
CloudNativePG 튜토리얼: 멀티 클라우드 네이티브 데이터베이스 관리
EDB 팀
2024년 10월 14일
Kubernetes에서 CloudNativePG로 데이터베이스 관리 간소화하기
오늘날 Kubernetes는 마이크로서비스로 가득 찬 복잡한 앱 스택부터 최신 “서버리스” API까지, 완전히 오케스트레이션된 에코시스템을 배포할 수 있는 훌륭한 범용 플랫폼입니다. Postgres가 이 흥미진진한 새로운 영역의 새로운 주자는 아니지만, 확실히 진화하고 있는 것은 사실입니다. 이는 어떤 식으로든 Postgres DBA가 최신 기술을 수용하기 위해 시야를 넓혀야 한다는 것을 의미합니다.
그렇다면 새롭고 불안한 현대 사회에서 DBA가 해야 할 일은 무엇일까요? 실제로 어떻게 Postgres를 Kubernetes 스택에 설치하며, 그 이후에는 어떻게 될까요?
간단한 소개
Kubernetes에서 Postgres를 효과적으로 활용하려면 관련된 모든 리소스, 장애 조치, 연결 풀, 비밀 관리 등 다양한 구성 요소를 제어할 수 있는 운영자가 필요합니다. Postgres 업계의 주요 업체들은 각기 다른 강점을 가진 운영자를 제공하며, EDB도 예외는 아닙니다. EDB의 CloudNativePG는 현재 유일한 “네이티브” Kubernetes 운영자로, Go 언어로 작성되었으며 여러 네이티브 Kubernetes 인터페이스를 피어 서비스로 호출할 수 있다는 점이 가장 큰 강점입니다.
EDB는 2022년 4월 22일 CloudNativePG를 공식 발표했지만, 그 이전부터 1년 이상 개발 작업이 진행되었습니다. 첫 번째 1.0 버전은 2021년 2월 4일에 출시되었으며, 이는 현재의 제품 이전 단계였던 프로토타입이나 기타 독점적인 내부 제품은 포함하지 않습니다. 사실, 2020년 초에는 이미 BDR 운영자를 선보인 바 있습니다. 가브리엘 바르톨리니는 이러한 긴 여정을 자신의 블로그에서 상세히 설명했는데, 그 과정은 정말 다사다난했던 몇 년의 기록이라 할 수 있습니다.
이 정도의 개발 역사를 가지고 있다면 사용하기도 꽤 쉬울 것 같지 않나요? 한번 살펴봅시다
쿠버네티스 크래시 코스
무언가를 배우는 가장 좋은 방법은 직접 사용해 보는 것입니다. Kubernetes의 높은 인기 덕분에 사용할 수 있는 다양한 유사 도구들이 존재합니다. 가장 간단한 방법은 Docker 컨테이너에서 전체 Kubernetes 인스턴스를 실행할 수 있는 kind를 사용하는 것입니다. 그다음으로는 비슷한 방식이지만 가상 머신 기반 환경을 선호하는 minikube가 있습니다. 또한, “진짜” Kubernetes(k8s)의 경량화된 버전인 K3s도 선택지 중 하나입니다. K3s는 Kubernetes와 거의 동일하게 동작하지만, 더 간소화된 설정을 제공합니다.
순수하게 실험 목적으로는 위의 도구들 중 어느 것을 사용해도 충분합니다. 더 도전적이고 실제적인 경험을 원하는 분들에게는 K3s가 완전히 작동하는 클러스터를 손쉽게 구성할 수 있어 보다 “현실적인” Kubernetes 환경을 체험할 수 있는 좋은 선택이 될 것입니다. 그렇다면 이러한 경험은 무엇을 포함할까요?
