
[실전 가이드] EDB Postgres® AI와 NVIDIA RAPIDS 가속기를 활용한 GPU 가속 쿼리 실행
작성일: 2026년 3월 16일
작성자: Dunith Danushka
이 핸즈온 튜토리얼은 NVIDIA RAPIDS Accelerator for Apache Spark를 사용해 EDB Postgres에서 GPU 가속 쿼리를 구현하는 방법을 소개한 [출시 블로그]의 후속 편입니다. 이 가이드는 EDB Postgres AI와 가속화된 Apache Spark 클러스터를 원활하게 통합하여 고성능 분석 환경을 구축하려는 데이터 엔지니어, 데이터 과학자, 솔루션 아키텍트를 위해 작성되었습니다.
실습을 바로 시작할 수 있도록 필요한 Docker Compose 스택과 설정이 포함된 GitHub 저장소를 함께 제공합니다.
본 가이드는 두 가지 주요 파트로 나뉩니다.
- Part 1: CPU 전용 스택으로 로컬 검증: CPU만을 사용하여 로컬 환경에서 전체 스택을 구성하고, 운영 환경으로 옮기기 전 소규모 TPC-DS 데이터셋(SF10)으로 연결성을 확인합니다.
- Part 2: NVIDIA Brev 환경에서 실행: GPU 가속 스택을 배포합니다. NVIDIA L40S GPU가 탑재된 Brev VM을 사용하여 spark-rapids 가속의 강력한 성능을 직접 확인합니다.
Part 1: CPU 전용 스택으로 로컬 환경 검증하기
Brev 환경의 NVIDIA L40S로 확장하기에 앞서, 로컬 환경에서 구성을 먼저 검증하는 것이 가장 좋습니다. 이 “CPU 전용(CPU-only)” 단계에서는 클라우드 GPU 비용을 들이지 않고도 EDB Postgres AI와 OSS Apache Spark 클러스터 간의 연결을 충분히 테스트할 수 있습니다.
컴포넌트 아키텍처 (Component Architecture)
스택을 실행하기 전에 각 구성 요소가 어떻게 상호작용하는지 살펴보겠습니다. 우리는 Postgres가 인터페이스와 메타데이터를 관리하고, Apache Spark 클러스터가 고성능 연산을 처리하는 “스토리지와 컴퓨팅의 분리(Separation of Storage and Compute)” 모델을 구축할 것입니다.
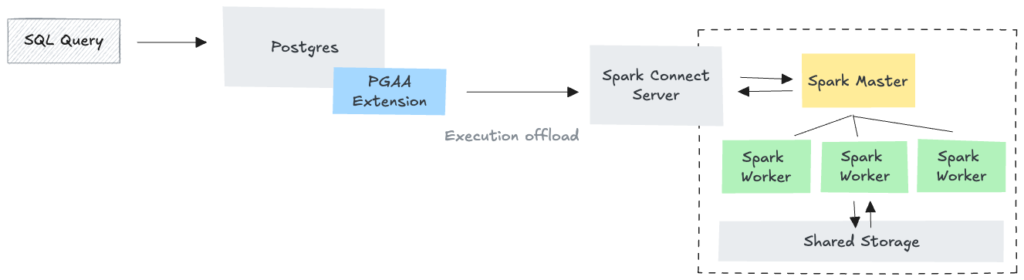
![그림 01 – Postgres, PGAA 및 Spark 컴포넌트 간의 경계]
로컬에서 실행하든 Brev 환경에서 실행하든 핵심 컴포넌트 아키텍처는 동일하게 유지됩니다.
- EDB Postgres (게이트웨이): EDB Analytics Accelerator(AA) 확장이 포함된 전용 Postgres 17 컨테이너입니다. 모든 SQL 쿼리의 진입점(Entry point) 역할을 합니다.
- OSS Apache Spark Master: 작업 분산을 조율하는 **컨트롤 플레인(Control plane)**입니다. 표준 OSS Apache Spark 3.5.6을 사용하여 PGAA가 광범위한 데이터 생태계와 얼마나 원활하게 통합되는지 증명합니다.
- OSS Apache Spark Workers: 실제로 데이터를 처리하는 워커 노드입니다.
