
에이전트는 결국 데이터 문제입니다 — 그리고 EDB Postgres® AI가 그 답이 되었습니다
Dave Stone · 2026년 6월 23일
우리가 만나는 모든 기업은 같은 여정의 어딘가에 서 있습니다. AI 에이전트가 진짜라고 판단을 내렸고, 파일럿을 시작했고, 그러다 벽에 부딪힙니다. 그 벽은 좀처럼 모델 때문이 아닙니다. 대개는 그 아래 깔린 데이터 기반이 문제입니다. 고객들은 자기 데이터를 두고 똑같은 질문을 던집니다. 상호작용 전반에 걸쳐 맥락을 유지할 기억(memory)을 에이전트에게 어떻게 줄 것인가? 우리 고유 데이터를 근거로 추론할 지식은? 엔터프라이즈 규모에서 안정적으로 실행할 운영 기반은?
이건 전부 데이터베이스 문제입니다. 어떤 건 이미 잘 알려져 있고, 어떤 건 제대로 해내는 데 수년의 엔터프라이즈 경험이 필요합니다. 우리가 그동안 고객을 위해 묶어 온 것이 바로 이것입니다. 데이터 자산(data estate) 전반의 AI 워크로드에서 데이터 관리의 마찰을 걷어내는 일이죠.
이 글에서는 우리가 무엇을 만들었는지, 그것이 규제 산업에 왜 중요한지, 그리고 EDB Postgres® AI(EDB PG AI)를 Databricks, MongoDB, Snowflake, Amazon Aurora 등과 나란히 놓고 “AI 에이전트가 실제로 프로덕션에서 돌아갈 수 있는가”를 가르는 지표로 측정했을 때 독립 벤치마크가 무엇을 보여주는지 다룹니다.
우리 고객조차 놀랐습니다
EDB PG AI를 완전한 분석·AI 플랫폼으로 확장하기 시작했을 때, 고객들의 반응은 솔직했습니다. “그것 때문에 EDB를 찾은 건 아니었어요.” 한 고객은 이렇게 말했습니다. “우리는 EDB가 Oracle 마이그레이션을 다루는 트랜잭션 데이터베이스 회사라고만 생각했거든요.” 우리가 메우려고 나선 게 바로 그 인식의 간극입니다. 레이크하우스(Lakehouse)를 Postgres로 가져오고, LLM과 머신러닝 모델이 트랜잭션 데이터 바로 옆에서 돌아가게 만들어서요.
지난 1년 동안 우리가 만든 것은, 금융·헬스케어·통신·정부 분야 고객이 트랜잭션 워크로드, 분석 쿼리, 벡터 검색, 생성형 AI 추론을 단 하나의 거버넌스된 플랫폼에서 돌릴 수 있는 능력입니다. 핵심 가치는 운영의 단순함입니다. 더 적은 벤더, 더 적은 인수인계, 하나의 보안 경계, 그리고 이미 당신의 컴플라이언스 요건을 충족하는 단일 플랫폼이죠. 수십 년간 신뢰해 온 Postgres 기반 위에 세워졌기 때문입니다.
이 전환을 택한 고객들은 이렇게 말합니다. 비대해질 대로 비대해진 스택을 통합하는 데, 플랫폼 하나면 됐다는 걸 미처 몰랐다고요. 이제 그들은 기술 풋프린트를 줄이는 동시에 할 수 있는 일의 범위는 넓히고 있습니다.
Gartner®가 문제를 명명했고, 우리는 해법을 파고들었습니다
Gartner는 새로운 카테고리를 정의했습니다. 바로 에이전틱 데이터베이스(agentic database)입니다. AI 에이전트가 프로덕션으로 들어가 내부 팀과 고객을 상대로 일하게 되면서, 이 일을 위해 만들어진 데이터베이스와 그렇지 않은 데이터베이스 사이의 격차가 분명해졌습니다. 애널리스트들은 에이전트에게 세 가지 데이터 관리 역량이 필요하다고 권고합니다.
- 에이전트 기억(Agent memory) — 상호작용 전반의 맥락을 실시간으로, 높은 정확도로 저장하고 꺼내 와서, 에이전트가 답을 만들 때 늘 최신의 관련 정보를 갖추도록 합니다.
