
📬 EDB 엔지니어링 뉴스레터 #7
2025년 6월 9일
EDB 엔지니어링 뉴스레터 7번째 호에 오신 것을 환영합니다!
이번 호에서는 EDB 엔지니어링 팀이 주목하고 있는 데이터 업계 소식과 팀의 최신 활동을 공유합니다.
분석 트렌드
Conflict-free Replicated Data Types (CRDTs) 시리즈

UC 버클리의 Joe Hellerstein 교수가 CRDT(충돌 없는 복제 데이터 타입)에 대한 연재글을 게시했습니다.
- CRDT 소개
- CRDTs #2: Turtles All the Way Down
- CRDTs #3: Do Not Read!
- CRDTs #4: Convergence, Determinism, Lower Bounds and Inflation
엔비디아 기술의 시

엔비디아 초기 멤버이자 전 수석 과학자인 David Rosenthal이 엔비디아 초기 혁신 기술(이미징 모델과 I/O 아키텍처)에 대한 심층 기술 설명을 블로그에 공유했습니다.
👉 The Dawn of Nvidia’s Technology
AI가 분산 시스템을 바꾸는 혁명

Azure Storage의 Cheng Huang 기술 리드가 GitHub Copilot Agent가 Azure Storage 프로덕션 코드 분석과 TLA+ 모델 생성을 통해 실제 프로덕션 버그를 찾아낸 사례를 공유했습니다.
👉 AI Revolution in Distributed Systems
이에 대한 Hillel Wayne의 반응도 흥미롭습니다:
현재 AI 에이전트는 TLA+의 반복적이고 루틴한 작업에는 능숙하지만 전략적/추상화 측면은 약합니다. 그러나 루틴 작업이 TLA+ 입문자에게 큰 장벽이었기 때문에, LLM이 TLA+를 훨씬 더 접근 가능하게 만들 잠재력이 있습니다.
비슷한 맥락의 글로는:
- Steve Klabnik: I am disappointed in the AI discourse
- Armin Ronacher: AI Changes Everything
AI 수요 1000배 증가

