
고성능(몬스터) 하드웨어에서의 PostgreSQL 성능 최적화 가이드
Lætitia Avrot
2025년 2월 17일
최신 세대의 CPU 출시 소식을 접하셨나요? AMD의 최신 Genoa CPU(AMD EPYC™ 9965)는 무려 768개의 스레드를 실행할 수 있습니다. 소켓당 192개의 코어, 코어당 2개의 스레드를 지원하는데, 이를 2개의 소켓에서 활용할 수 있습니다. 여기에 10TB의 RAM까지 추가하면 어떤 모습일지 상상이 가시나요?
대부분의 사람들은 이런 고성능 하드웨어가 가상화 환경에서 얼마나 유용할지 먼저 떠올릴 것입니다. 하지만 데이터베이스 전문가인 저는 Postgres가 이렇게 강력한 리소스를 어떻게 활용할 수 있을지 고민하게 됩니다.
저는 단순한 아키텍처를 선호하지만, 고객을 만나다 보면 어마어마한 리소스를 필요로 하는 경우를 자주 접합니다. 현재의 일반적인 서버 환경에서는 이런 요구를 충족하기 위해 MPP(Massively Parallel Processing, 대규모 병렬 처리)를 사용하는 것이 최선일 때도 있습니다.
그렇다면, 이렇게 고성능 하드웨어를 활용하면 더 이상 수평 확장이 필요하지 않을까요? PostgreSQL이 이러한 환경에서 어떤 영향을 받는지 이해하려면 몇 가지 기술적 한계를 살펴봐야 합니다.
먼저 NUMA(Non-Uniform Memory Access) 아키텍처의 영향을 분석하고, 다음으로 I/O 대역폭의 한계를 살펴보겠습니다. 아무리 CPU와 메모리가 강력하더라도 I/O 성능이 병목이 될 수 있기 때문입니다.
또한, PostgreSQL의 다중 연결 처리 방식도 중요한 요소입니다. 이 부분은 역사적으로 여러 제약이 있어 흥미로운 질문들을 던지게 합니다. 마지막으로, 병렬 쿼리 성능을 테스트하여 다수의 CPU 스레드가 있는 시스템에서 병렬 처리가 얼마나 효과적으로 확장되는지 분석해 보겠습니다.
NUMA(비균일 메모리 접근): 잘 알려진 골칫거리
NUMA란 무엇인가?
컴퓨터 초창기에는 소켓당 하나의 CPU만 존재했고, 대부분의 시스템은 단일 소켓 구조였습니다. 따라서 모든 CPU가 동일한 방식으로 메모리에 접근할 수 있었고, 충돌이 발생할 일이 없었죠. 하지만 누군가 “소켓을 두 개로 늘리면 컴퓨터 성능이 두 배로 증가하지 않을까?” 라는 아이디어를 떠올렸습니다.
CPU가 늘어나면 처리 성능도 증가하지만, 문제는 모든 CPU가 동일한 메모리를 공유해야 한다는 점 이었습니다. 당시에는 각 CPU 코어(당시에는 단일 코어 CPU만 존재)가 하나의 메모리 풀을 사용하며, 차례대로 메모리에 접근하는 방식이었습니다. 모든 코어가 메모리의 어느 부분이든 동일한 속도로 접근할 수 있었기 때문에, 이를 UMA(Uniform Memory Access, 균일 메모리 접근) 라고 불렀습니다.
그러나 이후 CPU 하나에 더 많은 코어가 추가되고, 소켓 수도 늘어나면서 문제가 발생했습니다. 각 코어가 메모리에 접근하기 위해 “버스(bus)” 라는 통로를 거쳐야 하는데, CPU가 많아질수록 이 버스가 병목 현상을 일으켜 성능 저하를 유발한 것이죠.
