
버그의 여정: 고객 문제 제기에서 PostgreSQL 커밋까지
딜립 쿠마르 작성 2024년 5월 9일
소프트웨어 개발의 복잡한 세계에서 버그는 애플리케이션과 시스템의 원활한 작동을 방해하는 은밀한 존재입니다. 때로는 이러한 버그와의 여정이 고객 문제 제기로 시작되어 조사, 해결, 그리고 궁극적으로는 더욱 견고한 소프트웨어 생태계를 구축하는 일련의 과정으로 이어집니다. 이번 글에서는 하나의 버그가 고객 문제 제기에서 패치 릴리스, 나아가 PostgreSQL의 중요한 서브시스템 재설계로 이어지는 과정을 살펴보겠습니다.
1. 시작: 고객 문제 제기
버그의 여정은 은행 서비스의 데이터베이스 서버에 과도한 부하로 인해 안정성이 위협받는 중요한 문제가 제기된 지원 티켓에서 시작되었습니다.
지원팀과 함께 고객과의 통화에서 서버가 과부하로 인해 새로운 연결을 수락할 수 없다는 사실이 드러났습니다.
2. 발견 및 보고
PostgreSQL 개발자로서 첫 번째 단계는 시스템이 대부분의 시간을 소비하는 대기 이벤트를 식별하는 것이었습니다.
다음 쿼리를 실행하여 대기 이벤트를 집계한 결과, 대부분의 시간이 SubtransSLRU와 SubtransBuffer 대기 이벤트에서 소비되고 있음을 발견했습니다.
\t
SELECT wait_event_type, wait_event
FROM pg_stat_activity
WHERE pid != pg_backend_pid()
\watch 0.5
집계된 결과는 아래와 같습니다:
| Count | Wait Event Type | Wait Event |
|---|---|---|
| 86595 | LWLock | SubtransSLRU |
| 14619 | LWLock | SubtransBuffer |
| 2574 | Client | ClientRead |
| 1876 | Activity | WalWriterMain |
| 823 | ||
| 404 | IO | SLRURead |
빈 wait_event는 대기 없이 CPU에서 실제 작업이 수행되고 있음을 의미합니다. 여기서 시스템이 SubtransSLRU 및 SubtransBuffer 대기 이벤트에서 100배 더 많은 시간을 소비하고 있음을 관찰할 수 있습니다.
3. 조사 및 분석
PostgreSQL에서 SubtransSLRU와 SubtransBuffer 대기 이벤트는 보통 pg_subtrans SLRU 서브시스템에 과중한 부하가 걸린 경우 발생합니다. SLRU (Simple Least Recently Used) 캐시는 PostgreSQL의 운영에 중요한 다양한 트랜잭션 관련 정보를 저장하는 디스크 페이지로 지원되는 메커니즘입니다.
이 문제를 깊이 이해하려면 PostgreSQL에서의 가시성 개념과 그것이 어떻게 이러한 대기 이벤트와 관련되는지를 이해하는 것이 중요합니다. 튜플(또는 행 버전)의 가시성은 xmin과 xmax 시스템 열에 의해 결정되며, 이는 각각 생성 및 삭제 트랜잭션의 트랜잭션 ID를 저장합니다. 쿼리가 시작되면 PostgreSQL은 해당 쿼리 실행 중 가시성 규칙을 정하는 스냅샷을 생성합니다. 이 스냅샷은 동시 트랜잭션과 서브트랜잭션의 배열을 포함합니다.
초기에는 PostgreSQL이 공유 데이터 구조를 검사하고 각 세션의 트랜잭션 ID를 읽어 준비합니다. 그러나 하나의 트랜잭션 아래 여러 개의 서브트랜잭션이 존재할 수 있기 때문에 PostgreSQL은 각 최상위 트랜잭션당 64개의 서브트랜잭션으로 캐시를 제한합니다. 트랜잭션이 이 한도를 초과하여 64개 이상의 서브트랜잭션을 생성하면 캐시가 오버플로우를 일으킵니다. 그 결과, 동시 스냅샷은 완전한 정보를 가지지 못하고 오버플로우로 표시됩니다.
행에서 트랜잭션의 가시성을 확인할 때, PostgreSQL은 먼저 최상위 트랜잭션 ID를 검색하며, 이는 SLRU 캐시에 접근하는 것을 필요로 합니다. SLRU 캐시는 디스크 저장소로 지원되는 간단한 LRU 캐시입니다. 오버플로우된 스냅샷의 수가 증가함에 따라 동시 백엔드들이 SLRU 캐시 접근을 두고 경쟁하게 되어, SubtransSLRU 잠금과 관련된 대기 이벤트가 발생합니다.