- 지식 소스(Knowledge source) — 고유 데이터, 트랜잭션, 문서로부터 대규모로 정확하게 검색해 옵니다. 엔터프라이즈 AI에 진짜 가치를 부여하는 그 데이터 말이죠.
- 도구 제공자(Tool provider) — 데이터 작업을 일관되게, 안전하게, 엔터프라이즈 SLA 수준으로 실행해, 에이전트가 데이터를 읽기만 하는 게 아니라 그 위에서 행동할 수 있게 합니다.
이 관점은 AI를 위한 데이터베이스를 평가하는 방식을 바꿔놓습니다. 질문은 “이 플랫폼이 벡터 검색을 돌릴 수 있는가”를 넘어, “세 가지를 동시에, 대규모로, 프로덕션에서 에이전트 성능을 떨어뜨리지 않으면서 해낼 수 있는가”로 옮겨갑니다.
에이전트를 위한 데이터베이스를 측정하기 위해, 우리는 독립 리서치 기관인 McKnight & Company에 의뢰했습니다. 이들의 벤치마크는 EDB PG AI가 위 세 요건에 직접 대응하는 지표에서 Databricks, MongoDB, Snowflake, AWS를 상대로 어떤 성능을 내는지 보여줍니다. 먼저 숫자가 말하게 한 다음, 그것이 실무에서 무엇을 뜻하는지 설명하겠습니다.