- Spark Connect (브릿지): Postgres와 Spark 클러스터 사이의 인터페이스 역할을 합니다. 최신 Spark Connect 프로토콜을 사용하여 쿼리 실행 계획을 전달합니다.
환경에 따라 할당된 리소스나 GPU 가속 여부의 차이는 있지만, EDB Postgres, Spark Master, Spark Worker, Spark Connect로 이어지는 논리적 구조는 동일하게 유지됩니다.
사전 준비 및 환경 체크 (Prerequisites)
시작하기 전에 로컬 환경이 다음 요구 사항을 충족하는지 확인하세요. 로컬 GPU가 없더라도 걱정하지 마세요. 노트북에서 초기 개발 및 검증을 진행한 후, 실제 대량 연산 시에만 Brev 인스턴스로 전환하면 됩니다.
- EDB Token: EDB Postgres Analytics Accelerator(PGAA) 확장을 내려받기 위해
EDB_TOKEN이 필요합니다. [EDB 계정 등록 페이지]에서 토큰을 발급받으세요. - Docker Desktop: 버전 4.x 이상 (Docker Compose V2 포함).
- 시스템 리소스 (로컬): * CPU: 4코어 이상.
- RAM: 최소 16GB (TPC-DS SF10 실습을 위해 32GB 권장).
- 디스크: 여유 공간 50GB 이상.
- Git 클라이언트: 저장소 클론을 위한 Git 도구.
- AWS CLI: TPC-DS SF10 데이터셋 다운로드를 위해 로컬에 설치되어 있어야 합니다.
이 튜토리얼을 따라 하려면 모든 docker-compose 매니페스트와 PGAA 설정이 포함된 [실습용 GitHub 저장소]에 접근해야 합니다.
CPU 전용 스택 실행
로컬 환경의 하드웨어 리소스를 고려하여, 원활한 테스트를 위해 상대적으로 작은 데이터셋인 TPC-DS SF10을 사용합니다.
터미널에서 클론한 저장소로 이동하여 EDB_TOKEN을 설정한 뒤, 프로젝트 로컬 디렉토리에 데이터셋을 다운로드합니다.
Bash
# EDB 토큰 내보내기 export EDB_TOKEN=<발급받은_토큰_입력> # 저장소 클론 및 이동 git clone https://github.com/EnterpriseDB/spark-rapids-tutorial.git cd spark-rapids-tutorial/cpu-only # 데이터셋 다운로드 aws s3 cp s3://beacon-analytics-demo-data-us-east-1-prod/tpcds_sf_10 ./data/tpcds_sf_10 --recursive --no-sign-request
이제 다음 명령어로 스택을 실행합니다.
Bash
docker compose up -d --build
이 명령은 EDB Postgres 컨테이너를 빌드하고, Spark 이미지를 가져와 OSS Apache Spark 3.5.6 클러스터를 시작합니다. CPU 전용 버전은 nvidia 런타임과 spark-rapids jar 파일을 제외하며, 표준 Spark CPU 실행 방식에 의존합니다. 컨테이너가 가동되면 docker ps를 실행하여 postgres, spark-master, spark-worker-0, spark-connect 등 4개의 컨테이너가 정상 작동 중인지 확인하세요.
쿼리 실행 (Running Queries)
이제 Postgres 컨테이너가 Spark 클러스터에 정상적으로 접근할 수 있는지 확인해 보겠습니다. Postgres 컨테이너에 접속하여 psql 셸을 실행합니다.
Bash
docker compose exec postgres psql -U postgres
먼저 EDB Postgres Analytics Accelerator(pgaa) 확장을 활성화합니다.
SQL
CREATE EXTENSION IF NOT EXISTS pgaa CASCADE;
그다음 \dx 명령어를 입력해 pgaa와 pgfs 확장이 모두 설치되었는지 확인합니다. 이제 실행 엔진을 기본값인 seafowl에서 spark-connect로 변경하기 위해 아래의 GUC(Grand Unified Configuration) 설정을 실행합니다.
SQL
SET pgaa.executor_engine = 'spark_connect'; SET pgaa.spark_connect_url = 'sc://spark-connect:15002';
pgaa.spark_connect_url 설정은 15002 포트에서 실행 중인 spark-connect 컨테이너의 연결 URL을 지정하여 Postgres와 Spark 클러스터 간의 통신을 가능하게 합니다. 연결이 정상적인지 Spark 버전을 쿼리하여 확인합니다.
