
말뿐인 AI 도입은 그만! EDB Postgres AI로 구현하는 5가지 실전 구축 사례 (Build, Scale, and Govern)
Purnima Phansalkar
December 08, 2025
금융 서비스를 비롯한 규제 산업군의 IT 리더들이 느끼는 현대화(Modernization) 압박은 그 어느 때보다 높습니다. 데이터 볼륨은 폭증하고, 고객의 기대치는 높아지며, 컴플라이언스 요건은 더욱 까다로워지고 있습니다.
많은 기업이 “무엇”을 해야 하는지는 알고 있습니다. 하지만 레거시 시스템, 비용이 많이 드는 상용 DB(Oracle 등), 운영 리스크라는 장벽 앞에서 “어떻게(How)” 실질적이고 안전하게 현대화를 이룰 것인지에 대해서는 여전히 고민하고 있습니다.
이번 포스팅에서는 최근 진행된 ‘Build with EDB Postgres® AI’ 웹캐스트 시리즈 중, 국내 엔터프라이즈 환경에 즉시 적용 가능한 5가지 핵심 데모 사례를 정리해 드립니다. 이것은 단순한 이론이 아니라, 실제 아키텍처와 구현 패턴을 보여주는 실전 가이드입니다.
EDB Postgres AI가 주목받는 이유
단순한 오픈소스 도입을 넘어, EDB는 다음과 같은 엔터프라이즈의 요구사항을 충족합니다:
- 엔터프라이즈급 안정성: 금융권의 필수 요건인 고가용성(HA), 보안, 컴플라이언스 준수.
- AI-Ready 데이터 플랫폼: 데이터 제어권을 잃지 않으면서 AI 인사이트를 가속화.
- 운영 효율성 및 비용 절감: 클라우드 네이티브 배포 옵션과 자동화를 통한 Vendor Lock-in 탈피.
실전 데모: 5가지 핵심 활용 사례 (Use Cases)
다음은 실제 업무 환경에서 부딪히는 문제들을 EDB Postgres AI로 어떻게 해결했는지 보여주는 5가지 에피소드 요약입니다.
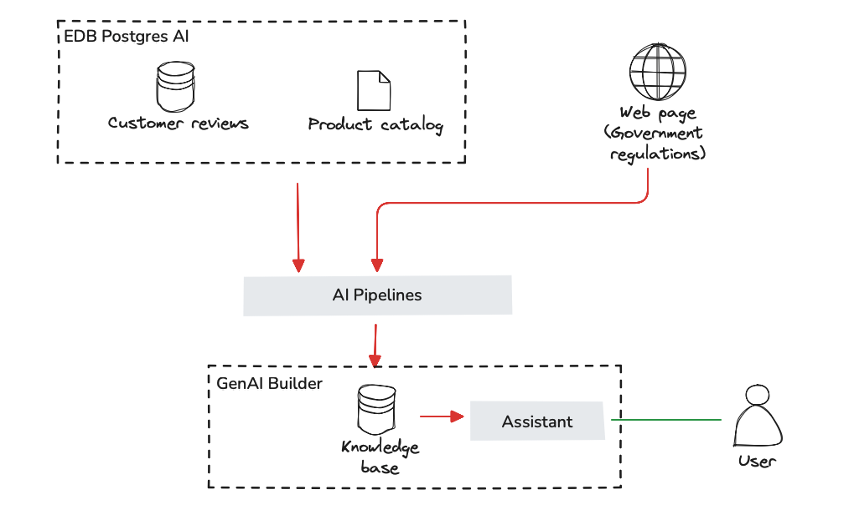
1. 사내 지식 베이스를 위한 AI 챗봇 구축 (RAG)
The Challenge: 현업 직원들은 여러 시스템(오브젝트 스토리지의 비정형 데이터, DB의 정형 데이터)에 흩어진 정보 때문에 정확한 규정이나 데이터를 찾는 데 시간을 허비합니다.
- 해결 방안: EDB PG AI Factory를 활용한 가상 어시스턴트 구현.
- 핵심 기술: GenAI Builder와 AI 파이프라인, 벡터(Vector) 지식 베이스를 활용합니다.
- 결과: 기업의 내부 지식(장기 기억)을 기반으로, 할루시네이션(환각)을 최소화하고 보안 가이드라인을 준수하는 ‘사실 기반’의 답변을 제공합니다. 정형/비정형 데이터를 모두 참조하여 답변의 정확도를 높입니다.