벤치마크: 프로덕션 규모에서 실제로 벌어지는 일
쿼리 지연 시간: 에이전트 기억은 여기서 시작된다
에이전트 기억의 가장 근본적인 요건은 속도입니다. 에이전트가 맥락을 유지하고 정확하게 응답하려면, 데이터베이스가 빠르게 답해야 합니다. 평균적으로만이 아니라 매번 말이죠.
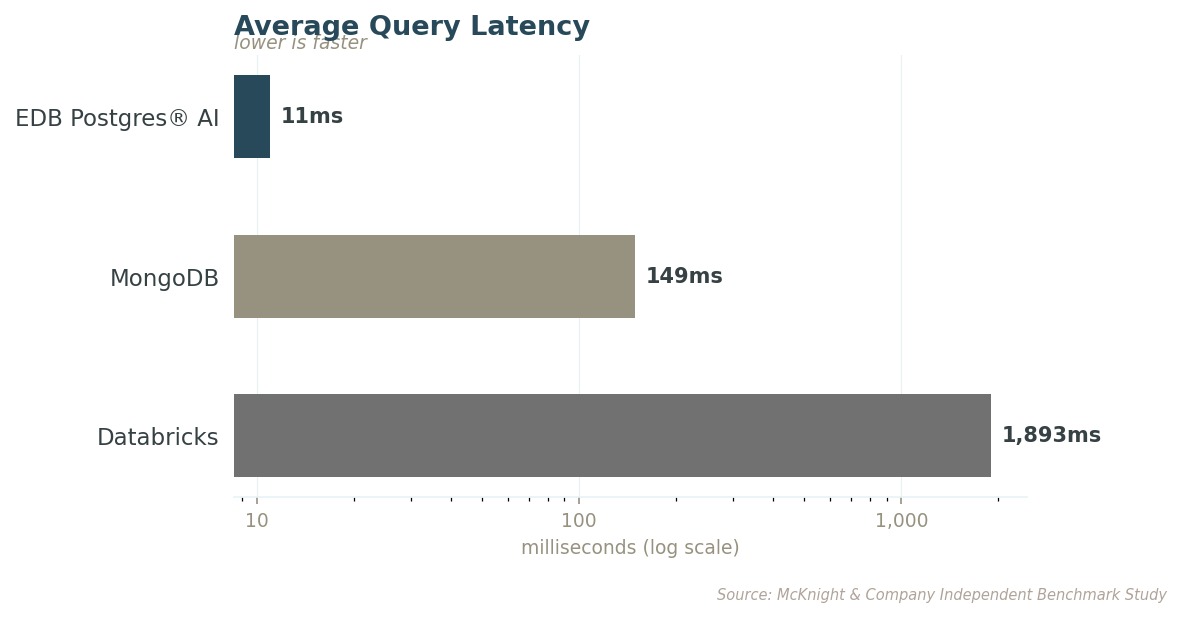
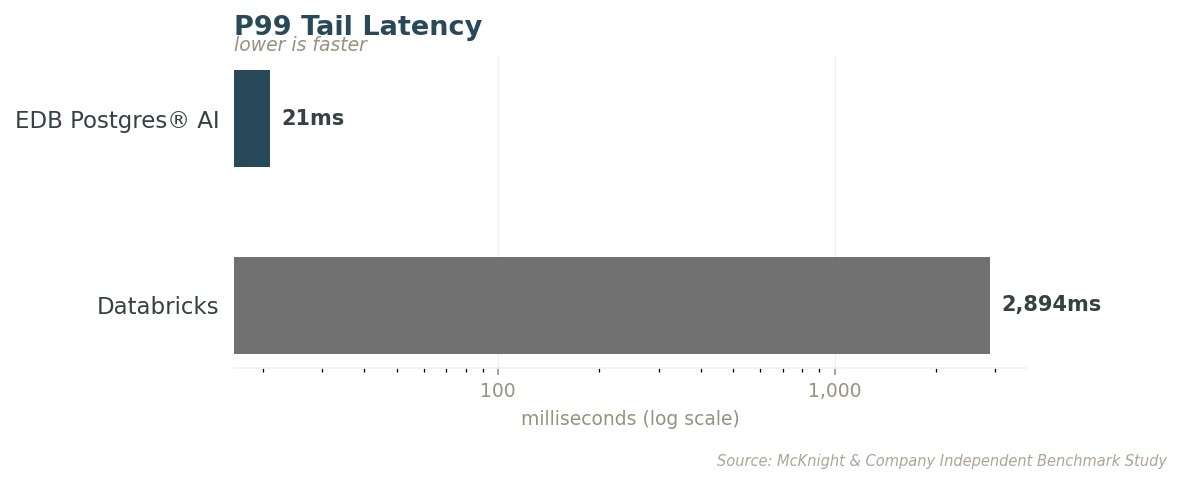
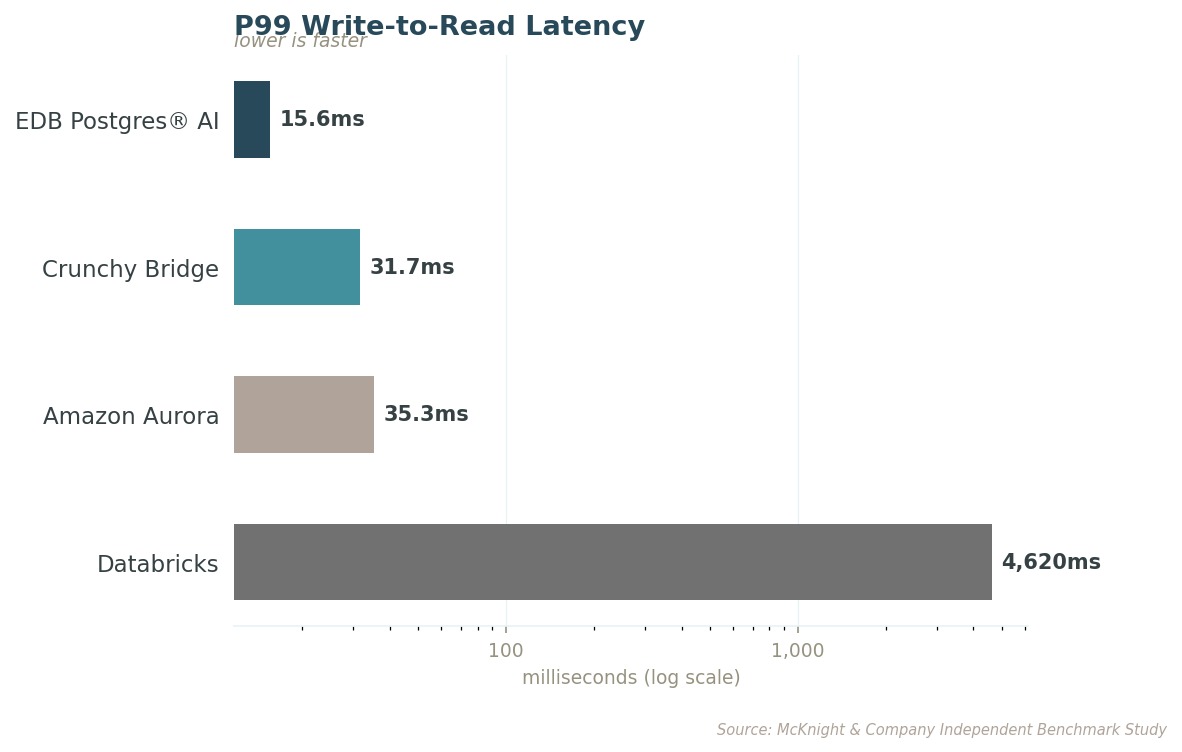
프로덕션에서 신뢰성을 결정하는 건 평균이 아닙니다. 테일 지연(tail latency)은 최악의 쿼리가 어떻게 동작하는지를 측정하며, 이것이 실제 사용자가 체감하는 값입니다. EDB의 최악 쿼리조차 Databricks의 최악 쿼리보다 138배 빠릅니다.
