
EDB Postgres AI Analytics Accelerator 시작하기
작성자: Dunith Danushka
2025년 7월 2일
EDB Postgres AI Analytics Accelerator로 분석 애플리케이션을 구축하는 방법: 단계별 가이드
ETL 파이프라인 없이도 수십억 건의 데이터를 초 단위로 처리할 수 있는 고성능 분석 엔진이 Postgres 위에 구현된다면 어떨까요? 트랜잭션 데이터와 현대적인 레이크하우스 포맷을 하나의 시스템으로 질의할 수 있고, 컴퓨트와 스토리지를 분리하여 워크로드에 따라 독립적으로 확장할 수 있다면 어떤 가능성이 열릴까요?
이번 튜토리얼에서는 이러한 비전을 EDB Postgres AI Analytics Accelerator를 통해 실현하는 방법을 안내합니다. Postgres 데이터베이스와 최신 레이크하우스 환경을 아우르며 빠른 쿼리를 실행하는 방법, 데이터 주권을 완전히 유지하면서도 탁월한 분석 성능을 제공하는 방법을 단계별로 소개합니다.
Analytics Accelerator 개요
EDB Postgres AI Analytics Accelerator는 Postgres를 컬럼 기반 분석 데이터베이스로 변환하여, 트랜잭션 성능을 저하시키지 않고도 고속 분석이 가능하게 합니다. 이 분석 엔진은 컴퓨트와 스토리지를 분리하고 ETL 파이프라인을 제거하며, 레이크하우스와 레거시 데이터 저장소 모두를 지원함으로써 고급 AI 기반 비즈니스 인텔리전스를 실현합니다.
요약하자면, Analytics Accelerator는 임시 Postgres 인스턴스에 연결된 벡터화된 쿼리 엔진으로 구성되며, 주요 구성 요소는 다음과 같습니다:
- Delta Lake 및 Apache Iceberg 포맷을 지원하는 분리된 컬럼형 스토리지 계층
- 오브젝트 스토리지 연결을 위한 PGFS 확장 모듈
- 벡터화된 쿼리 처리를 위한 PGAA 확장 모듈
- 메타데이터 관리를 위한 Iceberg REST 카탈로그 통합
Analytics Accelerator 아키텍처
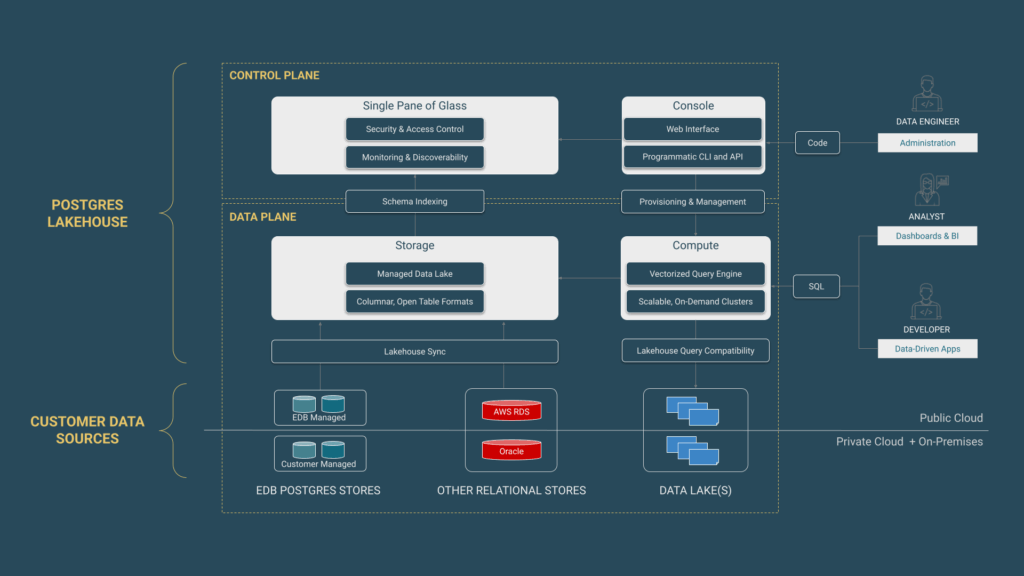
Analytics Accelerator의 컴퓨트와 스토리지 분리는 분석 워크로드에 이상적인 확장성을 제공합니다. 스토리지 계층이 ‘단일 진실 소스(source of truth)’로 작동하기 때문에 여러 Postgres 엔진이 동시에 동일한 데이터를 조회할 수 있으며, 상호 간섭 없이 작동합니다. 데이터는 오브젝트 스토리지에 고압축 포맷으로 저장되며, 컴퓨트 자원은 필요할 때만 생성되어 유휴 비용을 줄입니다.