또한, 장기 실행 트랜잭션이 있는 경우 PostgreSQL은 최신 서브트랜잭션과 함께 이전 서브트랜잭션에 대한 부모 정보를 가져와야 합니다. 이로 인해 xid 조회 범위가 확장되며, 이는 SLRU 캐시의 추가적인 부담을 주어 SubtransBuffer 대기 이벤트로 나타나는 잦은 디스크 페이지 로드와 디스크 I/O 작업을 초래합니다.
고객 환경에서 서브트랜잭션 오버플로우의 존재는 분명했지만, 문제를 일으키는 애플리케이션의 특정 부분을 정확히 찾는 것은 불확실했습니다. 이 모호성은 서브트랜잭션 오버플로우의 성능 영향이 오버플로우를 발생시킨 백엔드에만 국한되지 않고 모든 백엔드에서 관찰될 수 있기 때문입니다. 따라서 대기 이벤트와 프로세스 ID만으로는 오버플로우를 일으킨 백엔드를 식별할 수 없었습니다. 그 이유는 그 대기 이벤트가 오버플로우를 발생시킨 하나의 백엔드로부터 영향을 받는 모든 백엔드에서 관찰될 수 있기 때문입니다.
4. 분류 및 우선순위 지정
서브트랜잭션 오버플로우를 생성하는 쿼리를 식별하기 위해, 우리는 고객에게 각 백엔드별로 서브트랜잭션 수와 서브트랜잭션 오버플로우 상태를 정기적으로 모니터링할 수 있는 커스텀 확장을 제공했습니다. 이후, 우리는 이 작업을 PostgreSQL 오픈 소스 코드에 커밋하여, 서브트랜잭션 오버플로우와 수를 모니터링할 수 있는 새로운 뷰인 pg_stat_get_backend_subxact()를 제공했습니다.
커스텀 확장의 도움으로 사용자들은 서브트랜잭션 오버플로우를 일으키는 문제의 애플리케이션 로직을 찾을 수 있었습니다. 애플리케이션 설계를 기반으로 서브트랜잭션 수를 줄이려고 했지만, 이를 통해 애플리케이션의 기본적인 비즈니스 로직을 유지할 방법은 없었습니다.
5. 임시 해결책 제공
이 문제의 기업 전체에 미치는 광범위한 영향을 고려할 때, 원활한 운영을 보장하기 위해 임시 해결책을 구현하는 것이 중요했습니다. 서브트랜잭션 캐시 오버플로우 문제를 해결하기 위해, 우리는 세션당 서브트랜잭션 캐시 한도를 64에서 256으로 높이는 핫픽스 패치를 배포했습니다. 이 숫자는 애플리케이션에서 서브트랜잭션을 최대한 사용한 경우를 기반으로 선택되었습니다.
이 조정은 각 스냅샷의 메모리 사용량을 증가시켰고, 일부 성능 저하를 초래할 수 있었지만, 서브트랜잭션 캐시 오버플로우로 인해 애플리케이션이 차단되지 않도록 하는 임시 조치로 작용했습니다. 이 핫픽스는 최종 해결책으로 간주되지 않고, 비즈니스 연속성을 유지하기 위한 실용적인 단계였습니다.
이렇게 하면 고객은 다음 Postgres 릴리스까지 기다리지 않고도 버그가 수정될 수 있었습니다. 또한, 이 수정 사항을 고객 전용 릴리스에서 유지했기 때문에 다른 고객들은 이 상수 변경이 애플리케이션에 미칠 부정적인 영향에 대해 걱정할 필요가 없었습니다.
6. 근본적인 문제 해결
고객의 문제를 해결한 후, 우리는 Postgres SLRU에서 오랫동안 해결되지 않았던 성능 문제를 해결하기 위한 여정을 시작했습니다. 이 문제는 수년 동안 문제가 되어왔으며 여러 블로그에서 논의되었습니다[4]. 이 문제를 해결하려는 시도가 여러 번 있었지만 지금까지 누구도 성공하지 못했습니다.
저는 pgbench 워크로드를 사용하여 이 문제를 로컬에서 재현하며 문제를 더 자세히 분석하기 시작했습니다. 또한 여러 회의에서 이 문제에 대해 논의했습니다[2].
그곳에서 우리는 문제 해결을 위한 솔루션을 설계하기 시작했습니다. 우리는 과거의 해결책들을 분석하고 그들의 장점과 한계를 제시했습니다. 기존 아이디어 중 일부를 바탕으로 새로운 아이디어를 추가하여 문제를 완전히 해결할 수 있는 방법을 만들었습니다. 이 솔루션은 제가 한 회의에서 발표한 바 있습니다[3].