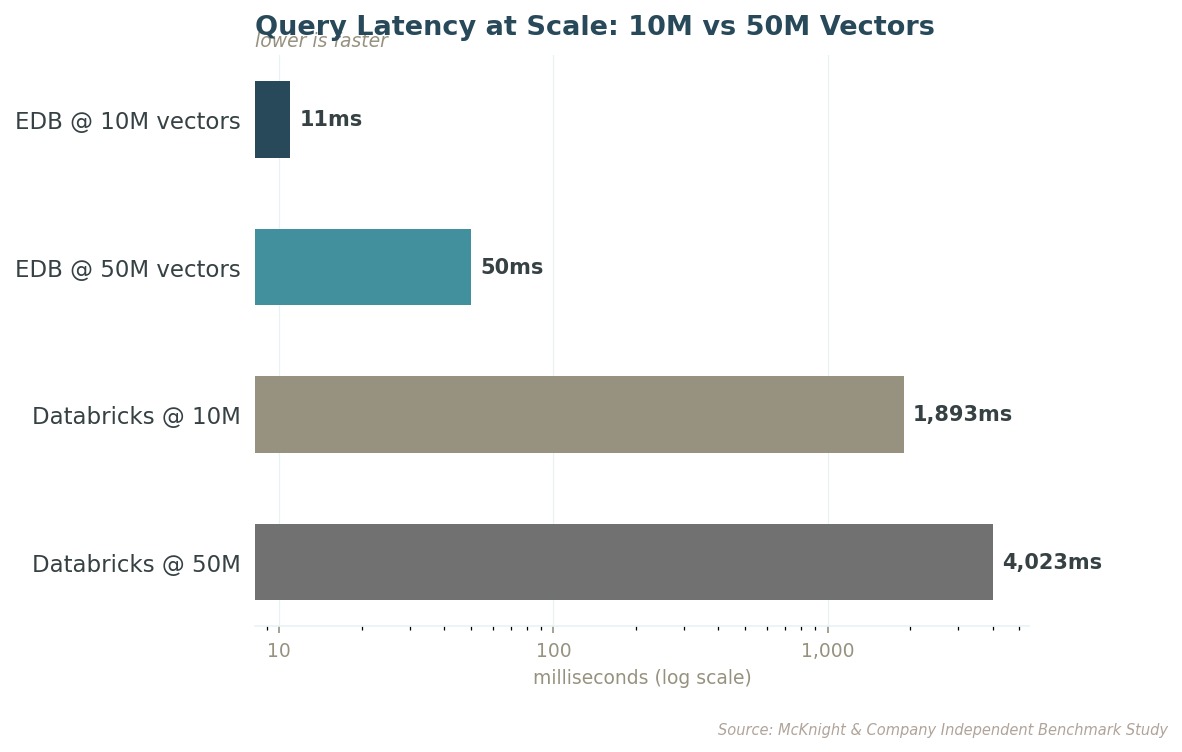
이 격차는 규모가 커진다고 줄어들지 않습니다. 오히려 벌어집니다. 은행은 카드 거래를 100밀리초 안에 승인하거나 거절합니다. 벡터 5,000만 개 규모에서도 EDB PG AI는 여전히 그 시간 안에 들어옵니다. Databricks는 그러지 못합니다.
하이브리드 검색: 프로덕션에서 실제로 돌아가는 쿼리
순수 벡터 검색만 쓰는 프로덕션 애플리케이션은 드뭅니다. 실제 쿼리는 시맨틱 검색과 구조화된 필터링을 결합합니다. 속도도 중요하지만, 올바른 결과가 돌아오느냐도 그만큼 중요합니다.
