
CloudNativePG 복제 슬롯 관리: Kubernetes 환경에서 PostgreSQL 고가용성과 자가 복구
CloudNativePG가 Kubernetes에서 PostgreSQL을 위한 물리적 복제 슬롯을 관리하는 방법
가브리엘 바르톨리니
11월 12, 2024
자가 복구는 Kubernetes의 핵심 원칙 중 하나입니다. Postgres 데이터베이스 클러스터에서 자가 복구는 주로 기본 인스턴스를 복원하는 데 초점이 맞춰져 있으며, 스트리밍 복제본의 상태는 종종 간과됩니다. 그러나 복제본은 장애 발생 시 CloudNativePG에 의해 자동으로 기본 인스턴스로 승격될 수 있으므로, Postgres 클러스터의 고가용성과 자가 복구에 중요한 역할을 합니다.
WAL 아카이브 또는 PostgreSQL 복제 슬롯을 사용하지 않으면, 스트리밍 복제본은 기본 인스턴스와의 동기화를 잃을 수 있으며, 이로 인해 복제본을 다시 시작할 수 없게 됩니다. 이러한 상황에서는 자가 복구가 불가능하며, 복제를 복구하려면 수동 개입이 필요합니다.
이 문제를 해결하기 위해 CloudNativePG는 하나 이상의 핫 스탠바이 복제본으로 구성된 고가용성 Postgres 클러스터에서 물리적 복제 슬롯을 관리하고, 장애 조치 이후에도 이를 유지할 수 있는 자동화된 메커니즘을 제공합니다. Postgres 용어로 이 기능은 “물리적 장애 조치 슬롯” 또는 간단히 “장애 조치 슬롯”으로 불립니다. 이 기능은 복제본의 자가 복구 능력을 강화해 Postgres 클러스터 전체의 복구 가능성을 크게 향상시킵니다.
이 블로그에서는 CloudNativePG가 물리적 장애 조치 슬롯을 구현하는 방법과 이를 통해 해결되는 문제에 대해 설명합니다. 과거에는 이 주제와 관련하여 PostgreSQL에 다양한 제안 패치가 논의되기도 했습니다. 해당 주제에 대해 더 자세히 알고 싶다면 아래의 추가 자료를 참조하세요:
CloudNativePG 복제 슬롯 정보 및 PostgreSQL 연동 원리
PostgreSQL의 복제 슬롯은 연결된 스트리밍 복제 클라이언트가 데이터를 수신할 때까지 기본 복제본이 WAL 세그먼트를 재활용하거나 삭제하지 않도록 하는 혁신적이고 자동화된 방식을 제공합니다. 이를 통해 일시적인 장애나 로그 애플리케이션 속도가 느려지는 상황에서도 복제본이 항상 다시 동기화될 수 있습니다. 즉, 대기 서버의 실제 사용량에 따라 유지해야 할 WAL 파일의 수를 자동으로 조절하며, 디스크 사용량 측면에서 효율성과 최적화를 제공합니다.
복제 슬롯은 2014년 PostgreSQL 9.4 버전에서 처음 도입된 이후 현재 지원되는 모든 PostgreSQL 버전에서 사용할 수 있습니다. 그 이전에는 wal_keep_segments(현재는 wal_keep_size)라는 구성 매개변수를 통해 시스템이 유지하는 고정된 WAL(Write-Ahead Logging) 파일 수를 조절함으로써 문제를 해결하곤 했습니다.
복제 슬롯은 이를 생성한 인스턴스에만 존재하며, PostgreSQL은 복제 슬롯을 대기 서버로 복제하지 않는다는 점에서 한계를 가집니다. 이로 인해 복제 슬롯은 클러스터를 인식하지 못하는데, 이는 장애 조치나 전환 후 새 기본 서버에 이전 기본 서버의 복제 슬롯이 포함되지 않는다는 것을 의미합니다. 가장 중요한 점은, 복제 슬롯이 없으면 새 기본 서버가 이미 WAL 파일을 재활용했을 가능성이 있다는 점이며, 이 경우 필요한 WAL 파일을 제공하지 못할 수 있습니다.
