432")
cur = conn.cursor()
# Fetch extensions that are similar to pgvector based on their descriptions
query = """
WITH pgv AS (
SELECT embedding
FROM document_embeddings JOIN documents USING (id)
WHERE title = 'pgvector'
)
SELECT title, content
FROM document_embeddings
JOIN documents USING (id)
WHERE embedding <-> (SELECT embedding FROM pgv) < 0.5;"""
cur.execute(query)
# Fetch results
results = cur.fetchall()
# Print results in a nice format
for doc_title, doc_content in results:
print(f"Document title: {doc_title}")
print(f"Document text: {doc_content}")
print()이 쿼리는 먼저 “pgvector”라는 제목의 문서에 대한 임베딩 벡터를 가져온 다음 유사성 검색을 사용하여 유사한 콘텐츠의 문서를 가져옵니다. “<->” 연산자에 주목하세요. 여기서 모든 pgvector 마법이 일어납니다. 이것이 바로 HNSW 인덱스를 사용하여 두 벡터 간의 유사도를 구하는 방법입니다. “0.5″는 사용 사례에 따라 크게 달라질 수 있는 유사성 임계값으로, 실제 애플리케이션에서는 미세 조정이 필요합니다.
결과
가져온 데이터에 대해 쿼리 스크립트를 실행한 결과, 유사도 검색에서 pgvector와 유사한 문서 두 개가 발견되었으며 그 중 하나가 pgvector 자체인 것을 확인할 수 있었습니다.
EDB Postgres® AI 클라우드 서비스, 이제 pgvector 지원
Postgres® AI 클라우드 서비스는 모든 주요 클라우드 플랫폼에서 Postgres를 실행할 수 있는 EDB의 관리형 Postgres 서비스입니다. 이제 데이터베이스에서 pgvector를 활성화하고 실험을 시작할 수 있습니다!
본문: What is pgvector, and How Can It Help You?
메일: salesinquiry@enterprisedb.com