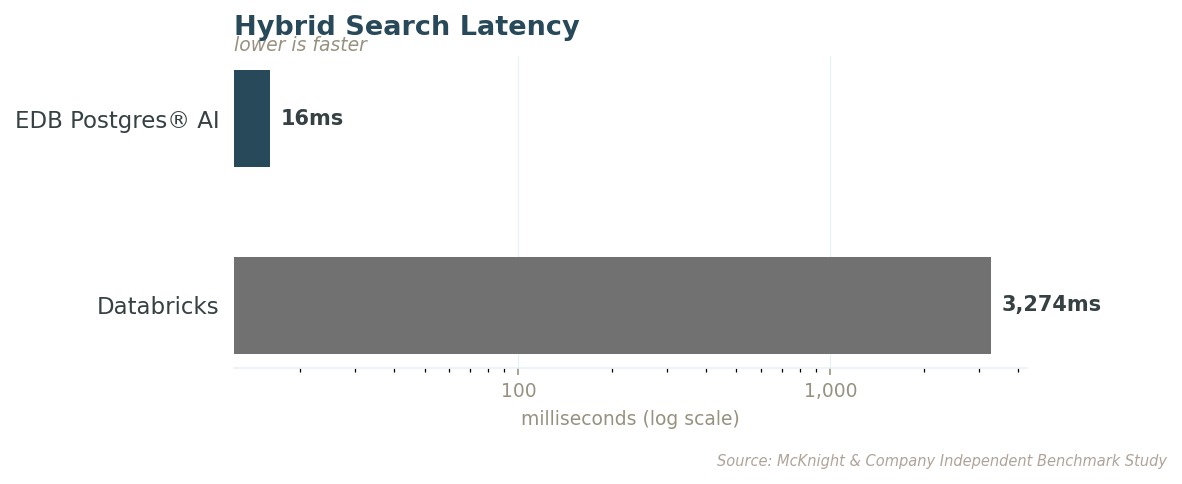
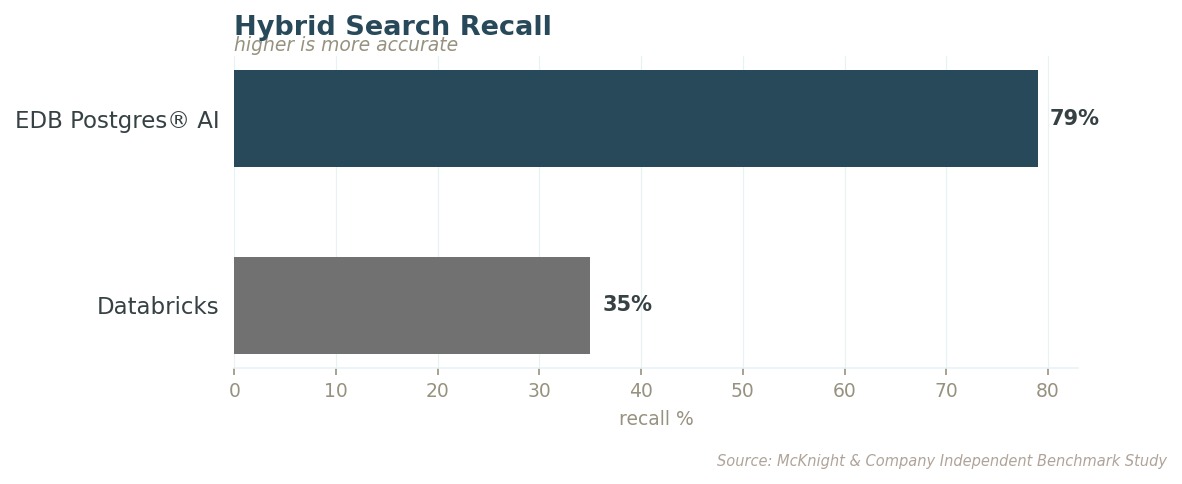
가장 까다로운 필터 수준에서, EDB PG AI는 관련 결과를 두 배 넘게 돌려줍니다. 그것도 지연 시간은 몇 분의 일 수준으로요. 희귀한 약물 상호작용을 가진 환자의 유사 사례를 찾아달라고 에이전트에게 요청하는 의사는, 어느 쪽 시스템에서든 추천을 받긴 받습니다. 차이는 그 추천이 가용 근거의 79%로 만들어졌느냐, 아니면 35%로 만들어졌느냐입니다.