AI 활용이 단순 작업에서 복잡한 추론 중심으로 변화하면서 컴퓨팅 수요가 급증하고 있습니다. OpenAI, Microsoft, Google 등이 이를 선도하고 있으며, Microsoft는 2025년 1분기에만 100조 개 이상의 토큰을 처리(전년 대비 5배 증가)했습니다.
이를 위해 하이퍼스케일러들은 매주 약 72,000대의 NVIDIA GPU를 배치하고 있으며, AI 데이터 센터 인프라(‘AI 팩토리’)에 3천억 달러 이상을 투자하고 있습니다. 모델 효율성 개선에도 불구하고 복잡한 AI 추론 수요가 이를 상회하며 AI 인프라의 폭발적 성장을 주도하고 있습니다.
클라우드 GPU 비교 사이트
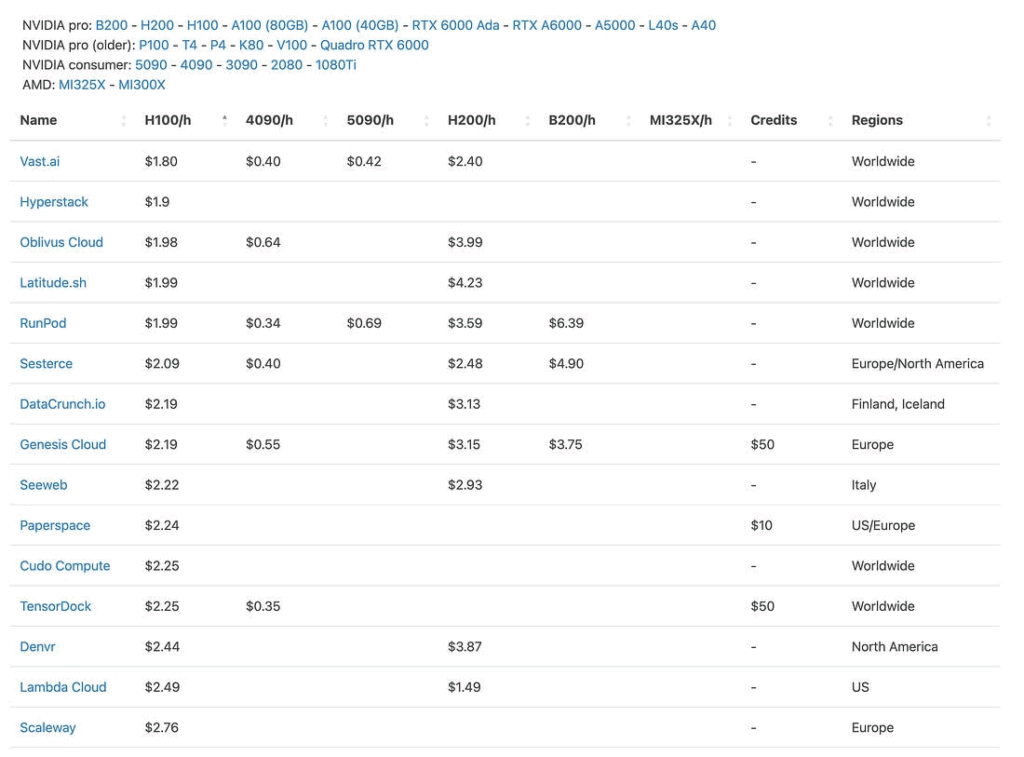
LLM 엔진 벤치마크
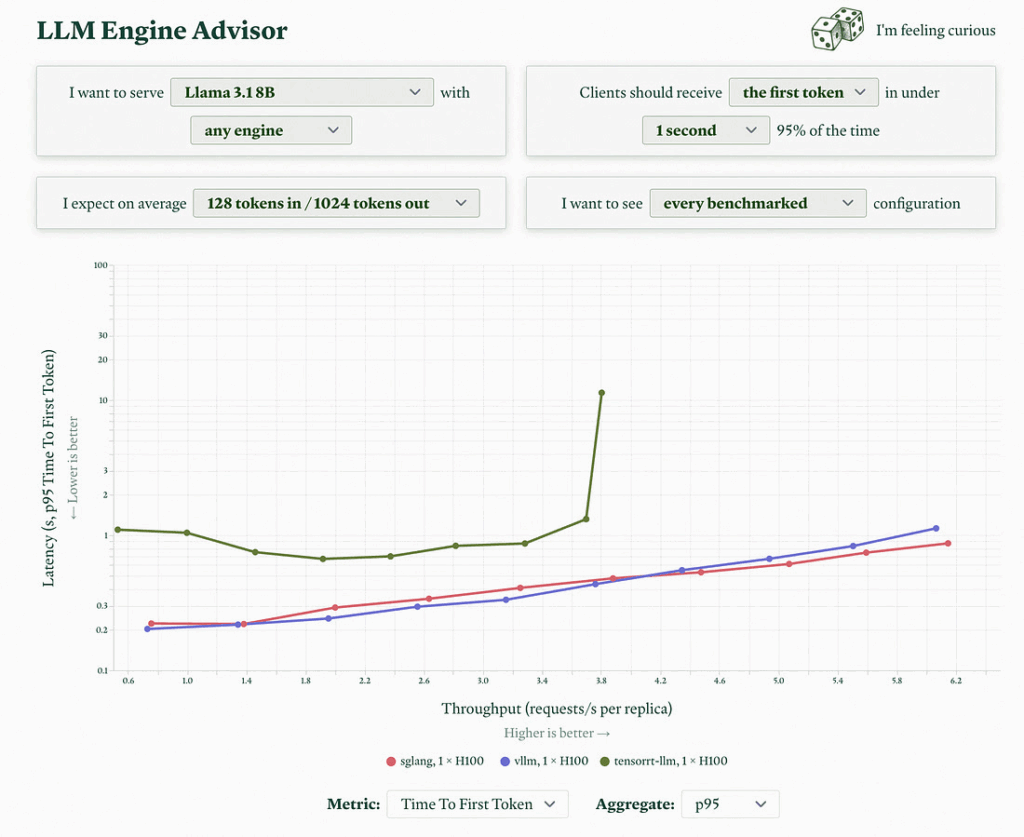
Modal이 오픈 소스 언어 모델과 추론 엔진에 대한 상호작용형 벤치마크 결과를 공개했습니다. 자체 인프라에서 LLM을 운영하려는 조직에 유용합니다.
👉 https://modal.com/llm-almanac/
주목하는 뉴스
Google AI Edge Gallery