SQL
SELECT pgaa.spark_sql('SELECT version()');
Spark 버전이 정상적으로 출력된다면 성공입니다. \q를 입력해 셸을 빠져나옵니다.
그다음, TPC-DS 테이블을 생성하고 데이터를 채울 차례입니다. 저장소에 포함된 create_tables_for_spark_sf10.sql 스크립트를 사용하여 DDL 쿼리를 실행합니다.
Bash
cat create_tables_for_spark_sf10.sql | docker exec -i postgres psql -U postgres -d postgres
이 스크립트는 내부적으로 다음과 같은 작업을 수행합니다.
- 스토리지 위치 생성: 다운로드한 TPC-DS 데이터가 있는 위치를
pgfs를 통해 매핑합니다.SELECT pgfs.create_storage_location('spark_sf10', 'file:///data/tpcds_data'); - 테이블 생성: 각 테이블은
pgaa지시어를 통해 Parquet 형식의 파일을 로드하도록 설정됩니다.CREATE TABLE customer_address () USING PGAA WITH (pgaa.storage_location = 'spark_sf10', pgaa.path = 'customer_address', pgaa.format = 'parquet');
마지막으로, psql 터미널에서 샘플 쿼리를 실행하여 **”CPU 기준 성능(CPU Baseline)”**을 측정합니다. 이 수치는 나중에 GPU 가속 환경으로 옮겼을 때 성능 향상 폭을 비교하는 중요한 기준점이 됩니다.
SQL
WITH customer_total_return AS (
SELECT
sr_customer_sk AS ctr_customer_sk,
sr_store_sk AS ctr_store_sk,
SUM(sr_return_amt) AS ctr_total_return
FROM store_returns, date_dim
WHERE sr_returned_date_sk = d_date_sk
AND d_year = 2000
GROUP BY sr_customer_sk, sr_store_sk
)
SELECT c_customer_id
FROM customer_total_return ctr1, store, customer
WHERE ctr1.ctr_total_return > (
SELECT AVG(ctr_total_return) * 1.2
FROM customer_total_return ctr2
WHERE ctr1.ctr_store_sk = ctr2.ctr_store_sk
)
AND s_store_sk = ctr1.ctr_store_sk
AND s_state = 'TN'
AND ctr1.ctr_customer_sk = c_customer_sk
ORDER BY c_customer_id
LIMIT 100;
CPU 전용 로그를 보면 Spark 클러스터가 표준 Java 스레드를 사용하여 작업을 처리하는 것을 확인할 수 있습니다. SF10 데이터셋에서도 이 작업은 어느 정도 시간이 소요될 것입니다. 나중에 L40S GPU 환경에서 경험하게 될 “즉각적인” 결과와 비교하기 위해 실행 시간을 메모해 두세요.
Postgres와 Spark가 성공적으로 통신하는 것을 확인했다면, 이제 spark-rapids의 진정한 위력을 체험하기 위해 Part 2: Brev 환경 배포 단계로 넘어갈 준비가 되었습니다.
Part 2: NVIDIA Brev 환경에서 실행하기
대규모 데이터 분석을 위해, 우리는 L40S GPU가 탑재된 NVIDIA Brev VM을 사용합니다. NVIDIA Brev는 온디맨드 GPU 인스턴스를 제공하는 클라우드 플랫폼입니다. 강력한 계산 성능과 메모리 대역폭이 필수적인 spark-rapids 워크로드를 위해, 고성능 L40S GPU를 프로비저닝하여 실습을 진행해 보겠습니다.
1. Brev 인스턴스 프로비저닝 (Provisioning)
가장 먼저, L40S 인스턴스를 실행할 수 있는 충분한 크레딧이 Brev 계정에 있는지 확인하세요. 본 가이드에서 구축하는 인스턴스의 비용은 시간당 약 $2~$3입니다.
Brev 콘솔에 로그인한 뒤, 상단 메뉴에서 GPUs를 선택하고 Create Environment를 클릭하여 새로운 GPU 인스턴스를 생성합니다.