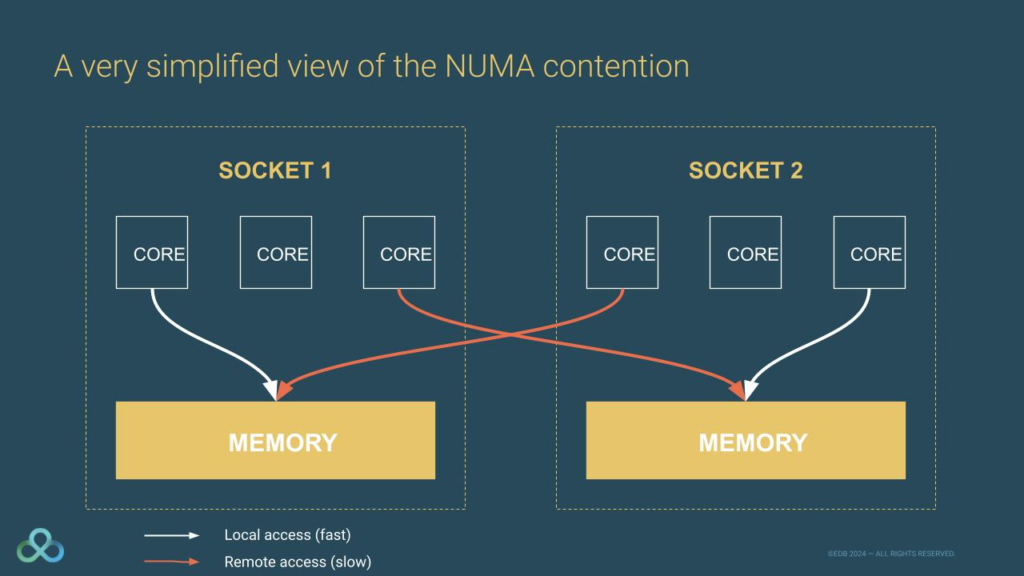
이를 해결하기 위해 등장한 개념이 NUMA(Non-Uniform Memory Access, 비균일 메모리 접근) 입니다. NUMA에서는 시스템의 메모리를 NUMA 노드 라는 영역으로 나누고, 각 CPU 코어가 물리적으로 가까운 로컬 NUMA 노드 를 우선적으로 사용하도록 설계되었습니다.
만약 더 많은 메모리가 필요하면, 다른 리모트 NUMA 노드 에도 접근할 수 있습니다. 하지만 로컬 NUMA 노드에 접근하는 것은 빠르고 효율적인 반면, 리모트 NUMA 노드에 접근하는 것은 더 복잡하고 느리다는 단점이 있습니다.
NUMA를 쉽게 이해하는 방법: 4살짜리 아이들과 장난감 상자
NUMA 개념을 더 쉽게 이해하려면 4살짜리 아이들을 예로 들어보겠습니다.
만약 당신이 4살짜리 아이들을 돌보고 있다고 가정해 보세요. 아이들이 장난감을 갖고 놀 수 있도록, “한 명씩 차례로 장난감 상자에 접근하도록 하자” 라는 규칙을 만든다면, 두 명 정도는 별문제가 없을 겁니다.
하지만 만약 아이들이 20명이라면? 이 방식은 금방 한계에 부딪히겠죠. 기다리는 시간이 너무 길어지고, 아이들은 점점 참을성이 없어질 것입니다. 4살짜리 아이들이 얼마나 빨리 짜증을 내는지 아는 사람이라면 공감할 수 있을 겁니다!
이때, 유치원 교사라면 가장 간단한 해결책을 제시할 겁니다. “각 아이에게 자기만의 장난감 상자를 주자!” 아이들은 자신의 장난감 상자를 우선적으로 사용하면서도, 필요하면 다른 아이의 장난감 상자도 (허락을 받는다면) 사용할 수 있습니다.
이것이 바로 NUMA가 동작하는 방식과 같습니다.