Google이 오픈소스 AI 모델을 스마트폰에서 오프라인으로 실행할 수 있는 안드로이드 앱을 출시했습니다. Hugging Face 모델 지원, 프라이버시 보호, 오프라인 실행 등이 특징입니다.
👉 https://github.com/google-ai-edge/gallery
CloudNativePG 기여자 인터뷰 시리즈

이번 달에는 Tembo의 Jeff Wheeler, EDB의 Francesco Canovai, Gisual의 Jeff Mealo 인터뷰가 포함되었습니다.
AI 에이전트의 미래와 OAuth 진화 필요성
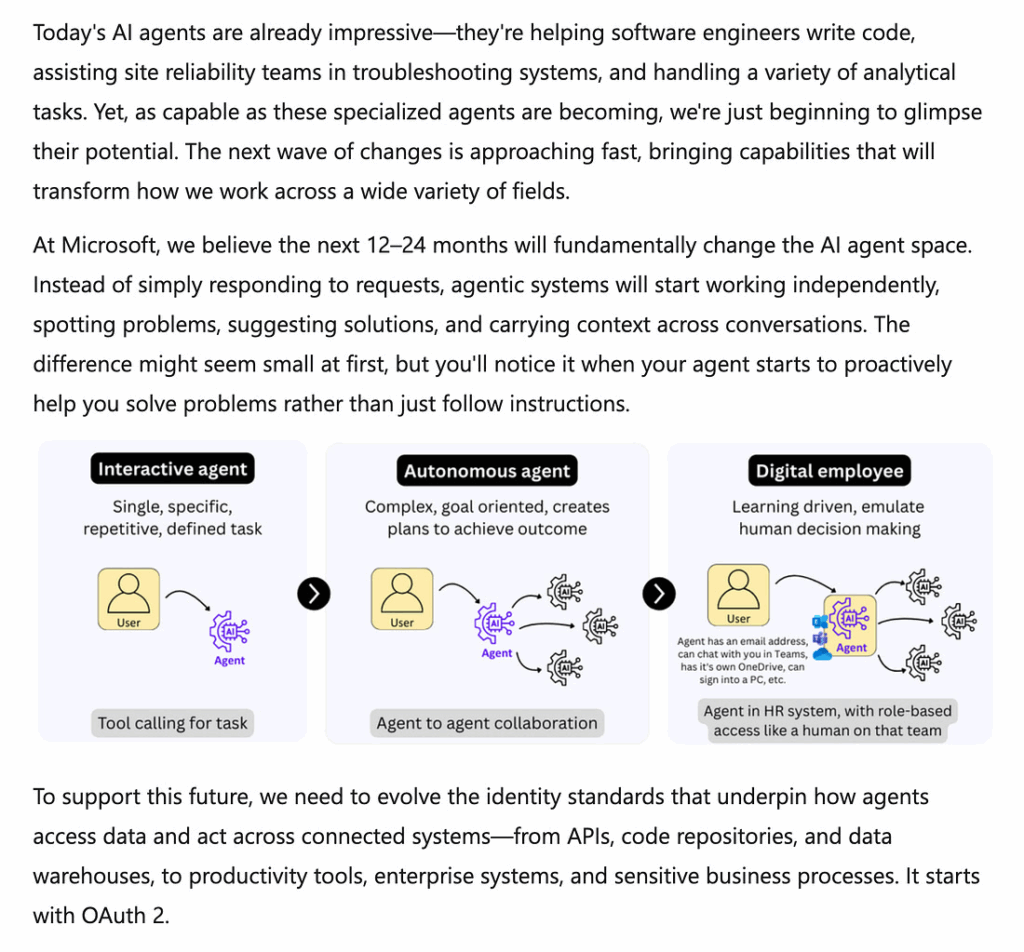
Microsoft는 AI 에이전트가 향후 12~24개월 내에 소프트웨어, 마케팅, 컴플라이언스, IT 운영의 핵심 요소가 될 것으로 전망합니다. 이를 지원하기 위해 OAuth 2.0의 진화가 필요하다고 제안했습니다.
👉 Microsoft Entra Blog
CloudNativePG Linux Foundation 멘토십
Carnegie Mellon University의 Ying Zhu가 PostgreSQL FDW의 선언적 관리 기능 개발을 위한 Linux Foundation 멘토십 프로그램에 선발되었습니다.
👉 프로그램 상세 보기
Ambience Healthcare의 AI 기반 의료 코딩 성능 27% 향상