자세한 아키텍처 및 설정 정보는 공식 문서를 참고하세요.
빠르게 시작하기 (Quick Start)
1. Lakehouse 클러스터 프로비저닝
EDB Postgres AI Hybrid Manager (HM)에서 새 Lakehouse 클러스터를 생성합니다. 이 클러스터는 Analytics Accelerator 확장이 사전 설치된 단일 노드 Postgres 데이터베이스입니다. 자체 호스팅을 원하는 경우, EDB 소프트웨어 저장소에서 pgaa 확장을 다운로드하여 PostgreSQL, EnterpriseDB Advanced Server, 또는 Postgres Extended Server에 설치할 수도 있습니다.
**Hybrid Manager Console(HM Console)**은 EDB Postgres AI 플랫폼의 제어판으로, 데이터베이스 배포, GenAI 워크로드 실행, Postgres 분석 환경 확장을 하나의 UI에서 관리할 수 있습니다. Kubernetes 환경에서 동작하며, 직관적인 웹 인터페이스와 REST API를 제공합니다.
먼저 HM Console에 로그인하여 새 프로젝트를 생성한 후, 아래와 같이 Create New > Lakehouse Analytics를 선택합니다.
템플릿 기반 혹은 커스텀 클러스터 생성을 선택할 수 있는 Create Analytical Cluster 페이지가 열립니다. 여기서는 Custom Build → Start from Scratch를 선택합니다.
클러스터 설정 페이지에서 원하는 노드 수와 구성을 선택하고 나면, 클러스터 생성이 시작됩니다. 일반적으로 10~15분 이내에 프로비저닝이 완료됩니다.
Lakehouse 클러스터는 임시 Postgres 노드로 구성되며, 하드 드라이브에는 시스템 테이블 외에 어떠한 데이터도 저장되지 않습니다. 하드 드라이브는 Parquet 데이터를 위한 캐시 또는 메모리에 적재되지 않는 쿼리의 “스필(spill)” 공간으로만 활용됩니다. 즉, 진정한 “scale-to-zero”가 가능한 탄력형 쿼리 엔진입니다.
클러스터에 연결하기
Postgres 클라이언트를 사용해 Lakehouse 클러스터에 연결할 수 있습니다.
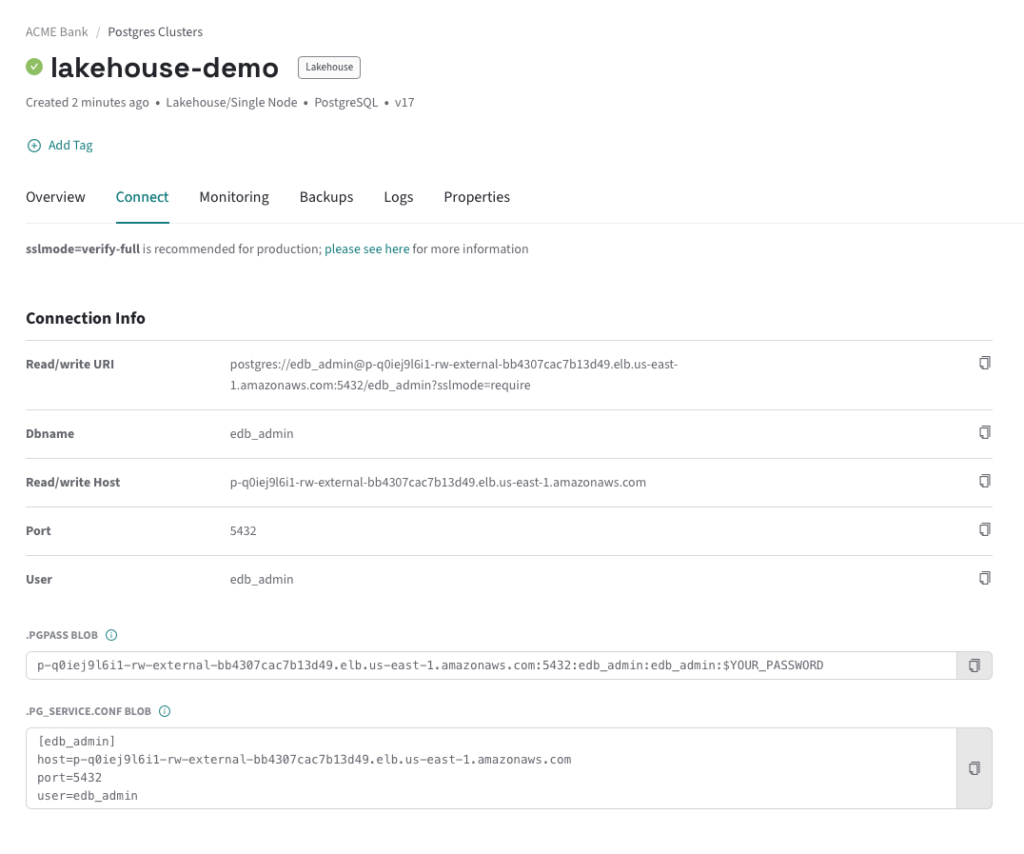
HM Console의 클러스터 상세 페이지에서 Connect 버튼을 클릭하여 연결 문자열을 복사합니다.