이로 인해 기존 기본 복제 클라이언트에 연결된 스트리밍 복제 클라이언트가 복제 슬롯을 잃게 되는 문제가 발생할 수 있습니다. 이는 앞서 언급했듯이 자가 치유 기능을 방해하며, 특히 쿠버네티스 환경에서는 이러한 문제가 더욱 중요하게 다뤄집니다.
CloudNativePG 복제 슬롯 도입 이전의 자가 복구 방식
마지막 문장을 읽으면서, 버전 1.18에서 복제 슬롯이 도입되기 전 CloudNativePG가 자가 복구를 어떻게 구현했는지 궁금해하실 것입니다. 이에 대한 답은 PostgreSQL의 연속 백업의 핵심 구성 요소인 WAL 아카이브에 의존했다는 점입니다.
프로덕션 데이터베이스 환경에서는 항상 연속 백업 설정이 권장되었기 때문에, 복제본은 아카이브를 통해 기본 데이터베이스에서 더 이상 접근할 수 없는 WAL 파일을 가져올 수 있었습니다. 이는 스트리밍 복제가 도입되기 전부터 PostgreSQL이 기본적으로 제공하던 기능으로, Postgres는 이러한 메커니즘을 활용해 자가 복구를 지원했습니다.
특히, pg_rewind는 장애 복구 후 이전 기본 서버를 손쉽게 재동기화할 수 있도록 설계된 도구로, WAL(Write-Ahead Logging) 아카이브를 적극 활용해 자가 복구를 가능하게 했습니다.
WAL 아카이브가 없는 경우, PostgreSQL 13 이상 버전에서는 wal_keep_size를, 이전 버전에서는 wal_keep_segments를 구성하여 문제를 완화할 수 있습니다. 이 구성을 적용하면 장애 조치 슬롯 없이도 CloudNativePG에서 자가 복구가 가능해집니다.
CloudNativePG 복제 슬롯(장애 조치 슬롯) 활성화 및 설정 방법
CloudNativePG에서 장애 조치 슬롯(failover slots)는 기본적으로 활성화되어 있지 않습니다. 다만, 이를 기본값으로 활성화하는 제안이 있으며, 이는 추후 버전(아마도 1.21)에서 구현될 가능성이 있습니다. 자세한 내용은 “Enable replication slots for HA by default #2673”을 참고하세요.
현재는 다음과 같이 .spec.replicationSlots.highAvailability.enabled를 true로 설정해 명시적으로 활성화해야 합니다.
apiVersion: postgresql .cnpg. io/v1
kind: Cluster
metadata :
name: freddie
spec:
instances: 3
storage :
size: 1Gi
walStorage :
size: 512Mi
replicationSlots :
highAvailability:
enabled : true
postgresql :
parameters :
max slot wal_keep size: '500MB'
hot_standby feedback: 'on'위 예시는 **기본(primary)**과 대기(standby) 인스턴스 두 개로 구성된 클러스터를 나타냅니다. 각각 1GB 크기의 PGDATA 볼륨과 512MB 크기의 WAL 볼륨을 가지고 있습니다. replicationSlots 항목에서 물리적 장애 조치 슬롯에 대한 지원을 명시적으로 활성화하고 있습니다.
또 다른 흥미로운 설정은 PostgreSQL 13 이상에서 사용할 수 있는 max_slot_wal_keep_size 매개변수입니다. 이 값을 500MB로 설정하면 Postgres는 복제 슬롯이 해당 크기에 도달할 경우 이를 자동으로 무효화합니다. 이는 디스크 공간 부족으로 인해 기본(primary) 서버가 중지되거나 자동 장애 조치(failover)가 발생하면서 연쇄적인 문제가 발생하는 것을 방지합니다. 이 설정에 대한 자세한 내용은 글의 마지막 부분에서 다루겠습니다.