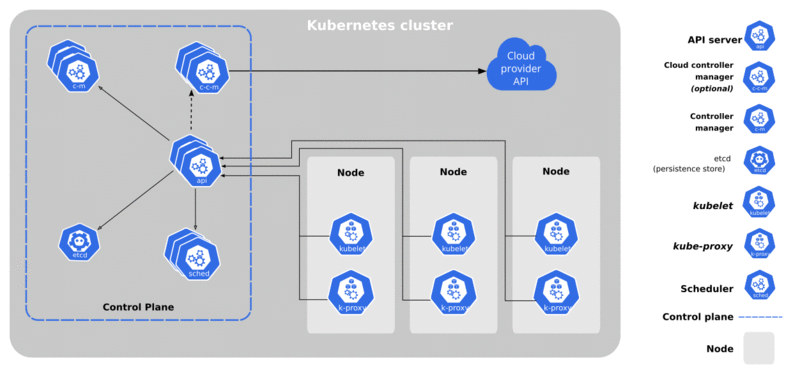
복잡해 보이기 때문에 복잡하게 느껴질 수 있습니다. 하지만 실제로는 컨트롤 플레인과 워커 노드, 이 두 가지만 신경 쓰면 됩니다. 컨트롤 플레인은 일반적으로 3~5개의 노드로 구성되며, 기본적으로 모든 워커 노드에 수행할 작업, 서비스 배포 위치, 쿼럼 유지 방법 등을 지시합니다. 컨트롤 플레인을 잃는다는 것은 전체 클러스터를 잃는다는 것을 의미하므로, 이 시스템을 안정적으로 유지하는 것이 매우 중요합니다. 워커 노드는 일반적으로 실제 애플리케이션, 컴퓨팅, 스토리지 등의 호스팅과 관련된 다른 모든 작업을 처리합니다.
이 중 하나를 설정하고 실행하는 방법은 이 글의 범위를 벗어나지만, 블로그, 튜토리얼, 도구, YouTube 동영상 등 참고 자료가 많습니다. Ansible에 익숙한 사용자라면 표준화된 방식으로 모든 것을 반복 배포할 수 있는 훌륭한 도구인 Kubespray를 사용할 수 있습니다.
필수적인 도구로는 Kubernetes 클러스터를 관리하기 위한 명령줄 유틸리티인 kubectl이 있습니다. 또한, 많은 관리자들이 Kubernetes의 패키지 관리 도구로 Helm을 사용하며, 이는 매우 편리하게 활용할 수 있습니다.
이제 클러스터를 설정하고 실행했다면, 다음 단계는 무엇일까요?
또 다른 마크업 언어
YAML은 Kubernetes의 표준 언어이기 때문에 익숙해지는 것이 중요합니다. 이 글을 작성하는 시점에서 CloudNativePG의 최신 버전은 1.22입니다. 설치 지침은 해당 버전과 연결되어 있으며, 설명서에서 쉽게 찾을 수 있습니다. 그리고 그 지침은 신뢰할 수 있습니다. CloudNativePG를 설치하는 데 필요한 것은 단 한 줄의 명령어뿐입니다.
운영자를 설치하고 확인하는 방법은 다음과 같습니다:
$> kubectl apply -f https://raw.githubusercontent.com/cloudnative-pg/cloudnative-pg/release-1.22/releases/cnpg-1.22.1.yaml
$> kubectl get deployment -n cnpg-system
NAME READY UP-TO-DATE AVAILABLE AGE
cnpg-controller-manager 1/1 1 1 26h믿기 어렵겠지만, 이 시점에서 우리가 해야 할 일은 배포할 클러스터에 대한 구성을 작성하는 것뿐입니다. 이는 복잡한 작업처럼 들릴 수 있지만, 문서가 큰 도움을 줄 것입니다. 문서에는 사용할 수 있는 다양한 매개변수와 구성 요소, 그리고 어떤 옵션을 선택할 수 있는지에 대한 기능 예제가 포함되어 있습니다.
여기서 우리는 약간의 창의력을 발휘했습니다. 롱혼(Longhorn)은 Kubernetes에서 가장 인기 있는 스토리지 클래스 중 하나로, 증분 백업, 스냅샷, 블록 복제 등 최신 스토리지 관련 기능 대부분을 지원하는 객체 스토리지입니다. 그러나 CloudNativePG 문서에 따르면 이러한 유형의 스토리지를 사용할 경우 볼륨 복제를 효과적으로 비활성화해야 합니다.
이를 간단히 해결하는 방법은, 특정 옵션만 변경된 두 번째 스토리지 클래스를 만드는 것입니다. 이 새로운 스토리지 클래스 정의를 작성한 후, kubectl apply -f 명령어를 사용해 적용했습니다.