psql -U edb_admin -h p-q0iej9l6i1-rw-external-bb4307cac7b13d49.elb.us-east-1.amazonaws.com
psql 외에도 pgcli, pgAdmin 등 다양한 Postgres 도구를 사용할 수 있습니다.
내장 데이터셋 확인
모든 Lakehouse 클러스터에는 Delta Lake 형식의 벤치마크 데이터셋 카탈로그가 포함되어 있습니다. 해당 데이터셋은 퍼블릭 S3 버킷에 저장되어 있으며, 다음을 포함합니다:
- TPC-H, TPC-DS (scale factor: 1, 10, 100, 1000)
- ClickBench
- “10억 행 챌린지 (1 Billion Row Challenge)”
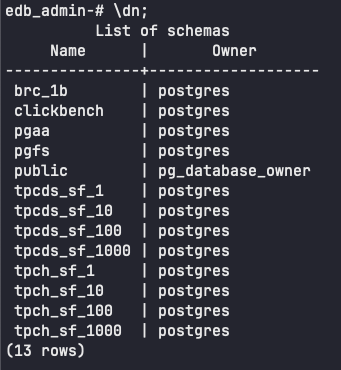
psql에서 \dn 명령을 실행하면 사용 가능한 스키마를 확인할 수 있습니다.
edb_admin> select count(*) from clickbench.hits;
+----------+
| count |
|----------|
| 99997497 |
+----------+
SELECT 1
Time: 0.945s
edb_admin> select count(*) from brc_1b.measurements;
+------------+
| count |
|------------|
| 1000000000 |
+------------+
SELECT 1
Time: 0.651s
이처럼 쿼리 속도가 매우 빠른 이유는 Analytics Accelerator의 count 연산이 메타데이터만 읽는 방식으로 처리되기 때문입니다. 실제 데이터나 인덱스를 스캔하지 않아도 되므로 데이터 크기와 관계없이 일정한 성능을 유지합니다.
복잡한 쿼리 실행
Analytics Accelerator는 단순 count뿐 아니라 Postgres SQL 전반에 대해 호환성 있는 분석 처리를 지원합니다. 대부분의 경우 분석 엔진이 전체 쿼리를 처리하고, 그렇지 않은 경우 기본 Postgres 엔진으로 자동 전환됩니다.
예를 들어 TPC-H 데이터를 대상으로 다음과 같은 복잡한 집계 쿼리를 실행해보겠습니다:
edb_admin> SELECT
s_suppkey,
s_name,
s_address,
s_phone,
total_revenue
FROM
supplier,
(
SELECT
l_suppkey AS supplier_no,
sum(l_extendedprice * (1 - l_discount)) AS total_revenue
FROM
lineitem
WHERE
l_shipdate >= CAST('1996-01-01' AS date)
AND l_shipdate < CAST('1996-04-01' AS date)
GROUP BY
supplier_no) revenue0
WHERE
s_suppkey = supplier_no
AND total_revenue = (
SELECT
max(total_revenue)
FROM (
SELECT
l_suppkey AS supplier_no,
sum(l_extendedprice * (1 - l_discount)) AS total_revenue
FROM
lineitem
WHERE
l_shipdate >= CAST('1996-01-01' AS date)
AND l_shipdate < CAST('1996-04-01' AS date)
GROUP BY
supplier_no) revenue1)
ORDER BY
s_suppkey;
s_suppkey | s_name | s_address | s_phone | total_revenue
-----------+--------------------+-------------------+-----------------+---------------
8449 | Supplier#000008449 | 5BXWsJERA2mP5OyO4 | 20-469-856-8873 | 1772627.2087
(1 row)
Time: 634.689 ms
634ms 만에 여러 테이블의 데이터를 조인하고, 집계하고, 정렬하는 작업을 모두 수행한 쿼리 결과가 반환되었습니다.