CPU 코어는 먼저 자신과 가까운 로컬 메모리(NUMA 노드) 를 사용하지만, 필요할 경우 멀리 있는 리모트 메모리(NUMA 노드) 도 사용할 수 있습니다. 하지만 리모트 메모리는 로컬 메모리보다 느리므로, 최대한 로컬 메모리를 활용하는 것이 성능을 유지하는 핵심입니다.
PostgreSQL이 받는 영향
PostgreSQL이 처음 개발될 당시에는 NUMA(비균일 메모리 접근) 라는 개념이 존재하지 않았습니다. 특히 PostgreSQL은 공유 버퍼(shared buffers)를 많이 사용하는데, 이 공유 버퍼는 모든 PostgreSQL 프로세스가 함께 사용하는 핵심적인 메모리 공간입니다.
하지만 공유 버퍼는 PostgreSQL이 시작될 때 한 번에 할당되며, 이때 실행되는 postmaster 프로세스가 속한 NUMA 노드에서 할당됩니다. 특히 pg_prewarm 확장 기능을 사용하는 경우 이 현상이 더욱 두드러집니다. pg_prewarm은 PostgreSQL의 공유 버퍼 캐시에 테이블이나 인덱스를 미리 로드하여 성능을 향상시키는 기능을 하는데, 이 과정에서 특정 NUMA 노드에 데이터가 집중될 수 있습니다.
Postmaster 프로세스가 새로운 연결을 생성할 때, 해당 프로세스는 공유 버퍼에 접근할 수 있습니다. 하지만 공유 버퍼가 해당 프로세스와 가까운 NUMA 노드에 위치하지 않는다면, 메모리 접근 속도가 느려질 수밖에 없습니다.
얼마나 느려질까요?
이를 이해하려면 두 가지 측면에서 살펴봐야 합니다.
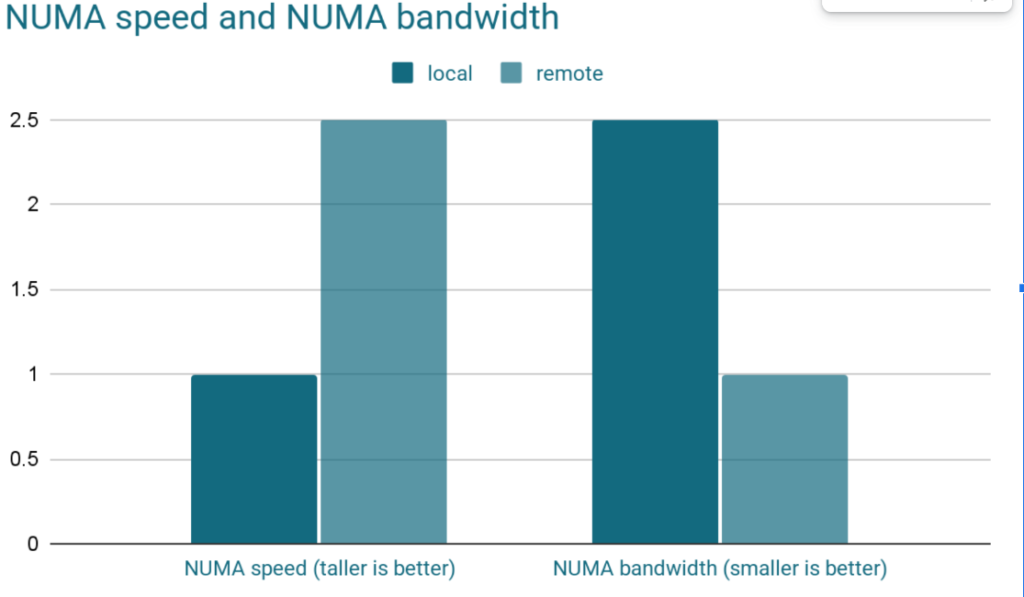
첫 번째는 접근 속도입니다. 로컬 NUMA 노드에 접근하는 것이 리모트 NUMA 노드에 접근하는 것보다 훨씬 빠릅니다. 제조사 사양에 따르면, 자신의 NUMA 노드에 접근하는 데 걸리는 시간은 50~100ns인데, 리모트 NUMA 노드에 접근하면 이 속도가 2~3배 느려집니다. 또한, 리모트 NUMA 노드를 사용할 때는 메모리 대역폭도 감소합니다.