CloudNativePG 복제 슬롯의 내부 동작 및 관리 메커니즘
클러스터가 배포되면 CloudNativePG는 각 복제본에 대해 기본(primary) 서버에 복제 슬롯을 생성합니다. 다음 명령으로 이를 확인할 수 있습니다:
kubectl exec -ti freddie-1 -c postgres -- psql -q -c "
SELECT slot_name, restart_lsn, active FROM pg_replication_slots
WHERE NOT temporary AND slot_type = 'physical'"
이 쿼리는 복제본당 활성 슬롯을 나타내는 두 개의 행을 반환합니다(여기서 “활성”은 현재 스탠바이가 연결되어 있음을 의미합니다):
slot_name | restart_lsn | active
------------------+-------------+--------
CNPG_FREDDIE_2 | 0/5056020 | t
CNPG_FREDDIE_3 | 0/5056020 | t
(2 rows)
CloudNativePG는 기본적으로 _cnpg_ 접두사를 사용해 이러한 복제 슬롯을 식별하지만, .spec.replicationSlots.highAvailability.slotPrefix 옵션을 통해 변경할 수 있습니다.
위의 물리적 복제 슬롯은 CloudNativePG에서 기본 서버(primary)에만 존재하므로, 이를 기본 HA 슬롯이라고 합니다. 각 기본 HA 슬롯은 특정 스트리밍 대기(standby) 서버와 연결되어 있으며, 생성부터 종료(예: 장애 조치 또는 전환)까지 클러스터의 현재 기본 서버에 의해 관리됩니다. 기본 HA 슬롯은 클러스터 복제 구조의 한 부분일 뿐입니다.
다른 한 축은 대기 HA 슬롯으로, 이는 대기 인스턴스에 존재하며 해당 대기 인스턴스에 의해 관리됩니다. 대기 HA 슬롯은 클러스터 내 다른 대기 인스턴스를 가리키는 물리적 복제 슬롯입니다.
이제 첫 번째 대기 서버에서 동일한 쿼리를 실행해 얼마나 많은 대기 HA 슬롯이 있는지 확인해 보겠습니다:
kubectl exec -ti freddie-2 -c postgres -- psql -q -c "
SELECT slot_name, restart_lsn, active FROM pg_replication_slots
WHERE NOT temporary AND slot_type = 'physical'"
이 쿼리는 비활성 슬롯 한 개만 반환합니다. 이는 대기 상태의 _cnpg_freddie_3 슬롯을 나타냅니다:
slot_name | restart_lsn | active
-----------------+-------------+--------
_cnpg_freddie_2 | 0/5056020 | f
(1 row)
내부적으로 각 대기 HA 슬롯은 인스턴스 관리자가 프라이머리의 pg_replication_slots 뷰에서 restart_lsn 값을 읽어와 pg_replication_slot_advance() 함수를 주기적으로 호출해 업데이트합니다. 이 업데이트의 기본 주기는 30초로 설정되어 있으며, .spec.replicationSlots.updateInterval 옵션을 통해 조정할 수 있습니다. 이러한 비동기 업데이트는 대기 상태의 슬롯 위치가 기본 상태의 값과 동일하거나 더 낮은 지연을 초래할 수 있지만, 시스템에 원치 않는 부작용을 주지는 않습니다. 또한 대기 HA 슬롯은 비활성 상태로, 스트리밍 클라이언트와 연결되어 있지 않습니다.
아래 다이어그램은 슬롯의 전체적인 구조를 보여줍니다.
장애 조치/전환 시 CloudNativePG 복제 슬롯의 동작과 복구 과정
이제 freddie-1 인스턴스가 다운되고, 가장 최신 상태의 복제본인 freddie-2가 새 기본 인스턴스로 승격되었다고 가정해 보겠습니다.
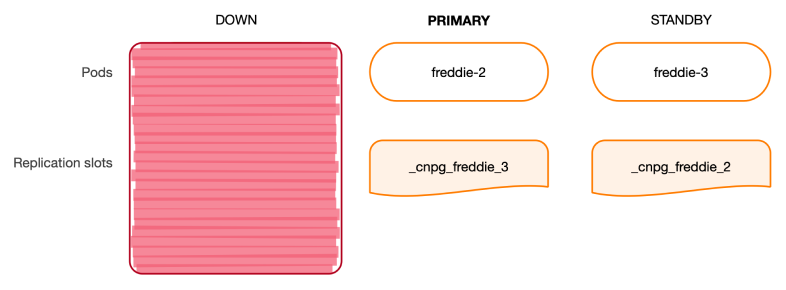
freddie-2의 인스턴스 관리자는 제어 중인 PostgreSQL 인스턴스를 새 기본(primary)으로 승격한 뒤, 필요한 기본 HA 슬롯이 로컬에 있는지 확인합니다.