쓰기 신선도: 데이터의 타이밍이 곧 비즈니스일 때
대부분의 데이터베이스는 데이터를 쓰는 것과 그것을 검색 가능하게 만드는 것을 분리합니다. 다운스트림 비즈니스에 지장을 주고 싶지 않기 때문이죠. 하지만 실시간으로 동작하는 AI 에이전트에게 그 지연은 곧 오래된 정보로 판단을 내린다는 뜻입니다. 검색 가능해지는 데 4초가 걸리는 사기(fraud) 신호는, 에이전트가 결정을 내리던 그 순간에는 갖고 있지 못했던 신호입니다.
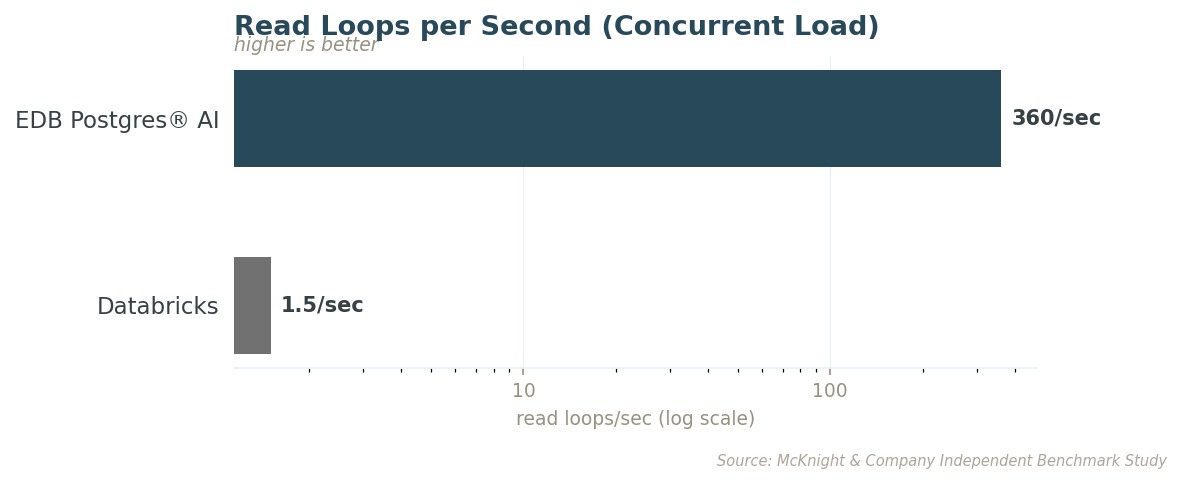
동시 부하 상황에서 EDB PG AI는 초당 360회의 읽기 루프를 처리합니다. 여러 에이전트가 동시에 돌아가는 동안 시스템이 데이터를 조회할 수 있는 횟수죠. Databricks는 1.5회입니다.
한 보험사의 청구 처리 에이전트는 사건 상태가 실시간으로 바뀌는 가운데 수백 건의 동시 업데이트를 처리합니다. EDB에서는 모든 업데이트가 16밀리초 안에 검색 가능해집니다. Databricks에서는 같은 업데이트가 다음 쿼리에 나타나기까지 최대 5초가 걸립니다.
재현율 정확도: 에이전트가 결정할 때 손에 쥔 근거
Recall@10은 에이전트가 내리는 모든 결정에 동원할 수 있는 근거의 완전성을 측정합니다. 존재하는 가장 관련성 높은 정보 10개 중, 시스템이 실제로 끌어내는 건 몇 개인가를 보는 것이죠.