예를 들어, 리모트 NUMA 노드에 접근하는 데 걸리는 시간이 200ns라고 가정해 보겠습니다. 이 정도 차이는 단순히 보면 크게 체감되지 않을 수도 있습니다. 하지만 PostgreSQL은 하나의 쿼리에서 이 작업을 수십억 번 수행할 가능성이 큽니다. 만약 10억 번(1 billion) 의 리모트 NUMA 노드 접근이 발생한다고 하면, 200ns × 10억 = 200ms의 지연이 발생할 수 있습니다.
두 번째는 메모리 대역폭입니다. 제조사 사양에 따르면, 로컬 NUMA 노드의 메모리 대역폭은 50GB/s지만, 리모트 NUMA 노드에 접근하면 20GB/s로 급격히 감소합니다. 즉, 단순한 접근 속도 차이뿐만 아니라, 데이터를 읽고 쓰는 속도 자체에도 큰 영향을 미친다는 점이 문제입니다.
그다음으로 고려해야 할 것이 잠금(Lock) 문제입니다. 메모리 손상을 방지하기 위해 메모리를 할당할 때는 반드시 잠금이 필요합니다. CPU가 잠금을 기다리는 동안 다른 작업을 수행할 수 있다면 큰 문제가 되지 않지만, 항상 그렇게 동작하는 것은 아닙니다.
특히 해시 테이블(Hash Table) 처리는 많은 메모리를 사용하며, 잠금을 획득하지 않으면 연산을 계속할 수 없습니다. 해시 테이블은 메모리에서 많은 데이터를 변경해야 하기 때문에 데이터를 수정할 때마다 잠금이 필요합니다.
즉, NUMA 환경에서 메모리 접근 속도가 느려질수록 잠금 획득에 걸리는 시간도 길어지고, 결국 전체적인 성능 저하로 이어질 수 있습니다.
기존 하드웨어의 한계: I/O 대역폭
DBA, 데이터베이스 컨설턴트, 그리고 PostgreSQL 문제 해결사로서의 경험을 돌아보면, 대부분의 성능 병목은 I/O에서 발생합니다. 아무리 빠른 SSD라도 RAM보다 속도가 느릴 수밖에 없기 때문에, I/O 경합(I/O Contention)이 생기는 것이죠.
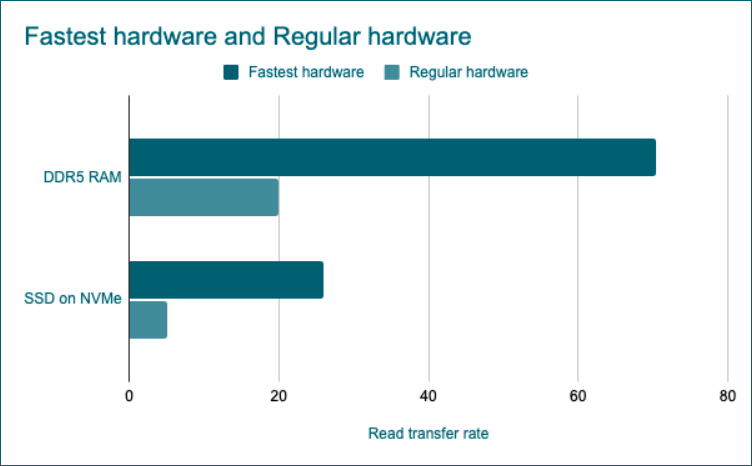
예를 들어, 최신 DDR5 RAM의 연속 읽기(Sequential Read) 속도는 최대 70.4GB/s(제조사 기준)입니다. 반면, 가장 빠른 PCIe 6세대 NVMe SSD도 최대 26GB/s 수준에 불과합니다. 즉, SSD는 RAM보다 거의 3배 느립니다.