apiVersion: v1
kind: ConfigMap
metadata:
name: longhorn-storageclass-1r
namespace: longhorn-system
labels:
app.kubernetes.io/name: longhorn
app.kubernetes.io/instance: longhorn
app.kubernetes.io/version: v1.5.3
data:
storageclass.yaml: |
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: longhorn-1r
annotations:
storageclass.kubernetes.io/is-default-class: "true"
provisioner: driver.longhorn.io
allowVolumeExpansion: true
reclaimPolicy: "Delete"
volumeBindingMode: Immediate
parameters:
numberOfReplicas: "1"
staleReplicaTimeout: "30"
fromBackup: ""
fsType: "ext4"
dataLocality: "disabled"표준 Longhorn 스토리지 클래스 정의를 가져와 새 항목으로 생성되도록 이름을 변경한 뒤, 복제본 수를 1로 줄였습니다. 즉, 데이터의 복사본이 단 하나만 존재하게 됩니다. 각 Postgres 복제본은 자체 데이터 폴더의 전체 복사본을 가지고 있기 때문에, 이 접근 방식은 문제 없으며 오히려 Postgres에 잘 맞는 설정입니다. 복제본 수를 표시하기 위해 이름에 “1r”을 추가했는데, 나름대로 창의적인 방식이라고 할 수 있습니다.
Postgres Kubed
이제 Kubernetes 환경에 Postgres 클러스터를 추가할 차례입니다. 적절한 균형을 갖춘 정의를 마련했으니, 이를 구성하는 여러 섹션을 살펴보겠습니다.
먼저 서문부터 시작하겠습니다:
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: test-cnpg-cluster
namespace: cloudnative-pg이 클러스터의 이름은 “test-cnpg-cluster”로 지정할 계획입니다. 기본적으로 CloudNativePG는 클러스터를 “default” 네임스페이스에 배포하지만, 우리는 좋은 Kubernetes 사용자가 되기 위해 별도의 네임스페이스를 사용하기로 했습니다. 이후의 모든 내용은 실제 클러스터 정의에 대한 세부 사항을 설명합니다.
spec:
instances: 3
bootstrap:
initdb:
database: bones
owner: bones클러스터 정의의 모든 구성 요소는 파일의 “spec” 섹션에 배치해야 합니다. 이번에는 세 개의 멤버로 구성된 클러스터를 생성하기로 결정했습니다. 또한 기본적으로 생성되는 “app” 데이터베이스를 사용하지 않기로 하고, 대신 원하는 데이터베이스를 선택한 뒤 기본 데이터베이스 소유자를 변경했습니다.
그다음으로는 몇 가지 Postgres 구성 매개변수를 약간 조정하려고 합니다:
postgresql:
parameters:
random_page_cost: "1.1"
log_statement: "ddl"
log_checkpoints: "on"우리 Kubernetes 클러스터는 빠르고 성능 좋은 SSD 스토리지에 액세스할 수 있으므로, 임의 페이지를 검색하는 데 드는 비용을 줄이는 것이 합리적입니다. 또한, 데이터베이스를 수정하는 모든 트랜잭션과 포렌식 목적으로 활용할 수 있는 체크포인트를 로깅하는 것도 유용합니다.
이 섹션에는 거의 모든 유효한 Postgres 구성 매개변수를 추가할 수 있으며, 이러한 설정은 클러스터에 정확하게 적용됩니다. 향후 매개변수를 추가하거나 변경할 경우, 운영자는 변경 사항에 따라 각 노드에 다시 로드하거나 필요하면 재시작을 수행해 변경을 반영합니다.
affinity:
nodeSelector:
longhorn: "true"노드 선호도를 설정하는 것은 애플리케이션과 스토리지가 위치해야 할 노드를 지정하는 Kubernetes의 다소 복잡한 기술 중 하나입니다. 이번에는 복잡한 분포 전략, 밸런스 점수, 또는 기타 고급 기능에 의존하기보다는 간단한 접근 방식을 택했습니다. Kubernetes에서는 관리 목적으로 노드에 다양한 태그를 레이블로 지정할 수 있는데, 우리는 이를 활용해 모든 노드가 Longhorn 스토리지를 사용하도록 설정했습니다. 프로덕션 환경에서는 보통 필수 서비스가 요구되는 노드로 구성되기 때문에, 이러한 설정은 “데이터베이스”를 대상으로 할 계획입니다.
그리고 Longhorn에 대해 말하자면:
storage:
storageClass: longhorn-1r
size: 100Gi
walStorage:
storageClass: longhorn-1r
size: 20Gi
기본 스토리지 대신 이 클러스터가 우리가 만든 특별한 “longhorn-1r” 스토리지 클래스를 사용하도록 설정했습니다. 또한 모든 유능한 Postgres DBA가 그렇듯, 데이터와 WAL(Write-Ahead Logging) 할당을 분리했습니다.