Lakehouse 테이블 질의
Lakehouse 테이블은 데이터 웨어하우스와 데이터 레이크의 장점을 결합한 최신 데이터 저장 방식입니다. 이 테이블은 Parquet라는 컬럼 지향 포맷으로 저장되며, 분석 엔진이 쿼리에 필요한 특정 열만 읽을 수 있도록 해 쿼리 성능을 최적화합니다. 또한 필요한 바이트 범위만 읽을 수 있도록 메타데이터를 제공하여 전체 행을 스캔할 필요 없이 효율적인 쿼리가 가능합니다. 이 컬럼 기반 구조는 대규모 데이터셋에서 특정 컬럼을 분석, 집계, 요약하는 분석 워크로드에 특히 유리합니다.
Analytics Accelerator는 Apache Iceberg 및 Delta Lake와 같은 인기 있는 오픈 테이블 포맷에 대한 쿼리를 지원합니다. 이들 포맷은 다중 작성자 환경에서의 ACID 트랜잭션, 스키마 진화, 다양한 쿼리 엔진 및 도구와의 상호운용성 등 중요한 기능을 제공합니다. 또한 데이터 파일과는 별도로 메타데이터를 저장함으로써 대규모 환경에서의 효율적인 데이터 관리를 가능하게 합니다.
Lakehouse 노드에 설치된 PGAA(Postgres AI Accelerator) 확장은 Postgres가 S3, MinIO, Azure Blob Storage와 같은 오브젝트 스토리지 시스템에서 이러한 Lakehouse 테이블을 직접 읽을 수 있게 해줍니다. PGAA는 벡터화된 쿼리 처리(vectorized query processing) 방식을 통해 행 단위가 아닌 배치(batch) 단위로 연산을 수행함으로써 분석 워크로드의 성능을 크게 향상시킵니다. 덕분에 사용자는 친숙한 Postgres SQL 인터페이스를 통해 페타바이트 규모의 데이터셋에 질의하면서도 전용 데이터 웨어하우스와 견줄 만한 성능을 얻을 수 있습니다.
이제 HM에서 새로 프로비저닝한 Lakehouse 노드를 활용해 Lakehouse 테이블에 질의해보겠습니다.
Iceberg 테이블 질의
S3 호환 오브젝트 스토리지에 적절한 권한으로 저장된 여러 개의 Apache Iceberg 테이블이 있다고 가정하겠습니다. 먼저, 직접 접근(direct access) 방식으로 질의하는 방법을 설명하고, 이후에는 Iceberg REST 카탈로그를 통한 접근 방식도 살펴보겠습니다.
1단계: PGFS(Postgres File System)를 사용한 스토리지 위치 생성
PGFS는 이미 Lakehouse 노드에 설치되어 있으며, PostgreSQL과 오브젝트 스토리지(또는 POSIX 파일시스템) 간의 인터페이스를 제공합니다. PGFS를 사용하면 오브젝트 스토리지 위치를 PostgreSQL 내부의 가상 파일 시스템으로 마운트할 수 있어 데이터베이스와 데이터 레이크 간에 자연스러운 통합이 이루어집니다. Iceberg 및 Delta 형식의 테이블을 질의하기 위해서는 이 연결이 필수입니다.