즉, _cnpg_freddie_3(이미 존재하는 인스턴스)와 _cnpg_freddie_1(현재는 없지만 대기 상태로 전환될 것으로 예상되는 이전 기본 인스턴스)을 모두 점검합니다. 그 결과, 초기화되지 않은 복제 슬롯 _cnpg_freddie_1이 생성되어 이전 기본 복제본이 대기 상태로 전환되었을 때 이를 사용할 준비를 마칩니다. 초기화되지 않은 복제 슬롯은 로컬(primary) 서버의 pg_wal 공간을 차지하지 않습니다.
세 번째 노드 freddie-3는 freddie-2에 이미 존재하는 _cnpg_freddie_3 복제 슬롯을 이용해 새 기본 인스턴스를 따라잡기 시작합니다. 이 복제 슬롯은 현재 freddie-3에서 사용하는 복제 슬롯보다 동일하거나 더 앞선 위치를 유지하도록 보장됩니다. 따라서 freddie-2는 freddie-3이 새 기본 인스턴스에 연결되자마자 _cnpg_freddie_3의 위치를 자동으로 업데이트합니다.
동시에, freddie-2가 새 기본이 되었으므로 freddie-3는 로컬 복사본에서 _cnpg_freddie_2 슬롯을 제거하며 대기 HA 슬롯 목록을 업데이트합니다. freddie-2는 더 이상 대기 상태가 아니며, 기본(primary)으로 승격되었기 때문입니다.
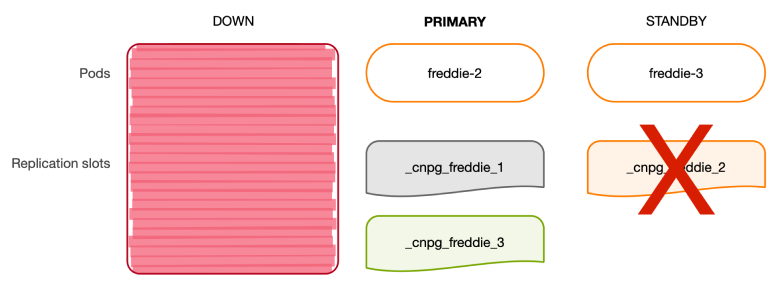
이후 freddie-1(이전 기본)이 다시 온라인 상태로 복귀하면, freddie-1의 로컬 인스턴스 관리자는 인스턴스가 대기(standby) 상태로 강등되었음을 감지합니다. 새 기본 인스턴스에 복제본으로 올바르게 연결되면, 인스턴스 관리자는 대기 HA 슬롯에 대한 업데이트를 수행하고 freddie-1에서 _cnpg_freddie_3 슬롯을 생성합니다. 동기화 과정에서는 또한 freddie-3에서 _cnpg_freddie_1 슬롯을 생성하여 최적의 상태로 클러스터를 복원합니다.
아래 다이어그램은 이러한 과정을 시각적으로 보여줍니다.
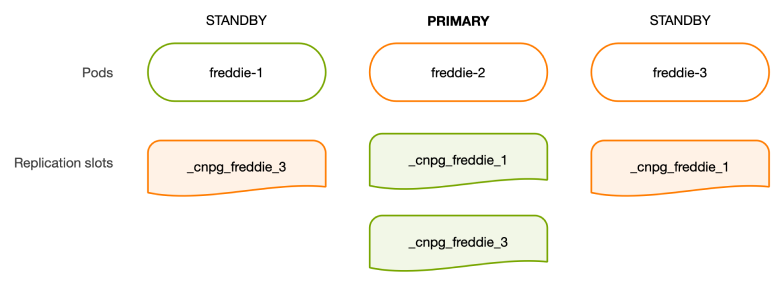
전환(Switchover)도 다뤄집니다. 장애 조치(Failover)와의 주요 차이점은 전환이 계획된 작업이라는 점입니다. 따라서 리더(primary)를 변경하기 전에 기존 기본(primary) 서버를 적절히 종료할 수 있습니다. 또한, 스케일업(Scale-up) 및 스케일다운(Scale-down) 작업도 각각 기본(primary) 및 대기(standby) HA 슬롯을 추가하거나 제거하여 지원됩니다.