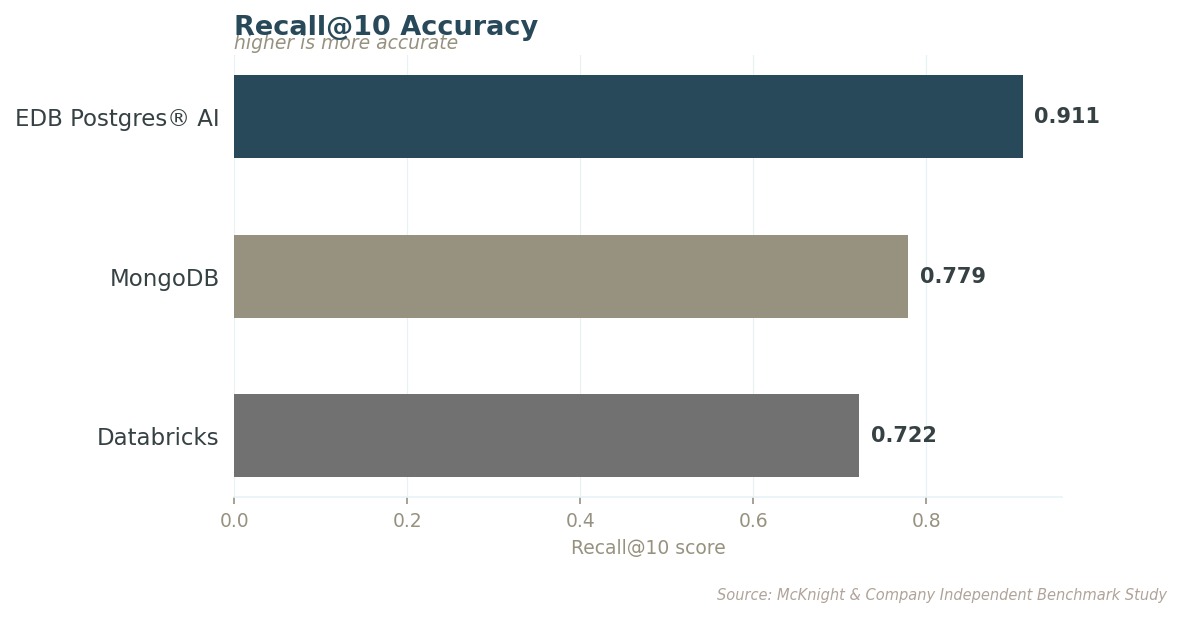
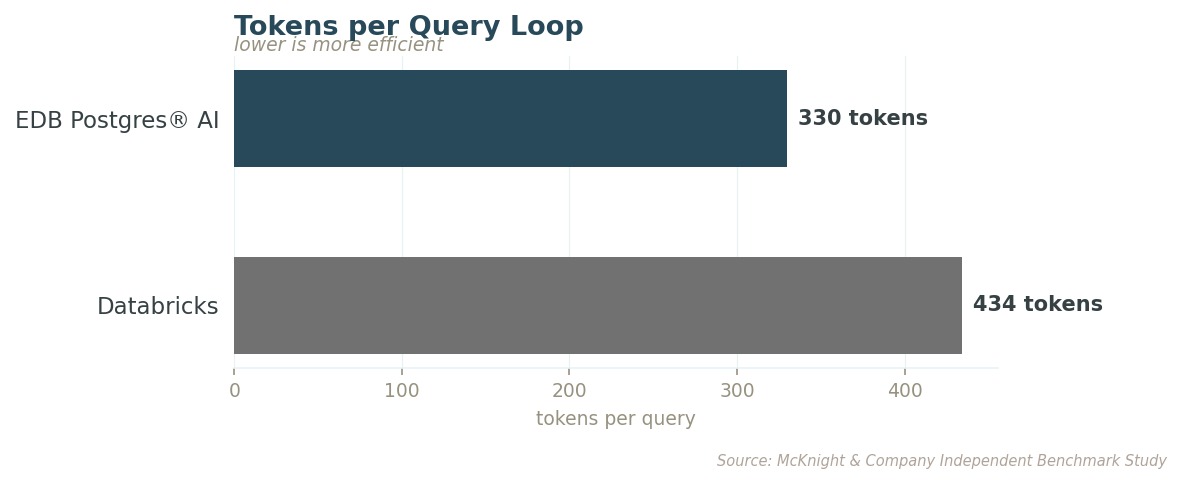
이 격차는 데이터가 커질수록 누적되고, 다운스트림 비용까지 동반합니다. Databricks는 쿼리 루프당 AI 모델에 토큰을 31% 더 보내면서도 관련 결과는 더 적게 돌려줍니다. EDB PG AI는 테스트한 모든 규모에서 더 적은 토큰으로 더 정확한 결과를 내놓습니다. 사용량이 늘수록 함께 커지는 품질·비용 이점이죠.