![그림 02 – NVIDIA Brev를 통한 빠른 GPU 환경 프로비저닝]
본 튜토리얼은 아래와 같은 사양의 Brev 인스턴스를 기준으로 구성되었습니다.
- 인스턴스 모드 (Instance Mode): VM Mode
- GPU: 2x NVIDIA L40S (각 48GB VRAM)
- 컴퓨팅 (Compute): 16 vCPUs
- 메모리 (Memory): 294 GiB RAM
- 스토리지 (Storage): 1.94TB 디스크 (SF100 데이터를 위해 NVMe 권장)
최소 1개 이상의 GPU가 있는 Brev 인스턴스라면 실습이 가능합니다. 다만, 가이드와 다른 구성을 사용할 경우 docker-compose.yml 파일에서 GPU 개수 설정을 해당 사양에 맞게 수정해야 한다는 점을 유의하세요.
VM 인스턴스 프로비저닝에는 약 2~3분이 소요됩니다. 대기하는 동안 로컬 머신에 Brev CLI를 설치하고, 콘솔의 Using Brev CLI (SSH) 지침에 따라 설정을 완료하세요. 본 가이드의 모든 상호작용은 주로 이 CLI를 통해 이루어집니다.
![그림 03 – 로컬 환경에 Brev CLI 도구 설치]
2. 필수 라이브러리 설치 및 디렉토리 권한 설정
프로비저닝이 완료되면 CLI를 사용하여 인스턴스에 접속합니다. 여기서는 인스턴스 이름을 tutorial이라고 가정하겠습니다.
Bash
brev shell tutorial
이 명령어를 실행하면 생성한 VM 인스턴스에 SSH 연결이 활성화되어, 원격 머신에서 직접 명령어를 실행하고 소프트웨어를 설치할 수 있는 상태가 됩니다.
다음으로, nvtop과 AWS CLI를 설치합니다.
Bash
sudo apt install awscli nvtop
- nvtop: GPU 사용률, 메모리 점유도, 실행 중인 프로세스를 실시간으로 시각화해 주는 가벼운 모니터링 도구입니다. 벤치마크 쿼리 실행 시 GPU 성능을 관찰하는 데 유용합니다.
- AWS CLI (awscli): 다음 단계에서 벤치마크 데이터셋을 다운로드하기 위해 필요합니다.
그 후, Spark가 사용할 디렉토리를 생성하고 권한을 부여합니다.
Bash
sudo mkdir /data sudo mkdir /data/spark-app sudo chmod 777 -R /data/spark-app
마지막으로, 환경 변수에 EDB_TOKEN을 내보냅니다.
Bash
export EDB_TOKEN=<발급받은_토큰_입력>
3. 코드 및 벤치마크 데이터셋 다운로드
VM의 홈 폴더(/home/ubuntu)에 실습용 GitHub 저장소를 클론합니다. 로컬에서 실행했던 것과 동일한 저장소이지만, 이번에는 spark-rapids가 활성화된 GPU 기반 Spark 클러스터를 실행하게 됩니다.
Bash
cd /home/ubuntu git clone https://github.com/dunithd/spark-rapids-tutorial.git cd spark-rapids-tutorial/gpu-2xl40s
이제 Parquet 형식의 TPC-DS 데이터셋을 다운로드할 차례입니다. spark-rapids의 진정한 위력을 확인하기 위해, 압축 후에도 수 기가바이트에 달하는 SF100(Scale Factor 100) 데이터셋을 사용하겠습니다.
데이터셋을 수용할 수 있는 충분한 공간을 확보하기 위해 인스턴스의 /ephemeral 볼륨에 저장합니다. (df -h 명령어로 확인해 보면 약 1TB의 여유 공간이 있는 것을 볼 수 있습니다.)
아래 명령어를 실행하여 데이터셋을 다운로드하세요.
Bash
aws s3 cp s3://beacon-analytics-demo-data-us-east-1-prod/tpcds_sf_100 /ephemeral/tpcds_sf_100 --recursive --no-sign-request
필수 라이브러리 설정과 데이터셋 다운로드가 완료되었습니다. 이제 Docker Compose 스택을 실행하고 본격적인 GPU 가속 쿼리를 수행할 준비가 모두 끝났습니다.