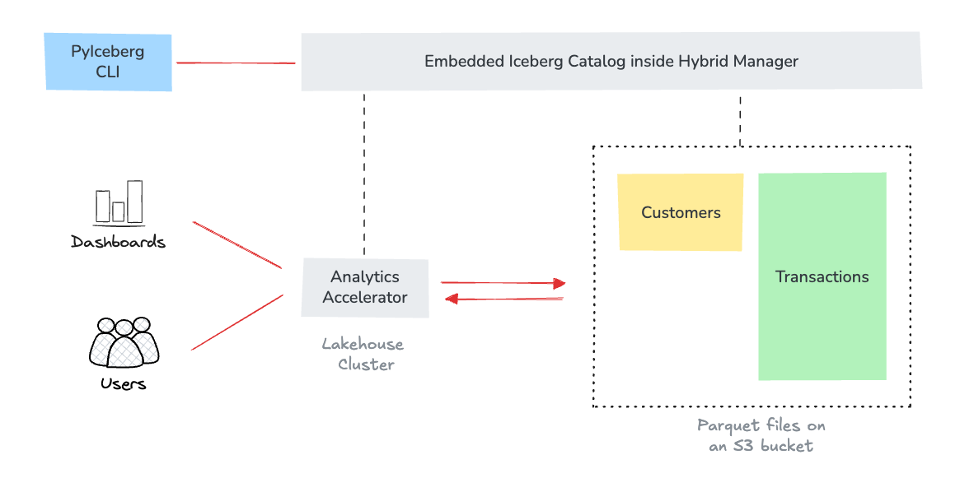
2. 레이크하우스(Lakehouse) 테이블 쿼리 및 거버넌스
The Challenge: 수 테라바이트(TB) 급의 이벤트 로그나 트랜잭션 데이터가 S3 기반의 레이크하우스(Iceberg/Parquet)에 쌓여 있습니다. 이를 분석하기 위해 데이터를 DB로 옮기는 것은 비효율적입니다.
- 해결 방안: EDB PG AI Analytics Accelerator와 임베디드 Iceberg Catalog 활용.
- 핵심 기술: 데이터를 이동(ETL)하지 않고, Postgres에서 직접 Iceberg 테이블을 쿼리합니다.
- 결과: PGAdmin과 같은 친숙한 Postgres 도구를 그대로 사용하여 레이크하우스 데이터를 조회 및 관리할 수 있습니다. 이를 통해 고객 세분화나 마케팅 캠페인을 위한 실시간 분석이 가능해집니다.
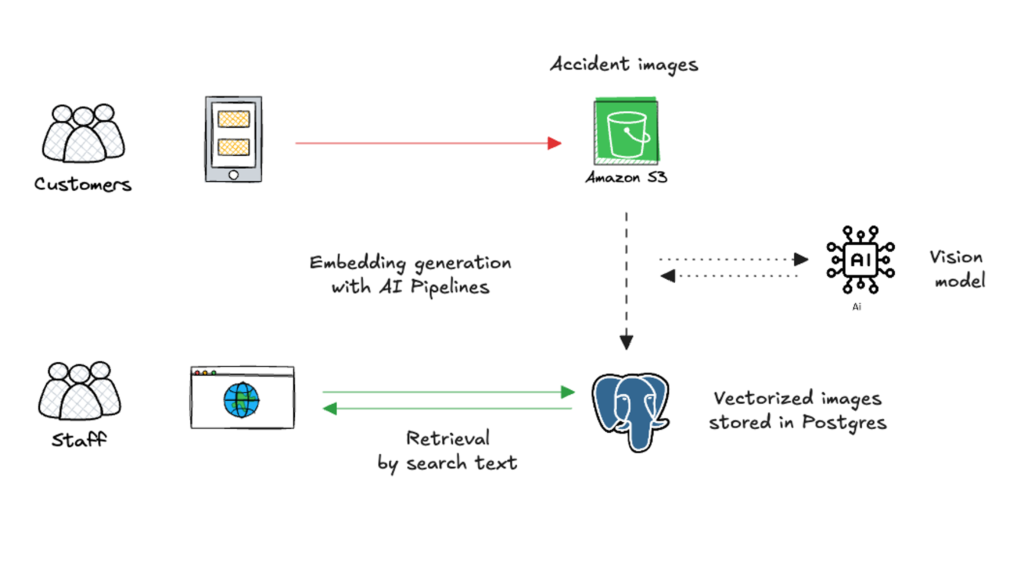
3. 다양한 데이터에 대한 멀티모달(Multi-Modal) 검색
The Challenge: 보험 사기 탐지 등을 위해서는 텍스트뿐만 아니라 ‘이미지(예: 사고 현장 사진)’와 같은 비정형 데이터 검색이 필요합니다. 기존의 키워드 검색으로는 한계가 있습니다.