규제 산업에 이것이 의미하는 바
금융, 헬스케어, 통신, 정부는 공통의 제약을 안고 있습니다. AI 에이전트가 내리는 모든 결정은 결국 사람이나 규제 당국의 검토를 받게 된다는 점입니다. 그 결정의 품질은 전적으로, 에이전트가 접근할 수 있었던 데이터의 완전성과 적시성에 달려 있습니다.
일본 최대 지역 통신사 NTT 동일본(NTT East)은 네트워크 장애를 진단하고 엔지니어를 현장에 보낼지 원격으로 해결할지를 결정하는 운영 에이전트를 구축했습니다. 연간 1만 5천 건의 지원 통화가 들어오는 상황에서, 그 결정의 정확도가 곧 운영 비용을 좌우합니다. 관련 장애 패턴의 79%를 끌어내는 에이전트는 35%로 일하는 에이전트와는 다른 결론에 이릅니다. NTT 동일본은 에이전트가 올바른 결정을 내리게 함으로써 불필요한 출동의 20%, 연간 3천 건의 엔지니어 현장 방문을 없앴습니다.
사기 탐지와 로열티 에이전트를 함께 돌리는 한 결제 네트워크는 두 가지 결정을 실시간으로 마주합니다. 이 거래를 플래그할 것인가 승인할 것인가, 이 혜택을 밀 것인가 보류할 것인가. 에이전트가 근거를 끌어내면, 판단은 사람이 내립니다. 검토자는 원시 데이터를 평가하는 대신, 에이전트가 무엇을 골라 보여줬는지를 평가하기 시작합니다. 그 이후의 모든 판단은, 에이전트가 올바른 데이터 관리 기반을 갖췄는지에 달려 있습니다.
개인 맞춤형 혜택, 동적 신용 결정, 사기 개입을 통해 실시간 매출을 만들어내려는 한 신용카드사는, 대규모로, 완전한 감사 추적성과 함께, 밀리초 단위의 답이 필요합니다. 새 이벤트를 검색 가능하게 만드는 데 4초가 걸리는 플랫폼 위에서는 만들 수 없는 유스케이스죠.
NTT 동일본, 교보문고, MNTN 같은 고객들은 이미 이 전환을 이뤘습니다. 이들의 성과는 이 벤치마크와 함께 읽어볼 가치가 있습니다. 숫자가 작동 원리를 설명한다면, 이들의 경험은 그것이 실제로 어떤 모습인지를 보여줍니다.
이미 거기 있던 플랫폼
고객들이 거듭 되짚는 지점은 이것입니다. 대부분은 이미 Postgres를 갖고 있습니다. 컴플라이언스 체계도, 운영 경험도, 조직적 신뢰도 이미 있었습니다. 없었던 건, 그 기반을 또 다른 벤더, 또 다른 보안 심사, 또 다른 데이터 파이프라인 없이 분석과 AI로 확장해 줄 플랫폼이었습니다.
우리는 그 플랫폼을 만들었습니다. 벤치마크가 보여주듯, 이것은 전용 AI 데이터베이스로 가는 과도기적 징검다리가 아닙니다. 첫날부터 빠르고, 정확하고, 믿을 수 있어야 하는 에이전트를 위한 프로덕션 기반입니다.
에이전트는 데이터 관리 문제입니다. EDB PG AI가 그 답입니다.
참고 자료
- Comparative Performance and Cost Analysis of Modern Analytical Data Platforms, McKnight Consulting Group, 2026년 2월
- Gartner, Innovation Insight: Database Management Systems for Enterprise AI Agents, Xingyu Gu, Henry Cook, Aaron Rosenbaum, Ramke Ramakrishnan, Masud Miraz, 2025년 12월 1일. Gartner는 Gartner, Inc. 및/또는 그 계열사의 상표입니다.
EDB Postgres AI와 에이전트용 데이터 플랫폼, 더 알아보기
도입이나 PoC, 벤치마크 상세가 궁금하시다면 EDB Korea로 문의해 주세요.
- 이메일: salesinquiry@enterprisedb.com
- 전화: 02-501-5113
- 문의하기 →
원문: Agents Are a Data Problem — and EDB Postgres® AI Just Became the Answer (EDB Blog)