Ambience Healthcare의 AI 모델이 ICD-10 의료 코딩에서 전문의보다 27% 높은 성과를 보였습니다. 이미 Cleveland Clinic과 UCSF에서 도입 중입니다.
👉 Ambience Healthcare 블로그
EDB 팀 소식
AI 시대의 데이터베이스
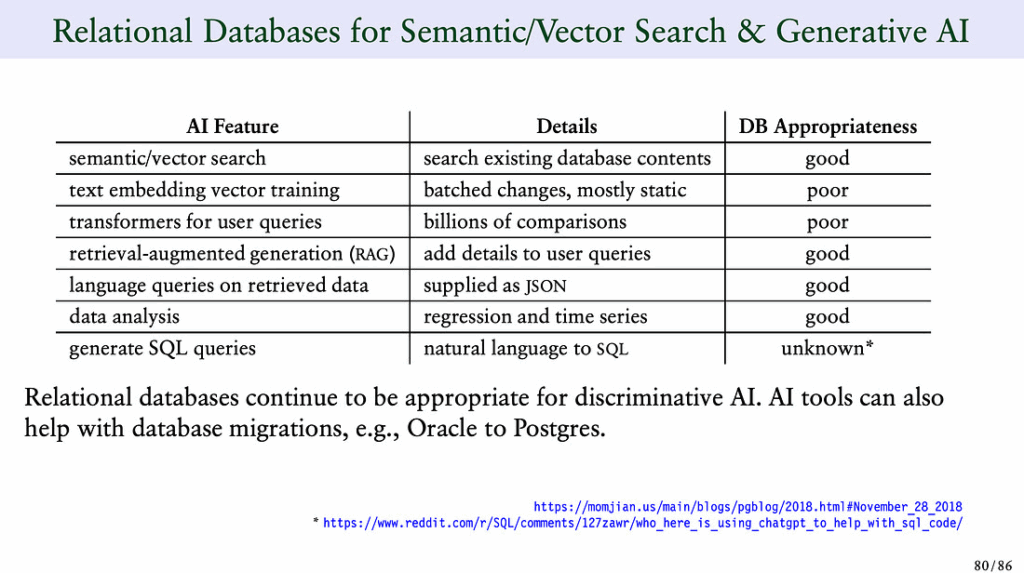
Bruce Momjian이 PgConf Nepal 2025에서 LLM과 PostgreSQL 통합에 대해 발표했습니다.
👉 발표 자료 보기
OpenTelemetry를 활용한 PostgreSQL 통합 모니터링
Yogesh Jain이 PostgreSQL 모니터링의 미래에 대해 발표했습니다.
CloudNativePG에서 PostgreSQL 확장 경험 개선
Gabriele Bartolini가 Kubernetes에서 PostgreSQL 확장 관리 경험에 대해 발표했습니다.
클라우드, Kubernetes, 베어 메탈 환경 — PostgreSQL는 다양한 환경에서 폭넓게 활용되고 있습니다.
그렇다면 이러한 다양한 환경에서 벤더 종속 없이, 또 높은 비용 없이, PostgreSQL를 어떻게 효율적으로 모니터링할 수 있을까요?