SELECT pgfs.create_storage_location(
name => 'my_s3_iceberg_data',
url => 's3://your-bucket/path/to/iceberg',
options => '{}',
credentials => '{"access_key_id": "...", "secret_access_key": "..."}'
);
2단계: Iceberg 외부 테이블 생성
CREATE TABLE public.my_sales_iceberg_data (
sales_id INT,
sales_date DATE,
sales_amount NUMERIC
)
USING PGAA
WITH (
pgaa.storage_location = 'my_s3_iceberg_data',
pgaa.path = 'sales_records/iceberg_table_root',
pgaa.format = 'iceberg'
);
이제 Iceberg 테이블이 Postgres에서 접근 가능해졌으며, 다음과 같이 일반 SQL로 쿼리할 수 있습니다:
SELECT * FROM public.my_sales_iceberg_data
WHERE sales_region = 'North America'
LIMIT 100;
위 예시처럼 오브젝트 스토리지에 있는 Iceberg 테이블 경로를 직접 참조하여 접근하는 방식은 다음과 같은 이점을 제공합니다:
- 단순성: 별도의 카탈로그 서비스가 필요 없음
- 의존성 최소화: 스토리지 위치와 자격 증명만 필요
- 빠른 접근성: Ad-hoc 쿼리나 탐색에 적합하며 운영 부담이 적음
Iceberg REST 카탈로그를 통한 질의
다른 방법으로는 Iceberg REST 카탈로그를 사용하는 것입니다. 이는 Iceberg 테이블의 메타데이터를 관리하여 다양한 컴퓨팅 엔진 간의 데이터 탐색, 접근, 버전 관리를 가능하게 합니다. 테이블 위치, 스키마, 스냅샷, 파티셔닝 정보를 저장하여 Spark, Trino, Flink 같은 엔진과의 원활한 통합을 지원합니다.
Iceberg 카탈로그를 사용할 경우 다음과 같은 추가 이점이 있습니다:
- 테이블 탐색: 모든 테이블 목록 유지
- 스키마 진화 추적: 시간에 따른 변경 이력 관리
- 메타데이터 관리 최적화
- 중앙 집중형 권한 관리
- 트랜잭션 조정: 다중 작성자 환경에서의 ACID 보장
Iceberg REST Catalog 표준을 구현한 카탈로그는 다음과 같은 예시가 있습니다:
- Snowflake Open Catalog
- Databricks Unity Catalog
- AWS S3Tables
- Lakekeeper – HM 내에서 관리형 서비스로 제공됨
카탈로그 설정이 완료되면 다음과 같이 PGAA를 통해 Lakehouse 노드에 등록할 수 있습니다:
SELECT pgaa.add_catalog(
'hm_lakekeeper_main',
'iceberg-rest',
'{
"url": "<https://hm.example.com/catalog/v1>",
"token": "your_hm_api_key",
"warehouse": "lakehouse_warehouse_1"
}'
);
HM Console의 Catalogs 섹션에서 클러스터에 대한 카탈로그 구성 정보를 확인할 수 있습니다.
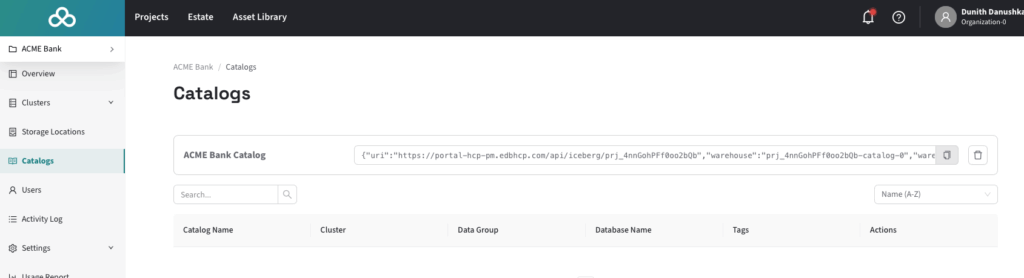
이후, 아래와 같이 pgaa.attach_catalog() 명령을 실행하여 카탈로그 테이블을 Postgres에 연결할 수 있습니다:
SELECT pgaa.attach_catalog('your_catalog_alias');
이 명령은 Postgres 카탈로그를 Iceberg REST 카탈로그와 동기화하는 백그라운드 프로세스를 시작합니다. 상위 카탈로그에서 테이블이 추가, 삭제, 변경되면 Postgres에도 반영됩니다. 동기화를 원하지 않을 경우 import_catalog()를 사용하여 메타데이터를 한 번만 가져오는 방식도 가능합니다.