이제 클러스터를 배포하기만 하면 됩니다:
kubectl create namespace cloudnative-pg
kubectl apply -f test-cnpg-cluster.yaml클러스터는 1~2분 이내에 가동되고 실행될 것입니다. 간단하죠? 약 30줄의 YAML과 두 개의 명령어만으로 3개의 노드에 분산된 완전한 내결함성(Fault Tolerance)과 고가용성(High Availability)을 갖춘 클러스터를 생성할 수 있습니다. 그리고 이 모든 과정을 5분도 채 걸리지 않아 완료할 수 있습니다! 다른 방법으로 이만큼 간단하게 해보세요.
액세스 얻기
클러스터를 배포하는 것과 실제로 클러스터에 액세스하는 것은 완전히 별개의 문제입니다. CloudNativePG는 각 클러스터에 대해 클러스터 이름을 기반으로 세 가지 서비스를 생성합니다. 우리의 경우는 다음과 같습니다:
test-cnpg-cluster-rw: 항상 기본(primary) 노드를 가리킵니다.test-cnpg-cluster-ro: 라운드 로빈 방식으로 선택된 복제(replica) 노드만 가리킵니다.test-cnpg-cluster-r: 라운드 로빈 방식으로 클러스터의 모든 노드를 가리킵니다.
Kubernetes는 자체 DNS를 통해 이러한 별칭을 라우팅하기 때문에, 이 이름들을 사용해 원하는 대로 연결할 수 있습니다. 애플리케이션이 클러스터와 동일한 네임스페이스에 있지 않은 경우, 네임스페이스를 FQDN처럼 취급해야 합니다. 예를 들어, 다른 네임스페이스에서 cloudnative-pg 네임스페이스의 기본 노드에 연결하려면 test-cnpg-cluster-rw.cloudnative-pg를 사용해야 합니다.
애플리케이션에서의 연결에 대한 자세한 내용은 문서를 참조하십시오. 그러나 만약 Kubernetes 외부의 레거시 애플리케이션이 있거나 직접 연결해야 하는 상황이 있다면 어떻게 해야 할까요? Kubernetes에서는 이러한 문제를 해결하는 다양한 방법을 제공합니다. CloudNativePG 문서에서는 Postgres 서비스를 외부에 노출하는 방법에 대한 섹션이 있으며, Kubernetes가 외부 액세스를 적절한 서비스로 라우팅하도록 인그레스(Ingress) 방법을 정의하는 것이 핵심입니다.
이 작업은 ingress-nginx, Traefik, MetalLB 또는 다른 널리 사용되는 여러 인그레스 레이어를 통해 수행할 수 있습니다. 홈 환경에서는 이 중 하나 이상이 설치되어 있을 가능성이 큽니다. 우리는 내부 서비스에 고정 IP를 연결하는 가장 간단한 방법 중 하나로 MetalLB를 선택했습니다. 경로를 생성하는 과정은 kubectl 명령어 하나로 간단히 처리할 수 있습니다:
kubectl -n cloudnative-pg expose service test-cnpg-cluster-rw \
--name=test-cnpg-bones-lb --port=5432 --type=LoadBalancer이 명령어의 장점은 Kubernetes가 요청을 처리하는 방법에 대해 따로 지정하거나 신경 쓸 필요가 없다는 것입니다. 호환되는 LoadBalancer 유형만 있다면 기본 클러스터 서비스를 외부로 노출하고 IP를 할당합니다. 이 명령으로 생성된 서비스 목록은 다음과 같습니다:
NAME TYPE EXTERNAL-IP PORT(S)
test-cnpg-bones-lb LoadBalancer 10.0.5.101 5432:32631/TCP
Test-cnpg-cluster-r ClusterIP <none> 5432/TCP
test-cnpg-cluster-ro ClusterIP <none> 5432/TCP
test-cnpg-cluster-rw ClusterIP <none> 5432/TCP이름이 올바르게 지정되고 IP 주소에 연결된 새로운 서비스가 생성된 것을 확인할 수 있습니다. 이제 이 서비스를 통해 클러스터에 연결할 수 있지만, 다음 문제가 발생합니다. 비밀번호는 무엇인가요?
CloudNativePG는 비밀번호를 지정하지 않으면 자동으로 비밀번호를 생성하여 Kubernetes의 시크릿(Secret)에 저장합니다. 해당 비밀번호는 소유자만 액세스할 수 있도록 보호되며, 이를 확인하기 위해서는 몇 가지 단계를 거쳐야 합니다.