이번 세션에서는 OpenTelemetry를 활용해 PostgreSQL에 대해 **일관되고 확장 가능한 관찰 가능성(Observability)**을 구축하는 방법을 소개합니다. 어디서 실행되든 PostgreSQL를 효과적으로 모니터링할 수 있는 접근법을 다룹니다.
주요 내용은 다음과 같습니다:
- 메트릭과 로그 수집 방법
- 오픈소스 관찰 도구와의 통합 방법
- 성능과 비용 최적화를 위한 모니터링 전략
또한, 라이브 데모와 실전 인사이트도 함께 제공하여 PostgreSQL 모니터링을 보다 간단하고 효율적이며 미래 지향적으로 구현할 수 있는 방법을 보여드릴 예정입니다.
Postgres 메모리 누수 디버깅 – heaptrack 활용
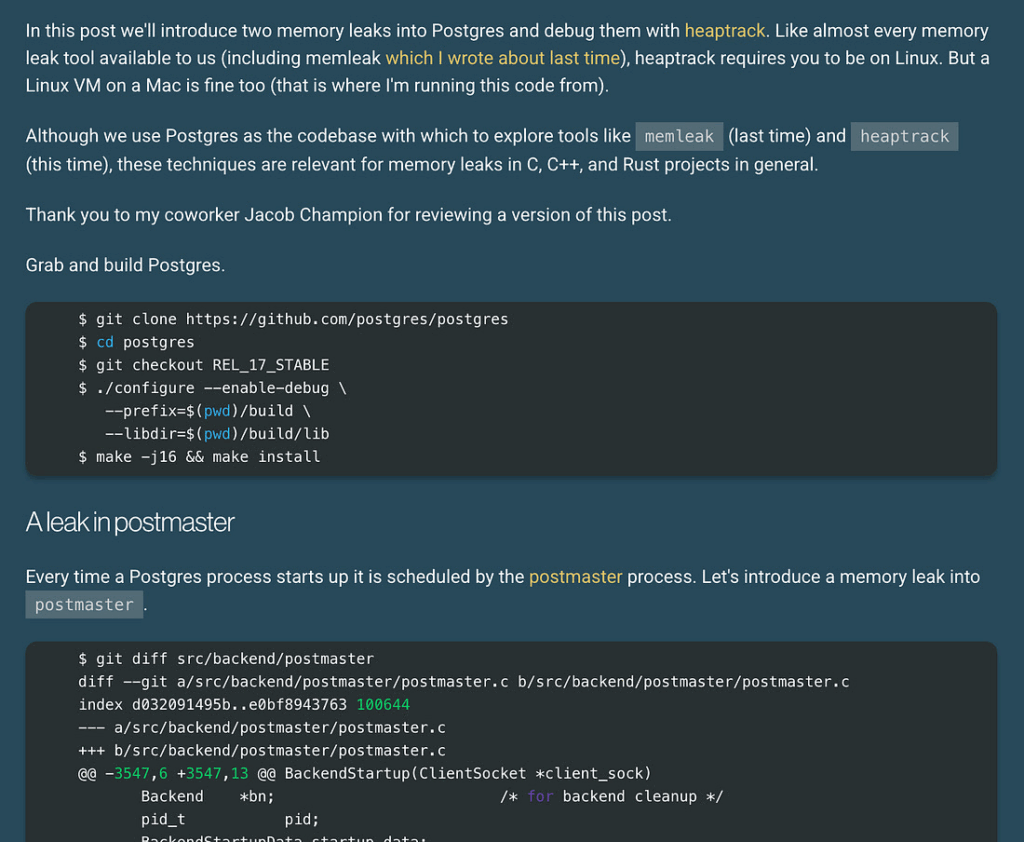
Phil Eaton이 heaptrack을 이용한 Postgres 메모리 누수 디버깅 방법을 소개했습니다.
👉 블로그 글 보기
절제된 코끼리(The Well-Tempered Elephant)
Gianni Ciolli가 음악 분석을 통해 PostgreSQL의 유연성과 기능을 보여주는 흥미로운 발표를 진행했습니다