Deep Dive: spark-rapids 통합 분석
GPU 가속 스택을 본격적으로 가동하기 전에, 각 컴포넌트가 어떻게 상호작용하는지 자세히 살펴보겠습니다. 구조적으로는 앞서 살펴본 CPU 스택과 거의 동일하지만, spark-rapids 라이브러리가 추가되고 그에 따른 리소스 할당 방식이 달라진 것이 핵심입니다.
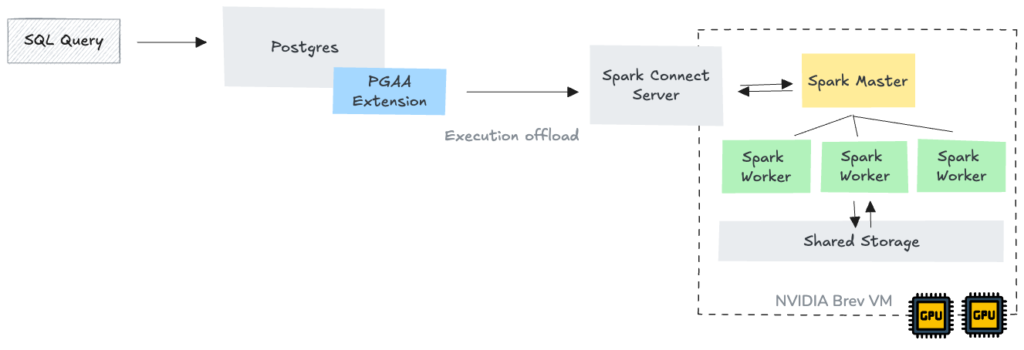
![그림 04 – Brev 환경에서의 Docker Compose 스택 구성. Spark Connect에 spark-rapids jar가 추가되고 Spark 워커가 GPU에 접근할 수 있습니다.]
핵심 구성 요소 (Core Components)
./gpu-2xl40s/docker-compose.yml 파일은 크게 네 가지 논리적 단위를 정의합니다.
- EDB Postgres (게이트웨이): EDB Analytics Accelerator(AA) 확장이 탑재된 전용 Postgres 17 컨테이너입니다. SQL 쿼리를 받아들이는 진입점입니다.
- OSS Apache Spark Master: 태스크 분산을 조율하는 컨트롤 플레인입니다.
- OSS Apache Spark Workers: nvidia 런타임으로 설정되어 L40S 하드웨어에 직접 접근하여 연산을 수행합니다.
- Spark Connect (브릿지): Postgres와 Spark 클러스터 사이의 인터페이스입니다.
실제 “마법”이 일어나는 부분은 compose 파일 내의 spark-connect 설정 섹션입니다.
YAML
spark-connect:
<<: *spark-common
container_name: spark-connect
depends_on: ["spark-master"]
ports: ["4040:4040", "15002:15002"]
command: >
/opt/spark/sbin/start-connect-server.sh --master spark://spark-master:7077
--packages "org.apache.spark:spark-connect_2.12:3.5.6,com.nvidia:rapids-4-spark_2.12:25.10.0,io.delta:delta-spark_2.12:3.3.1,org.apache.hadoop:hadoop-aws:3.3.4"
--conf "spark.executor.extraClassPath=/data/spark-app/jars/com.nvidia_rapids-4-spark_2.12-25.10.0.jar"
--conf "spark.plugins=com.nvidia.spark.SQLPlugin"
--conf "spark.rapids.memory.pinnedPool.size=8g"
--conf "spark.rapids.sql.concurrentGpuTasks=3"
--conf "spark.shuffle.manager=com.nvidia.spark.rapids.spark356.RapidsShuffleManager"
# ... (기타 세부 설정 생략)
우리는 단순히 Spark를 실행하는 것이 아니라, 다음 세 가지 중요한 계층을 통해 Spark 엔진에 NVIDIA spark-rapids 가속기를 주입합니다.
1. 플러그인 주입 (Plugin Injection)
spark.plugins=com.nvidia.spark.SQLPlugin 설정을 통해 Spark가 표준 CPU 쿼리 계획을 가로채도록 합니다. Join이나 Aggregate와 같은 연산이 spark-rapids에서 지원되는 경우, Spark는 CPU 버전 대신 고도로 병렬화된 GPU 커널로 연산을 교체합니다.