하지만 이 수치는 고성능 하드웨어를 사용할 때의 이야기일 뿐, 실제 시스템에서는 더욱 큰 차이가 발생합니다. 일반적으로 RAM의 전송 속도는 10~30GB/s 수준이며, NVMe SSD는 2~5GB/s 정도입니다.
결국 PostgreSQL이 데이터를 디스크에서 읽거나 저장할 때 RAM을 사용할 때보다 훨씬 더 느려질 가능성이 큽니다.
디스크 신뢰성 문제
또 다른 문제는 디스크의 내구성 입니다. SSD는 일정 횟수 이상의 쓰기 작업이 이루어지면 수명이 다하고 결국 고장납니다. 만약 디스크가 갑자기 손상된다면? 데이터를 잃을 위험이 커질 수밖에 없습니다. 이러한 문제를 방지하기 위해 RAID(Redundant Array of Independent Disks, 독립 디스크의 중복 배열)가 사용됩니다.
RAID에는 여러 방식이 있지만, 데이터베이스 운영에는 RAID10이 가장 적합합니다. RAID10은 스트라이핑(Striping)과 미러링(Mirroring)을 결합하여 속도와 안정성을 모두 보장합니다. 즉, 각 데이터 블록을 두 번 기록하며, 서로 다른 디스크에 저장하는 방식입니다. 물론, 같은 데이터를 두 번 기록해야 하기 때문에 디스크 쓰기 속도는 메모리보다 훨씬 느려질 수밖에 없습니다.
PostgreSQL이 활용할 수 있는 리소스의 한계
이러한 문제를 고려하면, 성능을 위해 RAID10을 사용하지 않거나 fsync(파일 동기화)를 비활성화하는 것은 추천하지 않습니다. 만약 서버가 충돌하거나 디스크를 잃게 되면, 데이터를 복구할 방법이 없을 수도 있기 때문입니다.
결국, 스토리지 기술이 획기적으로 발전하지 않는 한, 이러한 I/O 한계는 계속 PostgreSQL의 성능을 제한하는 요소로 작용할 것입니다. 아무리 강력한 하드웨어를 제공하더라도, PostgreSQL이 이를 100% 활용하기 어려운 이유 중 하나가 될 것입니다.
예측하기 어려운 변수: 연결 수(Connection Count)
PostgreSQL은 많은 수의 연결을 처리하는 데 최적화되지 않은 것으로 잘 알려져 있습니다. 그렇다고 PostgreSQL이 성능을 제대로 발휘하지 못하는 것은 아닙니다.
다만, 트랜잭션 워크로드를 운영할 때는 반드시 연결 풀러(Connection Pooler)를 사용하는 것이 좋습니다.
만약 하나를 선택해야 한다면 pgBouncer가 좋은 선택이 될 수 있고, Java를 사용한다면 JDBC 드라이버에 내장된 풀러를 활용하는 것도 방법입니다.
과거 한 고객으로부터 긴급 지원 요청을 받은 적이 있습니다. PostgreSQL이 실행되는 리눅스 서버의 리소스가 한계에 도달하면서 전체적인 성능이 심각하게 저하된 상황이었습니다.
서버 자체의 성능이 기대했던 만큼 높지 않았던 것도 문제였지만, 원인은 따로 있었습니다.
조사를 진행해 보니, 잘못된 연결 풀러 설정이 문제였습니다. 초당 수만 개의 연결을 끊었다가 다시 생성하는 작업을 반복하고 있었고, 사실상 이 작업을 계속 시도하고 있었습니다.
문제의 원인은 PostgreSQL이 아니라 리눅스 자체의 한계였습니다. 리눅스는 그렇게 짧은 시간 안에 그렇게 많은 프로세스를 포크(fork)할 수 없었기 때문이었습니다.