.PostgreSQL은 확장 기능, 플러그인 언어, 사용자 정의 데이터 타입, 집계 함수 및 연산자 정의 등의 기능을 통해 다중 모드 DBMS로 진화해 왔습니다.
이 발표에서는 이러한 기능들을 활용하여 현실 세계의 잘 알려진 문제를 데이터 분석 과제로 프레이밍하고, PostgreSQL의 유연성과 강력함을 보여줍니다.
J.S. 바흐의 《평균율 클라비어곡집》 중 48개의 푸가를 음 하나하나 PostgreSQL 테이블에 저장한 뒤, PostgreSQL의 사용자 정의 객체(custom objects)를 활용하여 고전 음악의 섬세한 대위법(counterpoint)을 분석하는 방법을 소개합니다.
👉 발표 자료는 여기에서 확인하실 수 있습니다.
PostgreSQL 구성 파일 최적화 – Less is More
Lætitia Avrot가 postgresql.conf 파일을 깔끔하고 효율적으로 유지하는 방법에 대해 발표했습니다.

복잡한 PostgreSQL 설정 파일(postgresql.conf)은 언제든 문제를 일으킬 수 있는 시한폭탄과 같습니다.
중복된 설정, 불필요한 주석, 버전 관리 미비 등은 운영 이슈로 직결되며, 많은 시간을 낭비하게 만듭니다.
이 발표에서는 설정 파일을 간결하고 정돈되게 유지해야 하는 이유와 방법을 설명합니다.
기본값 제거, 중복 방지, include 파일 활용, Git을 통한 버전 관리 등의 실질적인 기법을 다루며,
마지막으로는 실제 운영 환경에서 사용할 수 있는 깔끔한 설정 예시를 소개합니다.
이러한 모범 사례들이 성능 향상, 가시성 개선, 문제 해결에 어떤 도움을 주는지도 함께 설명됩니다.
👉 발표 자료는 여기에서 확인하실 수 있습니다.
From Distance to Intelligence: 벡터 검색의 진화
Bilge Ince & Boriss Mejias가 PostgreSQL에서 벡터 검색을 고도화하는 방법에 대해 발표했습니다.
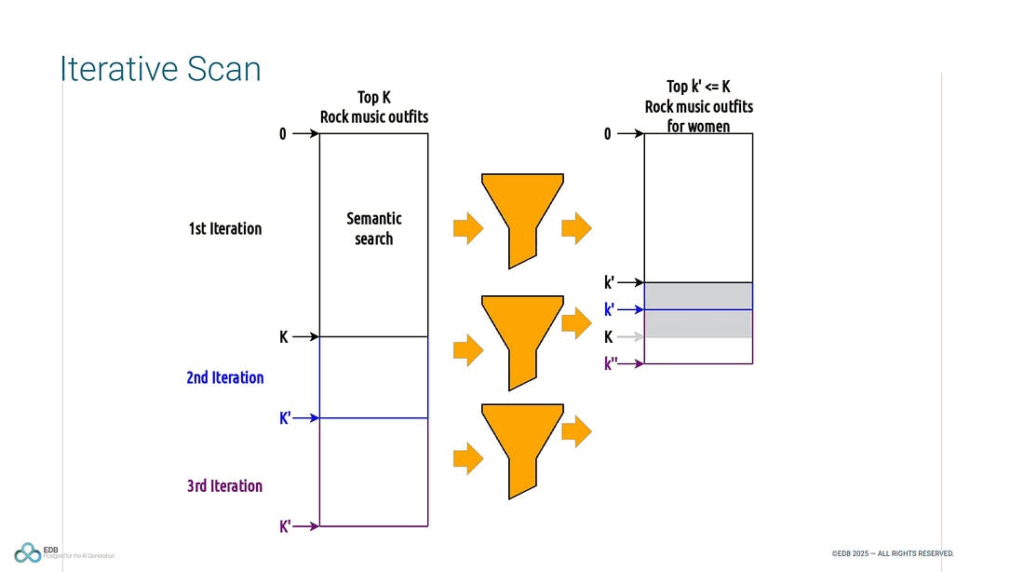
실제 운영 환경의 검색 요구사항은 단일 접근 방식으로 해결되지 않습니다.
전체 텍스트 검색은 정확한 키워드 일치에 강하지만 의미 파악은 약하고,
벡터 검색은 의미 기반 검색에는 뛰어나지만 정확한 일치나 정황상 우선순위 판단에는 약점이 있습니다.
PostgreSQL은 전체 텍스트 검색과 벡터 검색 모두를 지원하는 관계형 데이터베이스로,
두 방식을 조합해 보다 정교한 검색 시스템을 구현할 수 있는 유연함을 제공합니다.
이 발표에서는 단순한 벡터 검색을 넘어, 문맥 인지와 정확성을 겸비한 고급 검색 시스템을 어떻게 PostgreSQL에서 구현할 수 있는지 탐구합니다.
👉 발표 자료는 여기에서 확인하실 수 있습니다.
SLRU란 무엇인가?
Álvaro Herrera가 Postgres 17에서 변경된 SLRU 관리 방식과 구성 방법을 설명했습니다.