이 작업을 진행하는 동안 PostgreSQL 커미터인 Robert Haas와 Alvaro Herrera로부터 지속적인 지원을 받았습니다.
해결책 게시 및 커밋 과정
마침내 해결책을 구현하고 고객 환경에서 많은 성능 테스트와 검증을 거친 후, 이 솔루션을 PostgreSQL 오픈 소스 커뮤니티에 게시했습니다 [5].
그곳에서 이 해결책은 많은 설계 및 코드 변경을 거쳤고, 결국 Alvaro Herrera가 이 솔루션을 PostgreSQL 오픈 소스에 커밋했습니다. 이 문제와 우리가 구현한 해결책에 대해 자세히 설명하는 블로그도 작성되었습니다. 이 해결책이 Postgres 17에 포함될 예정임을 공유하게 되어 기쁩니다 [6].
수정 후 성능 분석
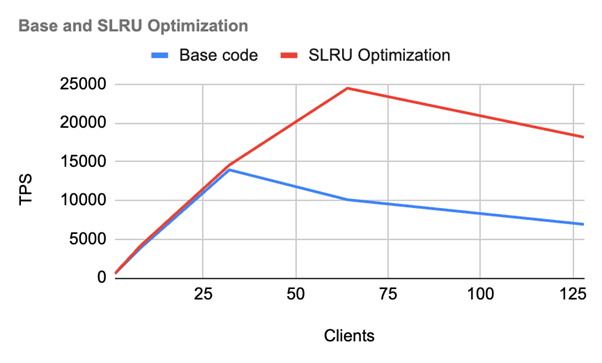
우리는 수정되지 않은 버전과 수정된 버전 간의 성능 지표를 비교했습니다. 높은 클라이언트 수에서 기본 코드로는 성능이 현저히 떨어지는 반면, 패치된 버전은 훨씬 더 나은 성능을 보였습니다. 수정된 버전은 수정되지 않은 버전보다 약 2.5-3.0배 빠르게 실행됩니다.
테스트 머신
- Intel 128 코어 머신, 512 GB RAM, 8 CPU
테스트
- 다양한 클라이언트 수(1-128)로 pgbench 테스트 실행
- 서브트랜잭션 캐시 오버플로우를 병렬로 생성
- 트랜잭션 내에서 70개의 세이브포인트 생성
- 1초 대기 후 커밋
- 이 과정을 테스트 실행 중 반복
- 또한, 장기 실행 트랜잭션 실행
- 트랜잭션 ID만 부여
- 10초 대기 후 커밋
- 이 과정을 테스트 실행 중 반복
결과
30명의 클라이언트에서 성능 저하가 두드러졌으나, 해결책을 구현한 후에는 성능이 70명의 클라이언트까지 선형적으로 확장되었습니다.
결론: 버그의 영향을 수용하며
버그는 혼란을 야기하지만, 개선과 혁신, 고객 만족을 이끄는 촉매제 역할을 합니다. 투명성, 협업, 문제 해결 문화를 통해 더욱 견고하고 신뢰할 수 있는 소프트웨어 솔루션으로 이어집니다.
이 문제는 오픈 소스 소프트웨어에서 오랫동안 미뤄진 문제였지만, 고객에게 영향을 미쳤을 때 우리는 이 문제를 분석하고 다양한 포럼에서 문제를 제기하여 더 많은 관심을 끌고, 마침내 커뮤니티와 함께 해결했습니다. 이 여정을 통해 PostgreSQL 커뮤니티와 함께 문제를 해결할 수 있어 보람을 느낍니다.
Reference
[1] https://www.postgresql.org/message-id/E1p7MF8-004RLt-5L%40gemulon.postgresql.org
[2] https://www.youtube.com/watch?v=RUtVaIjrxOg&t=1384s
[3] https://www.youtube.com/watch?v=9ya08Q278pg
[4] https://postgres.ai/blog/20210831-postgresql-subtransactions-considered-harmful
[5] https://www.postgresql.org/message-id/CAFiTN-vzDvNz%3DExGXz6gdyjtzGixKSqs0mKHMmaQ8sOSEFZ33A%40mail.gmail.com
[6] https://pganalyze.com/blog/5mins-postgres-17-configurable-slru-cache
본문: The Life of a Bug: From Customer Escalation to PostgreSQL commit
EDB 영업 기술 문의: 02-501-5113
이메일: salesinquiry@enterprisedb.com