해결 방법은 의외로 간단했습니다. JDBC 연결 풀러를 올바르게 설정하는 것이었습니다.
고성능 하드웨어에서는 어떻게 될까?
만약 768개의 스레드와 10TB의 RAM을 갖춘 강력한 서버를 사용했다면, PostgreSQL과 리눅스가 이러한 자원을 제대로 활용할 수 있었을까요? 솔직히 말해, 확신할 수 없습니다.
이론적으로 보면, 더 많은 autovacuum 워커를 추가할 수 있다면, 대량의 테이블을 관리하는 데 유리할 것입니다. 또한, 각 연결이 새로운 프로세스를 생성하기 때문에, 더 많은 CPU 스레드를 활용하면 동시에 더 많은 프로세스를 실행할 수 있습니다.
하지만, 이렇게 이전에는 경험하지 못한 새로운 환경에 진입하게 되면, 예상치 못한 버그나 비효율적인 동작이 발생할 가능성도 커집니다.
이는 PostgreSQL뿐만 아니라, PostgreSQL이 강하게 의존하는 리눅스에서도 마찬가지입니다.
만약 이러한 낮은 수준의 성능 최적화 문제를 탐색하고 싶다면, “An analysis of Linux Scalability to Many Cores”라는 학술 논문과 해당 주제로 발표된 컨퍼런스 자료를 참고해 보시기 바랍니다.
물론, EDB는 이러한 문제를 해결하기 위해 함께할 준비가 되어 있습니다.
이러한 문제를 해결하는 과정에서 PostgreSQL 커뮤니티 전체에도 큰 도움이 될 것입니다.
또한, PostgreSQL에서 발생했던 성능 관련 버그를 해결한 사례도 공유되어 있으니, 관심이 있다면 확인해 보시길 추천합니다.
쿼리 병렬 처리: “상황에 따라 달라지는 요소”
쿼리를 병렬로 처리하려면 추가적인 리소스와 시간이 필요합니다.
이는 결과를 수집하고 여러 작업자(worker) 간 동기화를 맞추는 과정 때문입니다.
예를 들어, SELECT COUNT(*) FROM tableA 같은 간단한 쿼리가 동일한 데이터를 중복 계산하는 일이 발생하면 안 되겠죠. 이런 이유로 병렬 쿼리에는 항상 일정한 오버헤드(추가 비용)가 따릅니다. 이 오버헤드는 크지 않지만, 어떤 쿼리에서는 성능 저하로 이어질 수도 있고, 반대로 무시할 정도로 미미할 수도 있습니다.
PostgreSQL 옵티마이저의 한계
제 경험과 동료들의 의견을 종합해 보면, PostgreSQL 옵티마이저는 어떤 쿼리가 병렬 처리에 적합한지, 그리고 어떤 쿼리는 오히려 성능이 저하될지를 완벽하게 판단하지 못하는 경우가 많습니다.
물론, 옵티마이저를 조정하여 특정 워크로드에 최적화되도록 학습시키는 방법도 있지만, 이는 쉽지 않은 작업입니다.
병렬 처리의 이점을 얻을 수 있는 쿼리 유형
-
- 대형 테이블(또는 파티션된 테이블) 을 대상으로 하는 쿼리는 병렬 처리를 통해 성능 향상을 기대할 수 있습니다.
-
- 작은 테이블을 대상으로 한 쿼리는 병렬 처리의 효과가 크지 않을 가능성이 높습니다.
-
- 대량의 데이터를 집계(Aggregate)하는 분석 쿼리는 데이터의 특성에 따라 병렬 처리가 도움이 될 수도 있고, 오히려 성능 저하를 일으킬 수도 있습니다.
-
- 트랜잭션 워크로드는 일반적으로 작은 단위의 쿼리를 처리하기 때문에 병렬 처리의 이점을 보기 어렵지만, 일부 예외적인 경우에는 도움이 될 수 있습니다.