Postgres 17에는 중요한 성능 최적화 기능이 추가되면서 SLRU(Serializable Log Reusable Units)의 관리 및 구성 방식이 변경되었습니다.
그렇다면 SLRU는 정확히 무엇일까요?
무엇을 저장하는 구조일까요?
Postgres 17에서는 어떤 부분이 변경되었을까요?
현재는 어떻게 구성해야 할까요?
이번 발표에서는 이러한 질문들에 대해 자세히 설명합니다.
SLRU의 기본 개념부터 새로운 구성 방법까지 단계별로 알아볼 수 있는 유익한 세션이 될 것입니다.
👉 발표 자료는 여기에서 확인하실 수 있습니다.
PostgreSQL에서 최신 SSL 최적 활용법

Peter Eisentraut가 PGConf.DE 2025에서 발표한 내용입니다.
PostgreSQL의 SSL 지원은 오래된 기능이며, SSL 프로토콜 자체도 상당히 역사가 깊습니다. 그동안 새로운 버전들이 출시되고, 설정과 구성 방법도 많이 발전해왔습니다.
그와 동시에 여러 복잡한 규정, 법적 요구사항, 보안 기준들도 지속적으로 변화하고 있습니다.
이번 발표에서는 다음과 같은 내용을 다룹니다:
- PostgreSQL에서 SSL을 현대적이고 견고하게 구성하는 방법
- 어떤 버전과 옵션을 사용하는 것이 좋고, 어떤 것은 사용하지 않는 것이 좋은지
- **프로토콜과 암호화 방식(Cipher)**을 어떻게 선택할 것인지
- 키와 인증서 관리 방법
- 일부 규제 요건을 어떻게 다뤄야 하는지
- PgBouncer 같은 연결 프록시 및 풀러가 SSL 구성에 어떤 영향을 주는지
또한 PostgreSQL 17 및 18에서 새롭게 추가된 기능 중, 앞으로 SSL 사용을 보다 효율적이고 안전하게 개선할 수 있는 기능들도 함께 소개합니다.
👉 발표 자료는 여기에서 확인하실 수 있습니다.
PostgreSQL 확장 기능 활용하기: PostgreSQL Extensions의 세계
Devrim Gündüz가 PGConf.DE 2025에서 PostgreSQL 확장(Extensions)의 역사와 현재 개발 동향에 대해 발표했습니다.

이번 발표에서는 PostgreSQL 생태계에서 확장 기능이 어떻게 발전해왔는지, 그리고 오늘날 개발자들이 확장 기능을 어떻게 설계하고 구현하고 있는지에 대해 소개합니다.
👉 발표 자료는 여기에서 확인하실 수 있습니다.
Postgres에서의 메모리 관리 및 메모리 누수 문제 해결
Phil Eaton이 **Postgres Extensions Day (PGConf.dev 연계 행사)**에서 발표한 내용입니다.
이번 세션에서는 다음과 같은 내용을 다룹니다:
- MemoryContext 생성 및 전환 실전 활용 사례
- **Linux 도구(예: eBPF)**를 활용해 메모리 누수(memory leak)를 탐지하는 방법
- **프로덕션 환경의 PostgreSQL 확장(Extensions)**에서 실제로 발견된 메모리 관련 버그 사례
실제 현업 사례 중심으로, 메모리 관리 최적화 및 디버깅에 바로 활용할 수 있는 도구와 방법론을 소개합니다.
👉 발표 자료는 여기에서 확인하실 수 있습니다.
몬스터급 하드웨어 시대의 PostgreSQL 성능 재고(再考)
Lætitia Avrot가 PGConf.dev에서 발표한 내용입니다.