2. 지능형 GPU 메모리 관리
TPC-DS SF100과 같은 대규모 데이터셋은 GPU 메모리를 빠르게 점유합니다. 안정성을 위해 다음 설정을 튜닝했습니다.
spark.rapids.memory.pinnedPool.size=8g: 시스템 RAM과 GPU VRAM 간의 데이터 전송 속도를 비약적으로 높여주는 “Pinned” 호스트 메모리를 예약합니다.spark.rapids.sql.concurrentGpuTasks=3: 여러 태스크가 하나의 GPU를 공유할 수 있게 하여 L40S의 방대한 코어 활용률을 극대화합니다.
3. 가속화된 셔플 (Accelerated Shuffle)
Spark에서 워커 간에 데이터를 이동시키는 **”셔플(Shuffling)”**은 가장 큰 병목 구간입니다. RapidsShuffleManager를 사용하면 GPU를 활용해 데이터를 압축하고 이동시키므로 I/O 대기 시간을 획기적으로 줄일 수 있습니다.
가속 스택 실행 (Launching)
다음 명령어를 실행하여 백그라운드에서 서비스를 시작합니다.
Bash
docker compose up -d --build
쿼리를 실행하기 전에 Spark가 L40S 하드웨어를 정상적으로 인식하는지 확인해야 합니다. 먼저 호스트에서 nvidia-smi를 실행하여 48GB VRAM을 가진 L40S GPU 2개가 표시되는지 확인하세요.
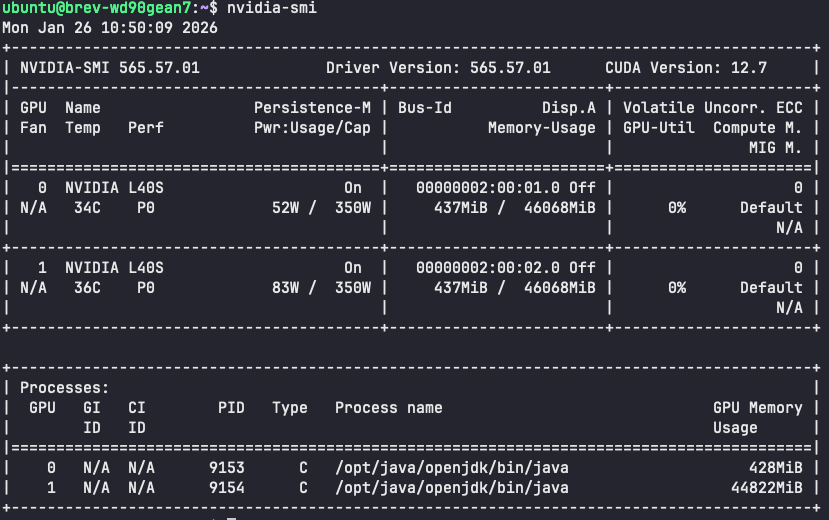
그다음, 워커 컨테이너 내부에서도 GPU가 보이는지 확인합니다.
Bash
docker exec -it spark-worker-0 nvidia-smi
컨테이너 내부에서도 동일한 GPU 상태 테이블이 나타나야 합니다. 또한 spark-connect 로그를 통해 가속기가 활성화되었는지 최종 확인합니다.
Bash
docker compose logs spark-connect | grep -i "RAPIDS Accelerator" # 출력 결과에 "RAPIDS Accelerator 25.10.0: enabled"가 포함되어야 합니다.
마지막으로, 로컬 터미널에서 포트 포워딩을 설정하여 4040 포트로 Spark UI에 접속할 수 있도록 합니다.
Bash
brev port-forward tutorial -p 8080:8080 -p 4040:4040
이제 웹 브라우저에서 http://localhost:4040으로 접속하여 Spark UI를 볼 수 있습니다.
GPU 가속 쿼리 실행
이제 모든 준비가 끝났습니다. TPC-DS SF100용 테이블을 생성하고 데이터를 로드합니다.
Bash
cat create_tables_for_spark_sf100.sql | docker exec -i postgres psql -U postgres -d postgres
이제 실제 쿼리를 던져볼 차례입니다. 새로운 터미널 세션에서 nvtop을 실행하여 GPU 사용량을 실시간으로 모니터링하면서, 기존 터미널의 psql에서 아래의 복잡한 TPC-DS 쿼리를 실행해 보세요.