PostgreSQL 문서에서는 수천 개 이상의 파티션을 사용하지 말 것을 권장합니다.
또한, 네이티브 파티셔닝(Native Partitioning)에서는 하나의 테이블이 같은 쿼리 내에서 최대 64,000개의 파티션을 사용할 수 있는 비공식적인 제한이 있습니다.
관련 버그 리포트는 여기에서 확인할 수 있습니다.
결국, 가장 확실한 방법은 실제 워크로드를 기반으로 벤치마크를 수행하는 것 입니다.
또한, 시스템의 성능은 가장 느린 하드웨어가 결정한다는 점도 잊지 말아야 합니다.
아무리 CPU 성능이 뛰어나더라도 병목이 I/O라면, 추가적인 CPU 리소스가 큰 도움이 되지 않을 수도 있습니다.
마무리하며
오늘날 데이터베이스 업계는 MPP(Massively Parallel Processing, 대규모 병렬 처리) 솔루션 에 크게 의존하고 있으며, 이는 대규모 워크로드를 관리하는 데 필수적인 요소입니다. 하지만 768개의 스레드와 테라바이트급 RAM을 제공하는 AMD의 새로운 Genoa CPU 같은 강력한 하드웨어가 등장하면서, 데이터베이스 아키텍처에 대한 기존의 접근 방식이 바뀔 가능성이 커지고 있습니다.
지금은 MPP 없이 운영되는 환경을 상상하기 어렵지만, 향후 1~3년 내에 데이터베이스 아키텍처에 대한 우리의 시각이 크게 달라질 수도 있습니다. 이처럼 강력한 하드웨어를 활용하면 복잡한 분산 시스템을 관리하는 대신, 단일 PostgreSQL 인스턴스에서 대규모 워크로드를 처리할 가능성이 열릴지도 모릅니다.
이러한 변화는 운영을 단순화하고 유지보수를 쉽게 하며, 보다 예측 가능한 성능을 제공할 수 있다는 점에서 매우 기대되는 발전입니다.
하지만, 신중한 접근이 필요합니다.
기술이 발전한다고 해서 모든 환경에 무조건 적합한 것은 아닙니다. 각 워크로드는 고유한 특성을 가지고 있으며, 한 환경에서 뛰어난 성능을 보이는 솔루션이 다른 환경에서는 기대만큼 효과적이지 않을 수도 있습니다.
따라서 벤치마킹을 통해 단순히 현재 성능을 평가하는 것을 넘어, 새로운 하드웨어에서 성능이 어떻게 확장될지를 분석하는 과정이 필수적입니다.
좋은 소식은, 혼자 고민할 필요가 없다는 것입니다.
EDB는 이러한 새로운 기술 환경을 탐색하는 과정에서 여러분과 함께할 준비가 되어 있습니다.
성능 문제를 겪고 있거나, 벤치마킹이 필요하거나, 새로운 하드웨어 구성을 실험해 보고 싶다면,
EDB의 전문가들이 최적의 해결책을 찾을 수 있도록 도와드릴 것입니다.
우리는 오랫동안 PostgreSQL의 한계를 확장해온 경험이 있으며,
이번에 등장한 강력한 하드웨어가 PostgreSQL의 미래를 어떻게 바꿀 수 있을지 매우 기대하고 있습니다.
완벽한 솔루션이 단 하나만 존재하는 것은 아닙니다. 하지만 적절한 테스트, 전문가의 조언, 그리고 최적의 하드웨어-소프트웨어 조합을 갖춘다면, 지금까지 상상했던 것보다 더 단순하면서도 강력한 데이터베이스 아키텍처를 구축할 수 있을 것입니다.
핵심은 벤치마킹, 테스트, 그리고 검증입니다.
그리고 그 모든 과정에서 EDB가 함께할 것입니다.
본문: Postgres in the time of monster hardware
이메일: salesinquiry@enterprisedb.com