클러스터에 Rancher와 같은 프론트엔드 관리 도구가 있다면, 인터페이스를 통해 쉽게 시크릿을 복사할 수 있습니다. 그렇지 않다면 kubectl 명령어를 사용해 필요한 정보를 확인할 수 있습니다:
$> kubectl -n cloudnative-pg get secret
NAME TYPE DATA AGE
test-cnpg-cluster-app kubernetes.io/basic-auth 9 71m
test-cnpg-cluster-ca Opaque 2 71m
test-cnpg-cluster-replication kubernetes.io/tls 2 71m
test-cnpg-cluster-server kubernetes.io/tls 2 71m인증서 관련 항목을 제외하고, test-cnpg-cluster-app 시크릿에 사용자 이름과 비밀번호가 포함되어 있습니다. 비밀번호를 확인하려면 다음 명령어를 사용하십시오:
kubectl get secret test-cnpg-cluster-app \
-o=jsonpath='{.data.password}' | base64 -d얻은 비밀번호를 PGPASSWORD 환경 변수로 내보내거나, psql 또는 pgAdmin의 비밀번호 프롬프트에 붙여넣으면 됩니다. 이제 클러스터에 연결할 준비가 되었습니다:
$> export PGPASSWORD=<snip>
$> psql -h 10.0.5.101 -U bones -d bones
psql (16.2 (Ubuntu 16.2-1.pgdg22.04+1))
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, bits: 256, compression: off)
Type "help" for help.
bones=>성공!
마무리하며
다룰 수 있는 주제는 여전히 많지만, 이 글에서 마무리하려 합니다. CloudNativePG는 현재 클러스터 상태 관리를 위해 Patroni에 의존하지 않는 유일한 Kubernetes 운영자입니다. 이를 통해 장애 조치 관리, 퍼시스턴트 볼륨 클레임 프로비저닝, 시스템 스냅샷 처리, 로드 밸런싱, 그리고 운영자 수준에서만 활용할 수 있는 다양한 고급 기능을 직접 사용할 수 있습니다. 가브리엘과 그의 팀은 지난 5년간 멈추지 않고 혁신을 이어왔으며, EDB가 Postgres와 Kubernetes를 결합하는 데 전념할 수 있도록 큰 기여를 하고 있습니다.
이 글을 통해 Kubernetes와 CloudNativePG에 대한 사전 지식이 거의 없던 상태에서 전체 클러스터를 배포하고 액세스하는 방법까지 배울 수 있었습니다. 이제 다음 단계는 cnpg kubectl 플러그인을 설치해 Postgres 클러스터 관리 작업을 한층 더 간소화하는 것입니다.
DBA로서 우리의 여정은 끝나지 않았으며, 우리가 다루는 에코시스템은 지속적으로 변화하고 있습니다. 복잡하게 느껴질 수 있지만, Kubernetes는 우리가 기존에 수행하던 많은 작업을 상당히 단순화합니다. 더 이상 복잡한 HA 스택을 구성하거나 쿼럼, 펜싱 규칙, 헬퍼 스크립트, 라우팅 등을 모든 노드에 올바르게 적용하기 위해 애쓸 필요가 없습니다. 이제는 개별 노드와 씨름하지 않고도, 클러스터를 클러스터로서 관리할 수 있습니다.
물론 Kubernetes가 작동하는 방식과 특히 CloudNativePG와 관련된 기본 인프라를 충분히 이해하는 것은 여전히 중요합니다. 이를 위해 공식 문서를 활용하거나 인터넷에서 수십 개의 Kubernetes 블로그, 튜토리얼, YouTube 동영상을 참고할 수 있습니다. 필요한 정보를 찾고자 노력한다면 충분한 자료를 얻을 수 있을 것입니다.
현재로서 Postgres의 미래는 빠르게 다가오고 있으며, EDB는 이를 실현하는 데 중요한 역할을 하고 있습니다. CloudNativePG의 흥미로운 개발 역사를 자세히 다룬 통찰력 있는 블로그 게시물을 통해 그 여정을 살펴보세요. 이렇게 풍부한 배경을 가진 만큼, 실제 사용법도 매우 간단합니다. 자세히 알아보세요!
본문: CloudNativePG Tutorial: Manage Multiple Cloud-Native Databases
EDB 영업 기술 문의: 02-501-5113
이메일: salesinquiry@enterprisedb.com