SQL
WITH customer_total_return AS (
SELECT
sr_customer_sk AS ctr_customer_sk,
sr_store_sk AS ctr_store_sk,
SUM(sr_return_amt) AS ctr_total_return
FROM store_returns, date_dim
WHERE sr_returned_date_sk = d_date_sk
AND d_year = 2000
GROUP BY sr_customer_sk, sr_store_sk
)
SELECT c_customer_id
FROM customer_total_return ctr1, store, customer
WHERE ctr1.ctr_total_return > (
SELECT AVG(ctr_total_return) * 1.2
FROM customer_total_return ctr2
WHERE ctr1.ctr_store_sk = ctr2.ctr_store_sk
)
AND s_store_sk = ctr1.ctr_store_sk
AND s_state = 'TN'
AND ctr1.ctr_customer_sk = c_customer_sk
ORDER BY c_customer_id
LIMIT 100;
이 쿼리는 다음과 같은 이유로 GPU 성능 테스트에 최적화되어 있습니다.
- 복잡한 조인(Complex Joins): 4개 이상의 대형 테이블을 조인합니다.
- 공통 테이블 표현식(CTE): Spark가 클러스터 전체에서 최적화해야 하는 임시 뷰를 생성합니다.
- 서브쿼리:
AVG(...) * 1.2계산을 위한 브로드캐스트 또는 셔플 조인이 발생하며, 여기서 RAPIDS Shuffle Manager의 성능이 빛을 발합니다.