또한, 아래와 같이 수동으로 테이블을 추가할 수도 있습니다:
CREATE TABLE public.catalog_managed_sensor_data (
device_id TEXT,
event_time TIMESTAMP WITH TIME ZONE,
temperature FLOAT,
humidity FLOAT
)
USING PGAA
WITH (
pgaa.format = 'iceberg',
pgaa.managed_by = 'your_catalog_alias',
pgaa.catalog_namespace = 'iot_data',
pgaa.catalog_table = 'hourly_sensor_readings'
);
운영 환경에서는 카탈로그 기반 방식이 권장됩니다. 정책, 표준, 제어를 통한 데이터 거버넌스와 스키마 진화, 멀티 유저 환경 지원이 훨씬 강력하기 때문입니다. 반면, 앞서 소개한 직접 연결 방식은 카탈로그 인프라 없이도 빠르게 탐색하거나 단순한 테스트 용도로 적합합니다.
Delta 테이블 질의
Delta 테이블 쿼리는 Iceberg와 거의 동일하지만, 현재로선 카탈로그를 사용하지 않고 직접 접근 방식만 지원합니다. 향후에는 Delta 테이블도 Iceberg REST 카탈로그를 통해 관리하는 기능이 추가될 가능성이 있습니다.
S3 호환 오브젝트 스토리지에 Delta 테이블이 저장되어 있고, HM에서 Lakehouse 노드가 프로비저닝되어 있다고 가정합니다.
1단계: 스토리지 위치 생성
SELECT pgfs.create_storage_location(
name => 'my_public_delta_lake_store',
url => 's3://my-public-delta-data/',
options => '{"aws_skip_signature": "true"}',
credentials => '{}'
);
2단계: Delta 테이블 외부 테이블 생성
CREATE TABLE public.sales_delta_table ()
USING PGAA
WITH (
pgaa.storage_location = 'my_private_delta_lake_assets',
pgaa.path = 'path/to/delta_table_root/',
pgaa.format = 'delta'
);
3단계: 일반 SQL로 질의 실행
SELECT order_id, customer_name, sale_amount
FROM public.sales_delta_table
WHERE sale_date >= '2023-01-01'
AND product_category = 'Electronics'
LIMIT 100;
Tiered Tables로 오래된 데이터 오프로드
지금까지는 Analytics Accelerator가 Lakehouse 테이블을 읽는 기능에 대해 살펴봤습니다. 이제는 쓰기 기능인 Tiered Tables를 소개합니다.
Tiered Tables는 EDB Postgres AI의 고가용성 구성을 기반으로 하며, 시간 기반 대용량 데이터셋을 효율적으로 관리합니다. “콜드 데이터”는 저비용 오브젝트 스토리지로 옮기고, “핫 데이터”는 트랜잭션 스토리지에 유지합니다. 이 과정은 자동화하거나 쿼리 조건에 따라 수동으로 실행할 수 있습니다.
Tiered Tables는 다음을 통해 구현됩니다:
- PGD AutoPartition: 자동 파티셔닝 및 수명 주기 제어
- PGAA 및 PGFS: 오프로드된 데이터 질의 및 접근
- (선택사항) Iceberg 카탈로그: 데이터 거버넌스 및 상호운용성 확보
마무리하며
이번 튜토리얼에서는 EDB Postgres AI Analytics Accelerator의 강력한 기능을 살펴보며, Postgres를 고성능 분석 엔진으로 탈바꿈시키는 방법을 알아봤습니다. Iceberg 및 Delta Lake 테이블을 오브젝트 스토리지에서 직접 질의하고, PGAA 확장을 활용해 페타바이트급 데이터셋을 벡터 처리 방식으로 분석할 수 있었습니다.
또한, Tiered Tables를 통해 콜드 데이터를 자동으로 저렴한 스토리지로 이전하고, 모든 계층에 걸쳐 끊김 없는 쿼리 액세스를 유지하는 기능도 소개했습니다. ETL 파이프라인 없이 트랜잭션과 분석 워크로드를 단일 인터페이스에서 다룰 수 있는 Analytics Accelerator는 Postgres의 안정성과 최신 분석 성능 및 Lakehouse 유연성을 결합한 획기적인 데이터베이스 기술입니다.
위 단계들을 직접 따라 해보시려면, 먼저 **Postgres AI Hybrid Manager(HM)**를 설치하고 HM Console에 접속하세요
문의 메일: salesinquiry@enterprisedb.com