결론: CloudNativePG 복제 슬롯의 효과와 운영 시 유의점
물리적 장애 조치 슬롯은 PostgreSQL의 클러스터 전반적인 한계를 극복하기 위해, Kubernetes 운영자가 자동으로 처리할 수 있는 2일차 작업의 대표적인 사례입니다. 이는 스크립트를 사용한 플레이북 또는 인간 DBA의 작업을 효과적으로 시뮬레이션합니다.
현재 CloudNativePG의 장애 조치 슬롯 구현은 고가용성을 위해 클러스터에서 관리되는 복제 슬롯만 동기화합니다. 다만, 지정된 제외 기준과 일치하지 않는 기본(primary)의 모든 복제 슬롯까지 동기화 범위를 확장하는 추가 사용자 제어 슬롯은 아직 포함되어 있지 않습니다. 이는 미해결 문제 “추가 물리적 복제 슬롯의 장애 조치 관리 #2385”에서 다뤄지고 있습니다.
CloudNativePG의 장애 조치 슬롯 구현: 복제본의 자가 복구 기능을 강화하여 수동 개입을 제한하는 두 가지 경우
- 기본(primary) 볼륨의 WAL 저장소가 부족한 경우
- 복제 슬롯 지연이
max_slot_wal_keep_size옵션을 초과해 복제본이 동기화되지 않는 경우
첫 번째 경우는 복제본이 쓰기 워크로드를 따라잡지 못하고 복제 슬롯을 지나치게 오래 유지할 때 발생합니다. 이 상황에서는 Postgres 기본 서버가 강제로 종료되며, 운영자가 장애 조치를 트리거해야 해 쓰기 애플리케이션에 다운타임이 생깁니다.
두 번째 경우는 max_slot_wal_keep_size 옵션을 설정함으로써 예방할 수 있습니다. 이 옵션은 지연이 지정된 크기(바이트)를 초과하는 복제 슬롯을 비활성화합니다. 비활성화된 슬롯은 기본 복제본의 디스크 공간을 확보하지만, 복제본의 동기화가 끊어져 수동 개입이 필요합니다. 이는 드물게 발생하며, 잘 관리된 환경에서는 적절한 대응 방안으로 간주됩니다.
수동 개입의 위험을 완화할 수 있는 대응 방안
- WAL 볼륨 크기를 충분히 확보하기
- 클러스터 모니터링 강화하기
CloudNativePG가 제공하고 있는 것들
- 클러스터 리소스 상태와 복제 슬롯 정보를 최신 상태로 유지하는 것
pg_replication_slots메트릭을 Prometheus 익스포터를 통해 노출해, 각 슬롯의 이름, 유형, 데이터베이스(논리적 슬롯인 경우), 활성 상태, 지연 정보를 보고하는 것
데이터 캡처 변경(CDC) 사용 사례와 논리적 복제 슬롯의 장애 조치에 관심이 있는 경우, 이 구현은 물리적 복제 슬롯에만 적용된다는 점을 유의해야 합니다. 논리적 복제 슬롯의 장애 조치 지원은 Patroni와 유사한 방식도 고려했으나, EDB가 pg_failover_slots 확장을 오픈소스화함에 따라 이를 채택했습니다. 이 확장은 EDB가 pglogical에서 개발했던 기술을 기반으로, 논리적 복제 슬롯의 고가용성을 효율적으로 관리하도록 설계되었습니다.
마지막으로, 프로덕션 환경에서는 항상 이 기능을 활성화하고, PostgreSQL 13 이상을 사용하는 경우 max_slot_wal_keep_size 옵션을 적절히 설정할 것을 권장합니다.
여러분의 피드백을 기다립니다. 장애 조치 슬롯을 사용해 보신 후, CloudNativePG 채팅에 참여하여 의견을 공유해 주시면, 이 기능과 운영자 개선에 큰 도움이 될 것입니다. 또한, Kubernetes에서 Postgres를 운영하면서 전문적인 지원이 필요하다면, 언제든지 EDB가 기꺼이 도와드리겠습니다.
본문: How CloudNativePG Manages Replication Slots
이메일: salesinquiry@enterprisedb.com