- 해결 방안: 로우코드(Low-code) AI 파이프라인을 통한 멀티모달 검색 엔진 구축.
- 핵심 기술: SQL과 CLIP 모델을 사용하여 이미지(S3 등 저장소)에서 벡터 임베딩을 생성하고 Postgres에 저장합니다.
- 결과: 사용자가 “빨간색 차량의 측면 충돌 사진”과 같이 자연어로 검색하면, 의미론적(Semantic)으로 일치하는 이미지를 찾아냅니다.
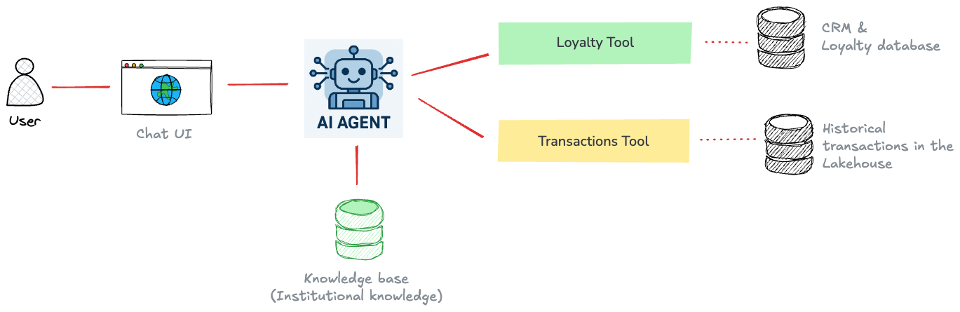
4. AI 에이전트를 활용한 능동적 분석 (Agentic Analytics)
The Challenge: 영업 담당자(AE)는 고객의 트랜잭션 기록, 로열티 상태, 제품 문서는 흩어져 있는 데이터를 통합하여 영업 기회를 포착해야 합니다. IT팀에 데이터 추출을 요청하고 기다리는 과정에서 비즈니스 기회를 놓칩니다.
- 해결 방안: Analytics Accelerator와 AI Factory를 결합한 AI 에이전트 도입.
- 핵심 기술: Postgres의 CRM 데이터와 레이크하우스의 트랜잭션 데이터를 통합(Federated)하여 접근합니다. Agent Studio로 제작된 AI 에이전트가 추론 모델을 통해 데이터를 조회, 해석하고 추천 제안을 생성합니다.
- 결과: 영업 담당자는 백엔드 팀을 기다릴 필요 없이, 실시간으로 개인화되고 컴플라이언스를 준수하는 영업 인사이트를 확보할 수 있습니다.
5. Postgres에서의 시계열(Time-Series) 데이터 처리
The Challenge: 금융 기관은 매일 수백만 건의 신용카드 거래 내역(Append-only)을 처리합니다. 이로 인해 DB 용량이 급증(Bloat)하고, 규제에 따른 데이터 보관 비용이 기하급수적으로 늘어납니다.
- 해결 방안: 시계열 워크로드를 위해 설계된 Bluefin 확장 기능(Extension) 도입.
- 핵심 기술: Bluefin은 델타 압축(Delta-compressed) 저장 방식을 사용하여 표준 힙(Heap) 테이블 대비 저장 공간을 획기적으로 줄입니다.
- 결과: 데이터 저장 비용을 절감하는 동시에, 대규모 데이터에 대한 트렌드 분석 및 집계 쿼리 성능을 가속화합니다.
결론: 단일 플랫폼에서의 혁신
트랜잭션 시스템의 현대화, 데이터 레이크하우스 통합, 혹은 자율 AI 에이전트 도입 등 어떤 목표를 가지고 있든 EDB Postgres AI는 **데이터 주권(Sovereignty)**을 보장하는 엔드 투 엔드 기반을 제공합니다.
데이터 수집, 거버넌스, 분석, 벡터 검색, 파이프라인, 에이전트 오케스트레이션이 분리된 솔루션이 아니라 하나의 통합된 플랫폼에서 이루어질 때, 기업은 비용 구조를 통제하면서 혁신 속도를 높일 수 있습니다.
Next Step for You: 우리 회사 인프라 환경에 맞는 구체적인 아키텍처 설계나, 위에서 언급된 기능(특히 Bluefin이나 Analytics Accelerator)에 대한 심층적인 기술 미팅이 필요하시다면 **’1:1 맞춤형 워크샵’**을 요청해 주십시오. EDB 전문가가 귀사의 요구사항을 분석하여 최적의 로드맵을 제안해 드립니다.
메일: salesinquiry@enterprisedb.com