현재는 단일 서버에서도 수 TB의 메모리, 초고속 SSD, 수백 개의 CPU 스레드를 제공하는 시대입니다.
이런 환경에서 기존처럼 **수평 확장(horizontal scaling)**만을 고집하는 접근법은 점점 구식으로 느껴지곤 합니다.
“굳이 클러스터로 분산하지 않고 단일 고성능 서버로 충분히 처리할 수 있다면?” 이 질문에서 출발한 발표입니다.
이번 발표에서는:
- PostgreSQL가 현대 고성능 하드웨어를 어떻게 활용하는지
- 운영체제와의 상호작용
- 병렬 처리(Parallelism), 메모리 및 IO 처리 방식
- PostgreSQL를 수직 확장(vertical scaling) 전략으로 최적화하는 방법
실제 사례와 함께 현대 서버 환경에서 PostgreSQL 성능을 극대화하는 인사이트를 제공합니다.
👉 발표 자료는 여기에서 확인하실 수 있습니다.
C 및 POSIX 표준의 새로운 변화
Peter Eisentraut가 PGConf.dev에서 발표한 내용입니다.

C와 POSIX는 PostgreSQL가 기반하고 있는 핵심 프로그래밍 환경입니다.
속도는 느리지만 C 및 POSIX 표준도 진화하고 있으며, 2024년에는 새로운 C 표준과 POSIX 표준이 모두 발표되었습니다.
이번 발표에서는:
- C 및 POSIX 표준 개발 방식과 구현 현황
- 다양한 컴파일러 및 OS에서의 지원 상황
- PostgreSQL 개발에 새로운 표준 기능들이 어떻게 활용될 수 있는지
- 스레드 안전성(Thread-safety), 로케일 지원 개선, 타입 안전성(Type-safety), 코드 최적화 등 PostgreSQL 개발에 기여할 수 있는 방안을 논의합니다.
👉 발표 자료는 여기에서 확인하실 수 있습니다.
커미터 리뷰: ‘편집증’적 접근이 필요한 이유
Robert Haas가 PGConf.dev에서 발표한 내용입니다.

PostgreSQL 커뮤니티에서는 많은 분들이 패치를 리뷰하지만, 커미터(Committer) 리뷰는 특별한 의미를 갖습니다.
커미터만이 공식 PostgreSQL 소스 트리에 패치를 최종 반영할 수 있는 git push 권한을 갖고 있기 때문입니다.
이번 발표에서는:
- 커미터가 패치를 리뷰할 때 어떤 전략과 관점을 적용하는지
- 커미터마다 리뷰 방식이 어떻게 다른지
- 왜 커미터들이 겉보기에는 좋은 패치라도 신중하게 접근하는지에 대한 이유
👉 발표 자료는 여기에서 확인하실 수 있습니다.
Kubernetes 환경에서 CloudNativePG를 활용한 pgvector 시작하기
Gabriele Bartolini가 CloudNativePG에서 pgvector를 설정하고 사용하는 방법에 대한 튜토리얼을 작성했습니다.

👉 튜토리얼 보기
2025년 6월 PostgreSQL 해킹 워크숍
Robert Haas가 6월 PostgreSQL 해킹 워크숍을 진행할 예정입니다. 이번 워크숍에는 Masahiko Sawada가 함께 참여합니다.

다음 뉴스레터에서 만나요!
이번 호 EDB Engineering Newsletter를 재미있게 읽으셨기를 바랍니다.
PostgreSQL 개발에 직접 참여해보고 싶으시다면 PostgreSQL Hacker Mentoring Discord에도 참여해보세요!
EDB 엔지니어링 팀 드림