쿼리가 실행되는 동안 nvtop을 보면 두 개의 GPU 사용량이 치솟는 것을 시각적으로 확인할 수 있습니다.
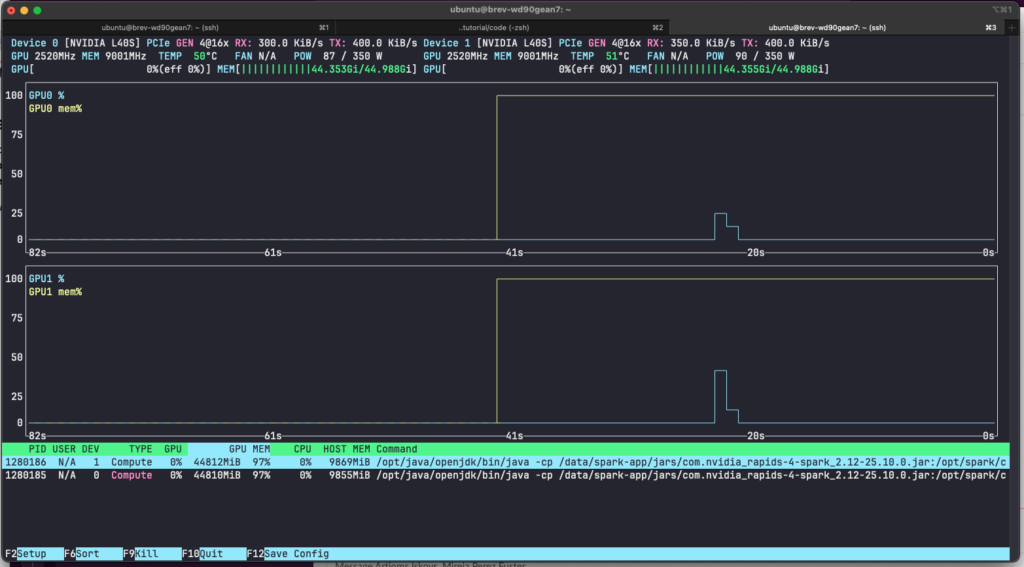
![그림 06 – 쿼리 실행 중 GPU 사용률의 변화를 보여주는 nvtop 화면]
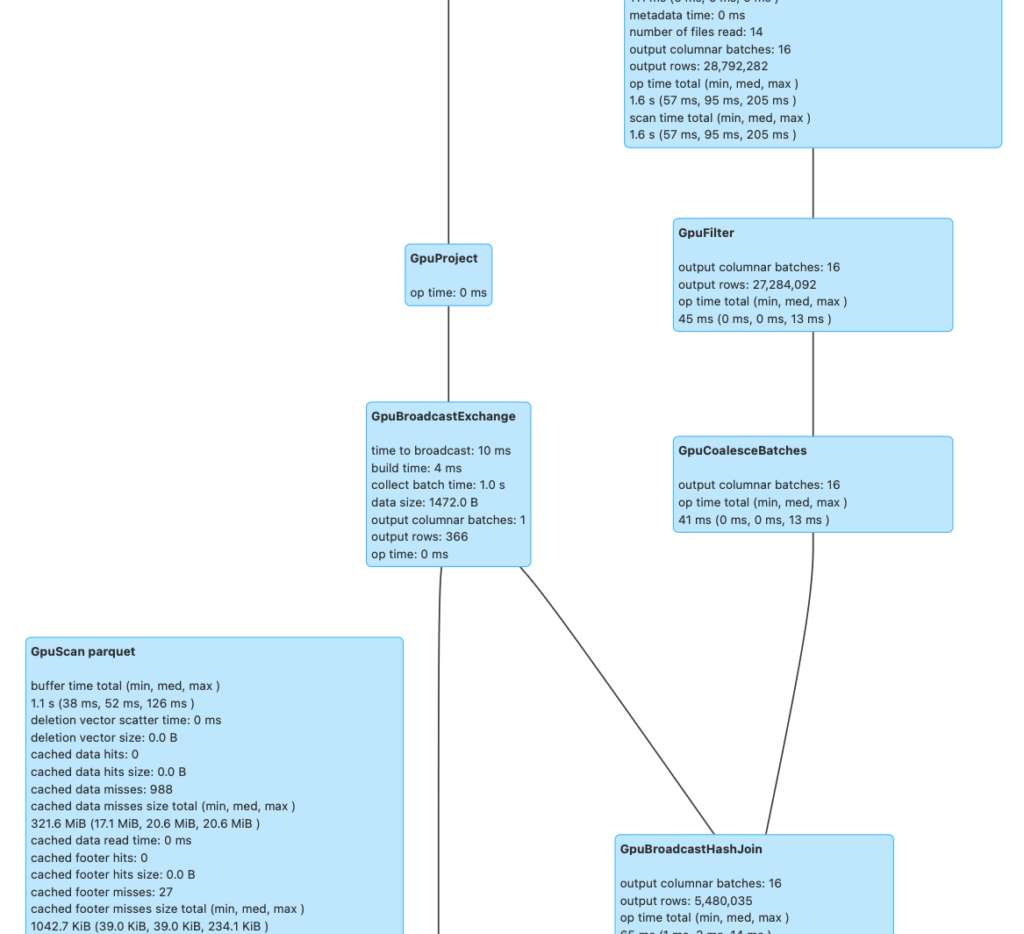
또한 Spark UI(http://localhost:4040)의 SQL 탭에서 실행 중인 쿼리를 클릭해 보세요.
- “Gpu” 노드 확인: 실행 계획(Physical Plan)에서 기존 노드들이
GpuHashJoin,GpuHashAggregate,GpuColumnarExchange등 GPU 버전으로 교체된 것을 볼 수 있습니다. - 전환 노드: 데이터가 로드될 때의
GpuRowToColumnar와 결과가 반환될 때의GpuColumnarToRow노드도 확인할 수 있습니다.
결론
이 튜토리얼을 통해 CPU 전용 기준점(Baseline) 수립부터 NVIDIA Brev VM 상에서의 완벽한 GPU 가속 EDB Postgres AI 및 Apache Spark 클러스터 배포까지 전 과정을 마쳤습니다.
우리는 EDB Analytics Accelerator와 Spark의 원활한 통합을 확인했으며, 복잡한 쿼리 계획이 GPU 커널로 오프로드되는 과정을 검증했습니다. 특히 TPC-DS SF100과 같은 대규모 데이터셋에서 RAPIDS Shuffle Manager와 L40S GPU가 제공하는 압도적인 성능 향상을 목격했습니다.
이번 실무 경험은 여러분의 운영 환경에 GPU 가속 분석을 도입하는 데 강력한 토대가 될 것입니다. 더 자세한 설정 옵션과 고급 튜닝 가이드는 [EDB 공식 문서]를 확인해 주세요.
메일: salesinquiry@enterprisedb.com
